NCBI Summary
This gene encodes a member of the lectican family of chondroitin sulfate proteoglycans that is specifically expressed in the central nervous system. This protein is developmentally regulated and may function in the formation of the brain extracellular matrix. This protein is highly expressed in gliomas and may promote the growth and cell motility of brain tumor cells. Alternate splicing results in multiple transcript variants. [provided by RefSeq, Sep 2011].
Protein
Protein (NP_068767)
Brevican
Brevican core protein (Brain-enriched hyaluronan-binding protein) (BEHAB) (Chondroitin sulfate proteoglycan 7)
BCAN
brevican
Undefined
Curated
C-type lectin
Undefined
C-type - Proteoglycans or lecticans
a/b mixed / C-type lectin-like
MAQLFLPLLAALVLAQAPAALADVLEGDSSEDRAFRVRIAGDAPLQGVLGGALTIPCHVHYLRPPPSRRAVLGSPRVKWTFLSRGREAEVLVARGVRVKVNEAYRFRVALPAYPASLTDVSLALSELRPNDSGIYRCEVQHGIDDSSDAVEVKVKGVVFLYREGSARYAFSFSGAQEACARIGAHIATPEQLYAAYLGGYEQCDAGWLSDQTVRYPIQTPREACYGDMDGFPGVRNYGVVDPDDLYDVYCYAEDLNGELFLGDPPEKLTLEEARAYCQERGAEIATTGQLYAAWDGGLDHCSPGWLADGSVRYPIVTPSQRCGGGLPGVKTLFLFPNQTGFPNKHSRFNVYCFRDSAQPSAIPEASNPASNPASDGLEAIVTVTETLEELQLPQEATESESRGAIYSIPIMEDGGGGSSTPEDPAEAPRTLLEFETQSMVPPTGFSEEEGKALEEEEKYEDEEEKEEEEEEEEVEDEALWAWPSELSSPGPEASLPTEPAAQEESLSQAPARAVLQPGASPLPDGESEASRPPRVHGPPTETLPTPRERNLASPSPSTLVEAREVGEATGGPELSGVPRGESEETGSSEGAPSLLPATRAPEGTRELEAPSEDNSGRTAPAGTSVQAQPVLPTDSASRGGVAVVPASGDCVPSPCHNGGTCLEEEEGVRCLCLPGYGGDLCDVGLRFCNPGWDAFQGACYKHFSTRRSWEEAETQCRMYGAHLASISTPEEQDFINNRYREYQWIGLNDRTIEGDFLWSDGVPLLYENWNPGQPDSYFLSGENCVVMVWHDQGQWSDVPCNYHLSYTCKMGLVSCGPPPELPLAQVFGRPRLRYEVDTVLRYRCREGLAQRNLPLIRCQENGRWEAPQISCVPRRPARALHPEEDPEGRQGRLLGRWKALLIPPSSPMPGP
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
The location of the lectin domain structural model is: 686-813
We infer [1.4, 1.75] Å as the interval of error of this structural model.
Template 1: 6PWS chain: A, E1BIQ4, XP_005198961.1, sequence identity: 39.1%, coverage: 97.7%, location in sequence: 174-302, (162-290 in PDB).
Template 2: 3WHD chain: C, Q8WXI8, NP_525126.2, sequence identity: 39.1%, coverage: 98.4%, location in sequence: 63-215, (63-215 in PDB).
Template 3: 6PY1 chain: A, Q8IUN9, NP_878910.1, sequence identity: 36.7%, coverage: 96.1%, location in sequence: 179-308, (179-308 in PDB).
Show the alignment used for the construction of the structural model, Download.
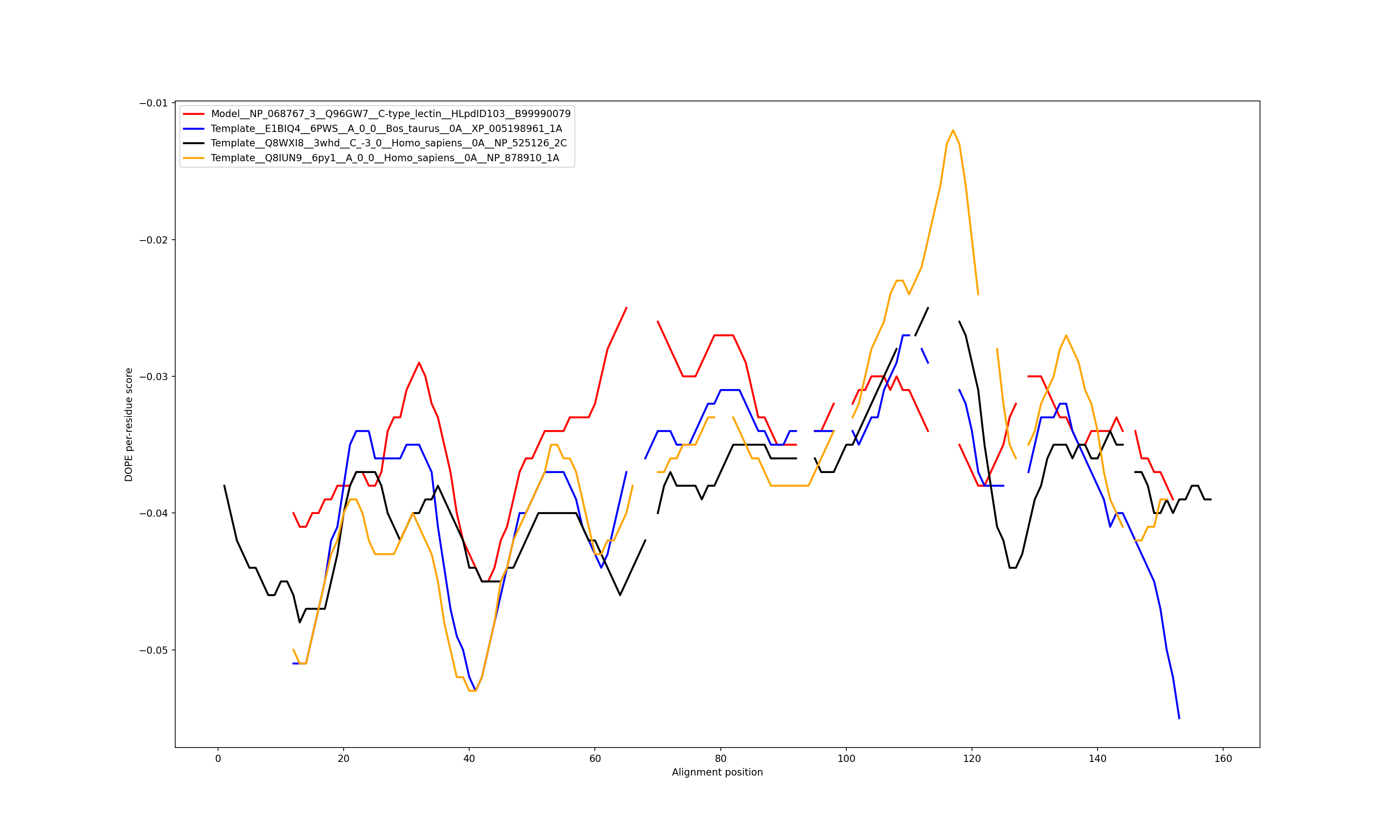
Show the plot of DOPE energy score, Download.
We infer [1.4, 1.75] Å as the interval of error of this structural model.
Template 1: 6PWS chain: A, E1BIQ4, XP_005198961.1, sequence identity: 39.1%, coverage: 97.7%, location in sequence: 174-302, (162-290 in PDB).
Template 2: 3WHD chain: C, Q8WXI8, NP_525126.2, sequence identity: 39.1%, coverage: 98.4%, location in sequence: 63-215, (63-215 in PDB).
Template 3: 6PY1 chain: A, Q8IUN9, NP_878910.1, sequence identity: 36.7%, coverage: 96.1%, location in sequence: 179-308, (179-308 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
Interacts with TNR
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- Interactome Mapping Provides a Network of Neurodegenerative Disease Proteins and Uncovers Widespread Protein Aggregation in Affected Brains. [32814053]
- The CNS-specific proteoglycan, brevican, and its ADAMTS4-cleaved fragment show differential serological levels in Alzheimer's disease, other types of dementia and non-demented controls: A cross-sectional study. [32559242]
- The Role of BEHAB/Brevican in the Tumor Microenvironment: Mediating Glioma Cell Invasion and Motility. [32845505]
- Genome-wide methylation screen in low-grade breast cancer identifies novel epigenetically altered genes as potential biomarkers for tumor diagnosis. [22930747]
- Brevican, neurocan, tenascin-C and versican are mainly responsible for the invasiveness of low-grade astrocytoma. [21997179]
- The proteoglycans aggrecan and Versican form networks with fibulin-2 through their lectin domain binding. [11038354]
- Brevican is degraded by matrix metalloproteinases and aggrecanase-1 (ADAMTS4) at different sites. [10986281]
- cDNA cloning, chromosomal localization, and expression analysis of human BEHAB/brevican, a brain specific proteoglycan regulated during cortical development and in glioma. [11054543]
- The C-type lectin domains of lecticans, a family of aggregating chondroitin sulfate proteoglycans, bind tenascin-R by protein-protein interactions independent of carbohydrate moiety. [9294172]
- Brevican, a chondroitin sulfate proteoglycan of rat brain, occurs as secreted and cell surface glycosylphosphatidylinositol-anchored isoforms. [7592978]
UniProt Main References (5 PubMed Identifiers)
- The secreted protein discovery initiative (SPDI), a large-scale effort to identify novel human secreted and transmembrane proteins: a bioinformatics assessment. [12975309]
- The DNA sequence and biological annotation of human chromosome 1. [16710414]
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
- Enrichment of glycopeptides for glycan structure and attachment site identification. [19838169]
- Extracellular matrix component expression in human pluripotent stem cell-derived retinal organoids recapitulates retinogenesis in vivo and reveals an important role for IMPG1 and CD44 in the development of photoreceptors and interphotoreceptor matrix. [29777959]
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_021948.5)
m7G-5')ppp(5'-CUCUUCCGAAUGUCCUGCGGCCCCAGCCUCUCCUCACGCUCGCGCAGUCUCCGCCGCAGUCUCAGCUGCAGCUGCAGGACUGAGCCGUGCACCCGGAGGAGACCCCCGGAGGAGGCGACAAACUUCGCAGUGCCGCGACCCAACCCCAGCCCUGGGUAGCCUGCAGCAUGGCCCAGCUGUUCCUGCCCCUGCUGGCAGCCCUGGUCCUGGCCCAGGCUCCUGCAGCUUUAGCAGAUGUUCUGGAAGGAGACAGCUCAGAGGACCGCGCUUUUCGCGUGCGCAUCGCGGGCGACGCGCCACUGCAGGGCGUGCUCGGCGGCGCCCUCACCAUCCCUUGCCACGUCCACUACCUGCGGCCACCGCCGAGCCGCCGGGCUGUGCUGGGCUCUCCGCGGGUCAAGUGGACUUUCCUGUCCCGGGGCCGGGAGGCAGAGGUGCUGGUGGCGCGGGGAGUGCGCGUCAAGGUGAACGAGGCCUACCGGUUCCGCGUGGCACUGCCUGCGUACCCAGCGUCGCUCACCGACGUCUCCCUGGCGCUGAGCGAGCUGCGCCCCAACGACUCAGGUAUCUAUCGCUGUGAGGUCCAGCACGGCAUCGAUGACAGCAGCGACGCUGUGGAGGUCAAGGUCAAAGGGGUCGUCUUUCUCUACCGAGAGGGCUCUGCCCGCUAUGCUUUCUCCUUUUCUGGGGCCCAGGAGGCCUGUGCCCGCAUUGGAGCCCACAUCGCCACCCCGGAGCAGCUCUAUGCCGCCUACCUUGGGGGCUAUGAGCAAUGUGAUGCUGGCUGGCUGUCGGAUCAGACCGUGAGGUAUCCCAUCCAGACCCCACGAGAGGCCUGUUACGGAGACAUGGAUGGCUUCCCCGGGGUCCGGAACUAUGGUGUGGUGGACCCGGAUGACCUCUAUGAUGUGUACUGUUAUGCUGAAGACCUAAAUGGAGAACUGUUCCUGGGUGACCCUCCAGAGAAGCUGACAUUGGAGGAAGCACGGGCGUACUGCCAGGAGCGGGGUGCAGAGAUUGCCACCACGGGCCAACUGUAUGCAGCCUGGGAUGGUGGCCUGGACCACUGCAGCCCAGGGUGGCUAGCUGAUGGCAGUGUGCGCUACCCCAUCGUCACACCCAGCCAGCGCUGUGGUGGGGGCUUGCCUGGUGUCAAGACUCUCUUCCUCUUCCCCAACCAGACUGGCUUCCCCAAUAAGCACAGCCGCUUCAACGUCUACUGCUUCCGAGACUCGGCCCAGCCUUCUGCCAUCCCUGAGGCCUCCAACCCAGCCUCCAACCCAGCCUCUGAUGGACUAGAGGCUAUCGUCACAGUGACAGAGACCCUGGAGGAACUGCAGCUGCCUCAGGAAGCCACAGAGAGUGAAUCCCGUGGGGCCAUCUACUCCAUCCCCAUCAUGGAGGACGGAGGAGGUGGAAGCUCCACUCCAGAAGACCCAGCAGAGGCCCCUAGGACGCUCCUAGAAUUUGAAACACAAUCCAUGGUACCGCCCACGGGGUUCUCAGAAGAGGAAGGUAAGGCAUUGGAGGAAGAAGAGAAAUAUGAAGAUGAAGAAGAGAAAGAGGAGGAAGAAGAAGAGGAGGAGGUGGAGGAUGAGGCUCUGUGGGCAUGGCCCAGCGAGCUCAGCAGCCCGGGCCCUGAGGCCUCUCUCCCCACUGAGCCAGCAGCCCAGGAGGAGUCACUCUCCCAGGCGCCAGCAAGGGCAGUCCUGCAGCCUGGUGCAUCACCACUUCCUGAUGGAGAGUCAGAAGCUUCCAGGCCUCCAAGGGUCCAUGGACCACCUACUGAGACUCUGCCCACUCCCAGGGAGAGGAACCUAGCAUCCCCAUCACCUUCCACUCUGGUUGAGGCAAGAGAGGUGGGGGAGGCAACUGGUGGUCCUGAGCUAUCUGGGGUCCCUCGAGGAGAGAGCGAGGAGACAGGAAGCUCCGAGGGUGCCCCUUCCCUGCUUCCAGCCACACGGGCCCCUGAGGGUACCAGGGAGCUGGAGGCCCCCUCUGAAGAUAAUUCUGGAAGAACUGCCCCAGCAGGGACCUCAGUGCAGGCCCAGCCAGUGCUGCCCACUGACAGCGCCAGCCGAGGUGGAGUGGCCGUGGUCCCCGCAUCAGGUGACUGUGUCCCCAGCCCCUGCCACAAUGGUGGGACAUGCUUGGAGGAGGAGGAAGGGGUCCGCUGCCUAUGUCUGCCUGGCUAUGGGGGGGACCUGUGCGAUGUUGGCCUCCGCUUCUGCAACCCCGGCUGGGACGCCUUCCAGGGCGCCUGCUACAAGCACUUUUCCACACGAAGGAGCUGGGAGGAGGCAGAGACCCAGUGCCGGAUGUACGGCGCGCAUCUGGCCAGCAUCAGCACACCCGAGGAACAGGACUUCAUCAACAACCGGUACCGGGAGUACCAGUGGAUCGGACUCAACGACAGGACCAUCGAAGGCGACUUCUUGUGGUCGGAUGGCGUCCCCCUGCUCUAUGAGAACUGGAACCCUGGGCAGCCUGACAGCUACUUCCUGUCUGGAGAGAACUGCGUGGUCAUGGUGUGGCAUGAUCAGGGACAAUGGAGUGACGUGCCCUGCAACUACCACCUGUCCUACACCUGCAAGAUGGGGCUGGUGUCCUGUGGGCCGCCACCGGAGCUGCCCCUGGCUCAAGUGUUCGGCCGCCCACGGCUGCGCUAUGAGGUGGACACUGUGCUUCGCUACCGGUGCCGGGAAGGACUGGCCCAGCGCAAUCUGCCGCUGAUCCGAUGCCAAGAGAACGGUCGUUGGGAGGCCCCCCAGAUCUCCUGUGUGCCCAGAAGACCUGCCCGAGCUCUGCACCCAGAGGAGGACCCAGAAGGACGUCAGGGGAGGCUACUGGGACGCUGGAAGGCGCUGUUGAUCCCCCCUUCCAGCCCCAUGCCAGGUCCCUAGGGGGCAAGGCCUUGAACACUGCCGGCCACAGCACUGCCCUGUCACCCAAAUUUUCCCUCACACCCUGCGCUCCCGCCACCACAGGAAGUGACAACAUGACGAGGGGUGGUACUGGAGUCCAGGUGACAGUUCCUGAAGGGGCUUCUGGGAAAUACCUAGGAGGCUCCAGCCCAGCCCAGGCCCUCUCCCCCUACCCUGGGCACCAGAUCUUCCAUCAGGGCCGGAGUAAAUCCCUAAGUGCCUCAACUGCCCUCUCCCUGGCAGCCAUCUUGUCCCCUCUAUUCCUCUAGGGAGCACUGUGCCCACUCUUUCUGGGUUUUCCAAGGGAAUGGGCUUGCAGGAUGGAGUGUCUGUAAAAUCAACAGGAAAUAAAACUGUGUAUGAGCCCAGGCAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 63827)
brevican
strand +
BEHAB, MGC13038, CSPG7
NCBI CDS gene sequence (2736 bp)
5'-ATGGCCCAGCTGTTCCTGCCCCTGCTGGCAGCCCTGGTCCTGGCCCAGGCTCCTGCAGCTTTAGCAGATGTTCTGGAAGGAGACAGCTCAGAGGACCGCGCTTTTCGCGTGCGCATCGCGGGCGACGCGCCACTGCAGGGCGTGCTCGGCGGCGCCCTCACCATCCCTTGCCACGTCCACTACCTGCGGCCACCGCCGAGCCGCCGGGCTGTGCTGGGCTCTCCGCGGGTCAAGTGGACTTTCCTGTCCCGGGGCCGGGAGGCAGAGGTGCTGGTGGCGCGGGGAGTGCGCGTCAAGGTGAACGAGGCCTACCGGTTCCGCGTGGCACTGCCTGCGTACCCAGCGTCGCTCACCGACGTCTCCCTGGCGCTGAGCGAGCTGCGCCCCAACGACTCAGGTATCTATCGCTGTGAGGTCCAGCACGGCATCGATGACAGCAGCGACGCTGTGGAGGTCAAGGTCAAAGGGGTCGTCTTTCTCTACCGAGAGGGCTCTGCCCGCTATGCTTTCTCCTTTTCTGGGGCCCAGGAGGCCTGTGCCCGCATTGGAGCCCACATCGCCACCCCGGAGCAGCTCTATGCCGCCTACCTTGGGGGCTATGAGCAATGTGATGCTGGCTGGCTGTCGGATCAGACCGTGAGGTATCCCATCCAGACCCCACGAGAGGCCTGTTACGGAGACATGGATGGCTTCCCCGGGGTCCGGAACTATGGTGTGGTGGACCCGGATGACCTCTATGATGTGTACTGTTATGCTGAAGACCTAAATGGAGAACTGTTCCTGGGTGACCCTCCAGAGAAGCTGACATTGGAGGAAGCACGGGCGTACTGCCAGGAGCGGGGTGCAGAGATTGCCACCACGGGCCAACTGTATGCAGCCTGGGATGGTGGCCTGGACCACTGCAGCCCAGGGTGGCTAGCTGATGGCAGTGTGCGCTACCCCATCGTCACACCCAGCCAGCGCTGTGGTGGGGGCTTGCCTGGTGTCAAGACTCTCTTCCTCTTCCCCAACCAGACTGGCTTCCCCAATAAGCACAGCCGCTTCAACGTCTACTGCTTCCGAGACTCGGCCCAGCCTTCTGCCATCCCTGAGGCCTCCAACCCAGCCTCCAACCCAGCCTCTGATGGACTAGAGGCTATCGTCACAGTGACAGAGACCCTGGAGGAACTGCAGCTGCCTCAGGAAGCCACAGAGAGTGAATCCCGTGGGGCCATCTACTCCATCCCCATCATGGAGGACGGAGGAGGTGGAAGCTCCACTCCAGAAGACCCAGCAGAGGCCCCTAGGACGCTCCTAGAATTTGAAACACAATCCATGGTACCGCCCACGGGGTTCTCAGAAGAGGAAGGTAAGGCATTGGAGGAAGAAGAGAAATATGAAGATGAAGAAGAGAAAGAGGAGGAAGAAGAAGAGGAGGAGGTGGAGGATGAGGCTCTGTGGGCATGGCCCAGCGAGCTCAGCAGCCCGGGCCCTGAGGCCTCTCTCCCCACTGAGCCAGCAGCCCAGGAGGAGTCACTCTCCCAGGCGCCAGCAAGGGCAGTCCTGCAGCCTGGTGCATCACCACTTCCTGATGGAGAGTCAGAAGCTTCCAGGCCTCCAAGGGTCCATGGACCACCTACTGAGACTCTGCCCACTCCCAGGGAGAGGAACCTAGCATCCCCATCACCTTCCACTCTGGTTGAGGCAAGAGAGGTGGGGGAGGCAACTGGTGGTCCTGAGCTATCTGGGGTCCCTCGAGGAGAGAGCGAGGAGACAGGAAGCTCCGAGGGTGCCCCTTCCCTGCTTCCAGCCACACGGGCCCCTGAGGGTACCAGGGAGCTGGAGGCCCCCTCTGAAGATAATTCTGGAAGAACTGCCCCAGCAGGGACCTCAGTGCAGGCCCAGCCAGTGCTGCCCACTGACAGCGCCAGCCGAGGTGGAGTGGCCGTGGTCCCCGCATCAGGTGACTGTGTCCCCAGCCCCTGCCACAATGGTGGGACATGCTTGGAGGAGGAGGAAGGGGTCCGCTGCCTATGTCTGCCTGGCTATGGGGGGGACCTGTGCGATGTTGGCCTCCGCTTCTGCAACCCCGGCTGGGACGCCTTCCAGGGCGCCTGCTACAAGCACTTTTCCACACGAAGGAGCTGGGAGGAGGCAGAGACCCAGTGCCGGATGTACGGCGCGCATCTGGCCAGCATCAGCACACCCGAGGAACAGGACTTCATCAACAACCGGTACCGGGAGTACCAGTGGATCGGACTCAACGACAGGACCATCGAAGGCGACTTCTTGTGGTCGGATGGCGTCCCCCTGCTCTATGAGAACTGGAACCCTGGGCAGCCTGACAGCTACTTCCTGTCTGGAGAGAACTGCGTGGTCATGGTGTGGCATGATCAGGGACAATGGAGTGACGTGCCCTGCAACTACCACCTGTCCTACACCTGCAAGATGGGGCTGGTGTCCTGTGGGCCGCCACCGGAGCTGCCCCTGGCTCAAGTGTTCGGCCGCCCACGGCTGCGCTATGAGGTGGACACTGTGCTTCGCTACCGGTGCCGGGAAGGACTGGCCCAGCGCAATCTGCCGCTGATCCGATGCCAAGAGAACGGTCGTTGGGAGGCCCCCCAGATCTCCTGTGTGCCCAGAAGACCTGCCCGAGCTCTGCACCCAGAGGAGGACCCAGAAGGACGTCAGGGGAGGCTACTGGGACGCTGGAAGGCGCTGTTGATCCCCCCTTCCAGCCCCATGCCAGGTCCCTAG-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.