The LectomeXplore database provides predicted lectin domains (reversible carbohydrate binding site) in all species proteomes (de novo translated genomes) available in UniProt and in the NCBI. To identify the lectin domains, LectomeXplore use UniLectin3D classes to generate conserved motifs of the lectin domains. A total of 107 lectin classes are available.
The following options for searching are available: 1. Keyword (sequence ID, name and annotation) 2. Lectin fold and class 3. Taxonomy (superkingdom, phylum and species) 4. Advanced search with multiple criteria 5. Domain architectures Once selected, lectins(and their features) can be explored by Accession Number (with the NCBI AC and UniProt AC).For each lectin a detailed panel and page are available with the NCBI gene viewer and a representation of the lectin domain conservation compared to the reference.
The search can be performed by entering keywords by textual input : i.e. salmonis, Microbacterium , B9ENV9(uniprot) ...

The predicted proteins matching the keyword(s) are listed and a link to a page with further detailed is available.
The search can be performed by selecting a lectin class.
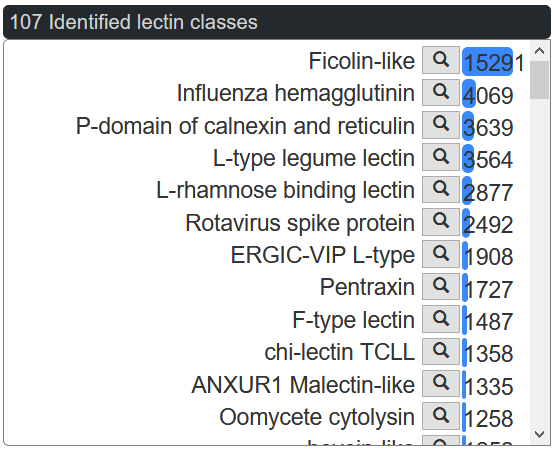
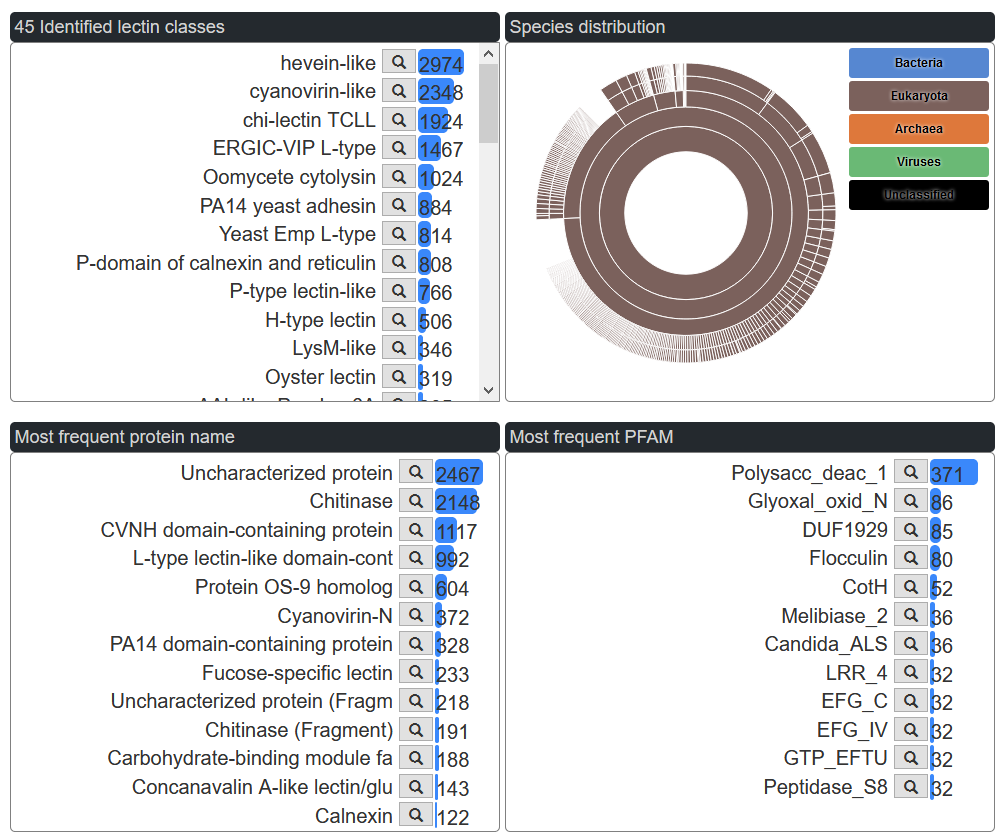
The barchart represent the distribution of the predicted lectins by lectin class. Each class can be clicked to explore the corresponding predicted lectins.
The search can be performed by selecting in the Taxonomy sunburst a superkingdom, kingdom, phylum, family, genus.
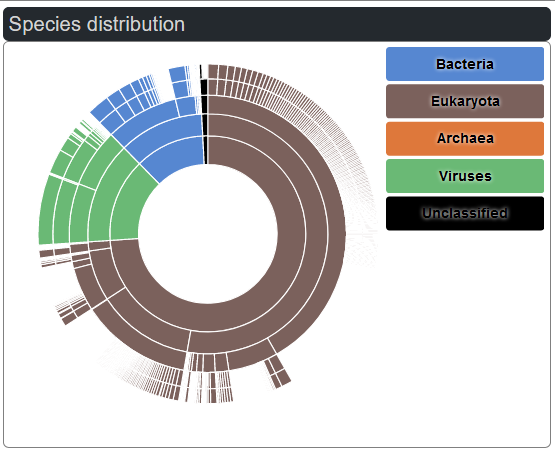
Predicted lectins species can be explored with the inner circle representing the superkingdom, the second circle the kingdom, the third circle the phylum, the fourth circle the species group. Each section can be clicked to get further details.
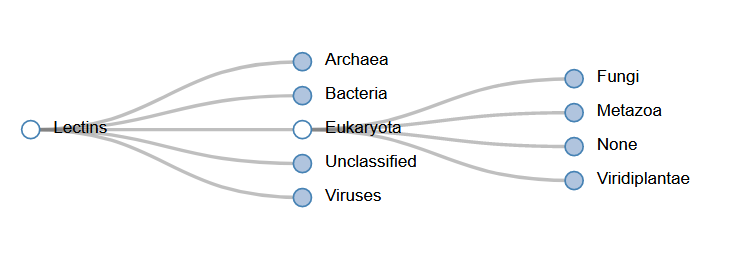
The tree viewer allows exploring the predicted lectins taxonomy with a better insight in less represented branches. The nodes can be opened to access in order the superkingdom, kingdom, phylum, species group, and species. Each node label can be clicked to access further details.
The search can be performed with multiple criteria on the advanced search page.
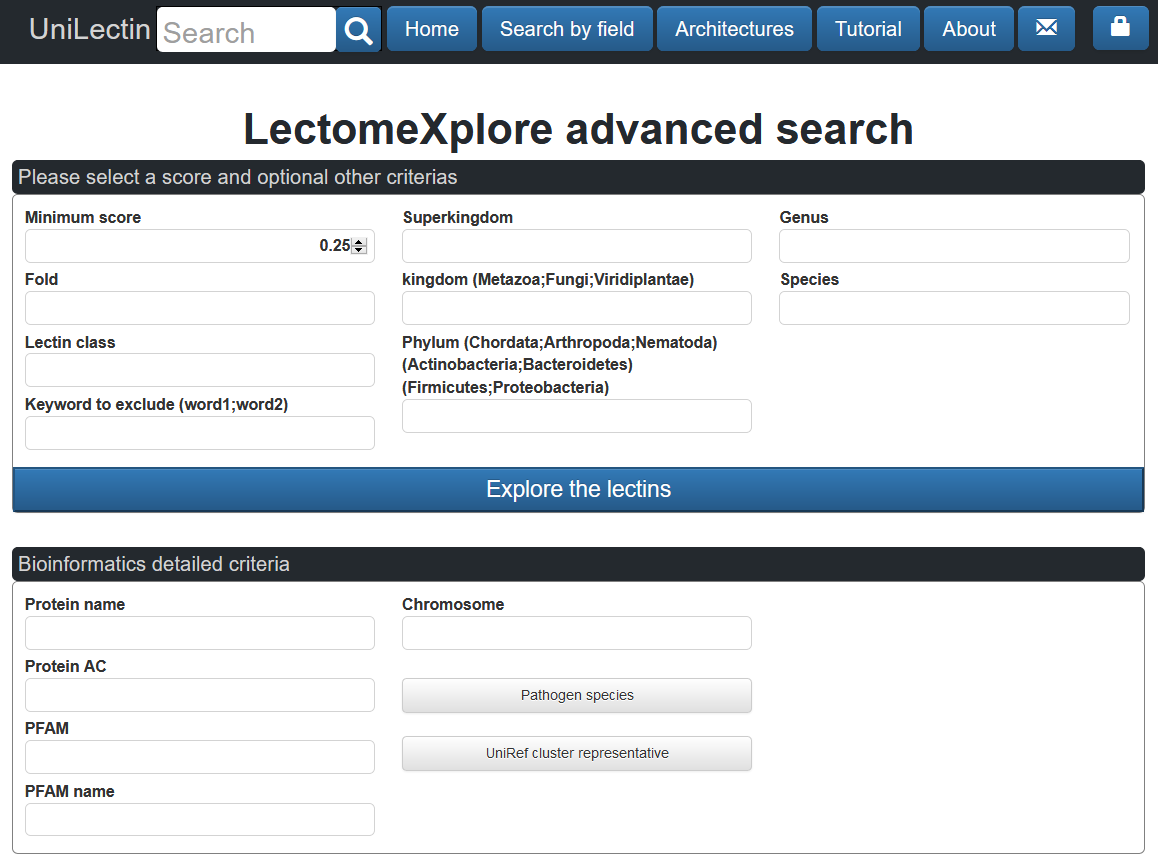
Predicted lectins can be explored based on selected criteria, ordered by scores. The score threshold by default is at 0.25 (25% of similarity to the reference); the lectin class identified, keywords to exclude proteins based on their description by default set with partial, synthetic and undefined keywords, taxonomy, PFAM domains, RefSeq AC, protein name and description (to include) and the UniProt AC.
The button checkbox pathogen species allows to keep only species contained in a predefined list of pathogene species (based on the NIH pathogen species list).
Graphics are generated to have an overview of the predicted lectins distribution, for the lectins corresponding to the criteria selected by the user. LectomeXplore families distribution, taxonomy sunburst and tree are available as in the homepage. The graphics can be clicked to access further details.
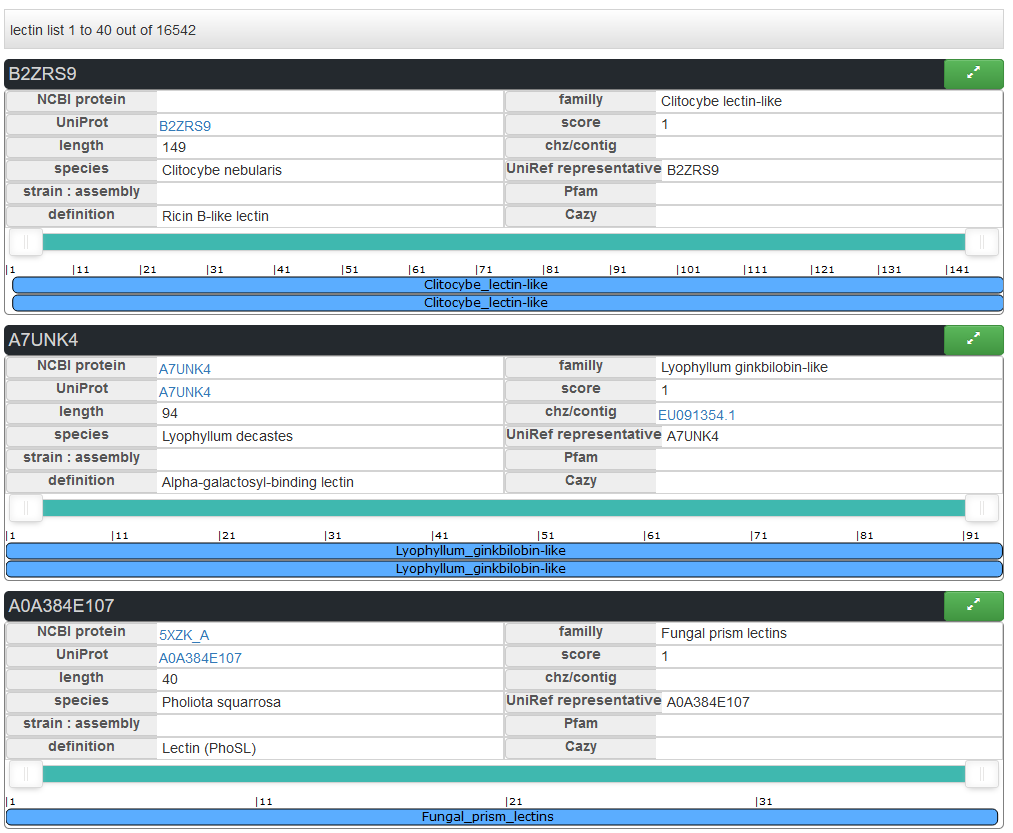
The predicted proteins matching the criteria are ordered by score with 20 results displayed by page. For each predicted lectins features are displayed with the protein name, UniProt AC and RefSeq AC which can be clicked to access the corresponding pages, length of the protein, species, the lectin class identified, the similarity score (against the reference), and the gene list with all chromosome and position encoding this protein. When multiple chromosomes are available they correspond to the different version of the chromosome encoding this exact protein.
For each predicted lectin a 2D sequence feature viewer allows visualizing the localization of the predicted domains and eventual PFAM domains, with a drag and drop button to zoom in the sequence. At the top, a button allows to display further details in a new window with the gene viewer and the domain conservation viewer.
For each lectins a detailed panel and page are available with the NCBI gene viewer and a representation of the domain conservation compared to the reference.
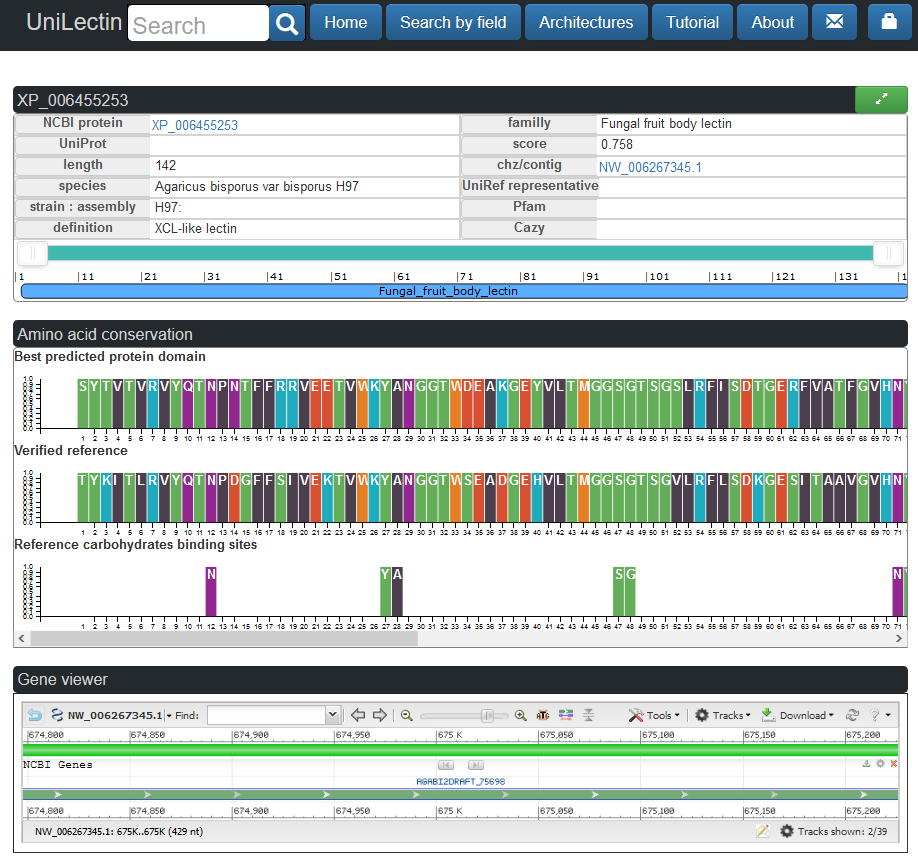
The protein features are described on the previous section. The protein encoding gene is represented on its chromozome by the ncbi viewer, when the information is available. The visualisation can be unzoomed and moved by drag and drop to check the surrounding genes information.
The best HMMER alignment is represented in two distinct barchart. The first barchart on top contains the reference consensus sequence of the domain. The second barchart represent the amino acid conservation of the reference domain.
The binding sites are represented below with the amino acids known to be used to bind a glycan either by a hydrogen bond or by hydrophobic interactions.
The predicted lectins can be explored by combination of domain(s) with one or more PFAM domains
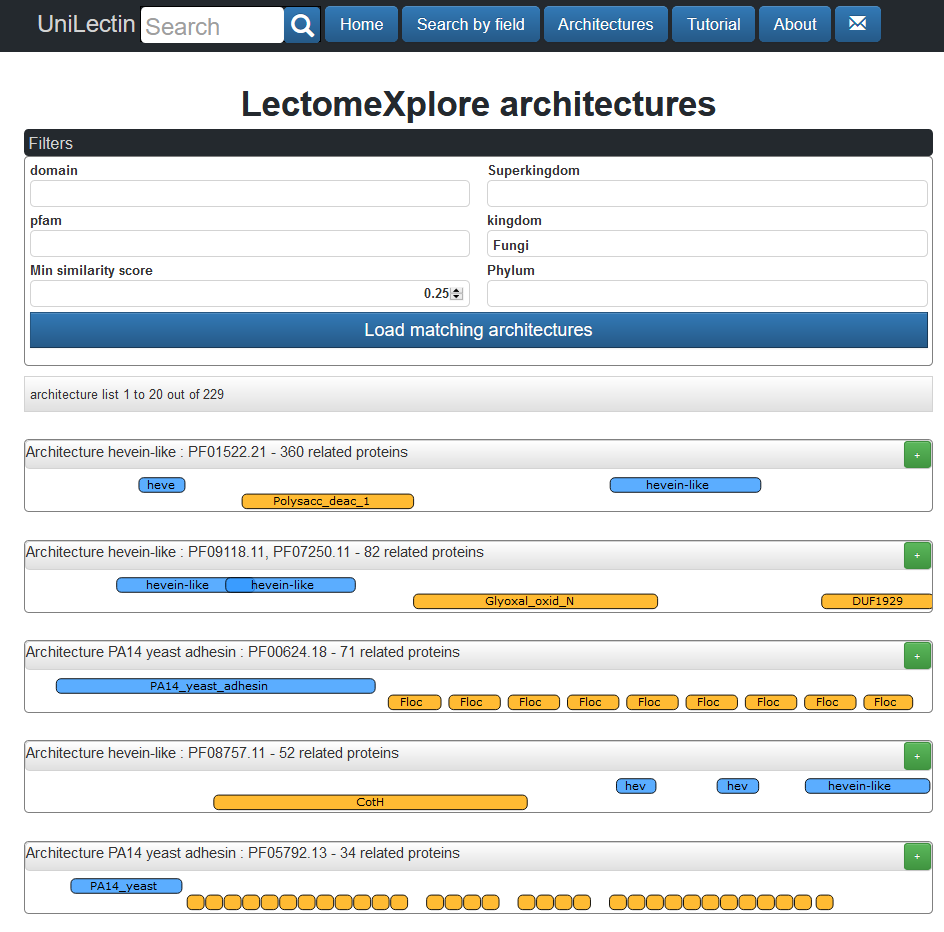
For each domain architecture a button allow to display the list of corresponding predicted lectins with the same pattern.