NCBI Summary
Neurocan is a chondroitin sulfate proteoglycan thought to be involved in the modulation of cell adhesion and migration.[supplied by OMIM, Jul 2002].
Protein
Protein (NP_004377)
Neurocan
Neurocan core protein (Chondroitin sulfate proteoglycan 3)
NCAN
neurocan
Undefined
Curated
C-type lectin
Undefined
C-type - Proteoglycans or lecticans
a/b mixed / C-type lectin-like
MGAPFVWALGLLMLQMLLFVAGEQGTQDITDASERGLHMQKLGSGSVQAALAELVALPCLFTLQPRPSAARDAPRIKWTKVRTASGQRQDLPILVAKDNVVRVAKSWQGRVSLPSYPRRRANATLLLGPLRASDSGLYRCQVVRGIEDEQDLVPLEVTGVVFHYRSARDRYALTFAEAQEACRLSSAIIAAPRHLQAAFEDGFDNCDAGWLSDRTVRYPITQSRPGCYGDRSSLPGVRSYGRRNPQELYDVYCFARELGGEVFYVGPARRLTLAGARAQCRRQGAALASVGQLHLAWHEGLDQCDPGWLADGSVRYPIQTPRRRCGGPAPGVRTVYRFANRTGFPSPAERFDAYCFRAHHPTSQHGDLETPSSGDEGEILSAEGPPVRELEPTLEEEEVVTPDFQEPLVSSGEEETLILEEKQESQQTLSPTPGDPMLASWPTGEVWLSTVAPSPSDMGAGTAASSHTEVAPTDPMPRRRGRFKGLNGRYFQQQEPEPGLQGGMEASAQPPTSEAAVNQMEPPLAMAVTEMLGSGQSRSPWADLTNEVDMPGAGSAGGKSSPEPWLWPPTMVPPSISGHSRAPVLELEKAEGPSARPATPDLFWSPLEATVSAPSPAPWEAFPVATSPDLPMMAMLRGPKEWMLPHPTPISTEANRVEAHGEATATAPPSPAAETKVYSLPLSLTPTGQGGEAMPTTPESPRADFRETGETSPAQVNKAEHSSSSPWPSVNRNVAVGFVPTETATEPTGLRGIPGSESGVFDTAESPTSGLQATVDEVQDPWPSVYSKGLDASSPSAPLGSPGVFLVPKVTPNLEPWVATDEGPTVNPMDSTVTPAPSDASGIWEPGSQVFEEAESTTLSPQVALDTSIVTPLTTLEQGDKVGVPAMSTLGSSSSQPHPEPEDQVETQGTSGASVPPHQSSPLGKPAVPPGTPTAASVGESASVSSGEPTVPWDPSSTLLPVTLGIEDFELEVLAGSPGVESFWEEVASGEEPALPGTPMNAGAEEVHSDPCENNPCLHGGTCNANGTMYGCSCDQGFAGENCEIDIDDCLCSPCENGGTCIDEVNGFVCLCLPSYGGSFCEKDTEGCDRGWHKFQGHCYRYFAHRRAWEDAEKDCRRRSGHLTSVHSPEEHSFINSFGHENTWIGLNDRIVERDFQWTDNTGLQFENWRENQPDNFFAGGEDCVVMVAHESGRWNDVPCNYNLPYVCKKGTVLCGPPPAVENASLIGARKAKYNVHATVRYQCNEGFAQHHVATIRCRSNGKWDRPQIVCTKPRRSHRMRRHHHHHQHHHQHHHHKSRKERRKHKKHPTEDWEKDEGNFC
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
The location of the lectin domain structural model is: 1084-1213
We infer [1.44, 1.81] Å as the interval of error of this structural model.
Template 1: 6JJJ chain: A, P70194, NP_058031.2, sequence identity: 36.2%, coverage: 96.9%, location in sequence: 393-543, (393-543 in PDB).
Template 2: 6PWS chain: A, E1BIQ4, XP_005198961.1, sequence identity: 35.4%, coverage: 96.9%, location in sequence: 174-302, (162-290 in PDB).
Template 3: 6YAU chain: A, P07306, NP_001662.1, sequence identity: 35.4%, coverage: 93.8%, location in sequence: 153-281, (152-280 in PDB).
Show the alignment used for the construction of the structural model, Download.
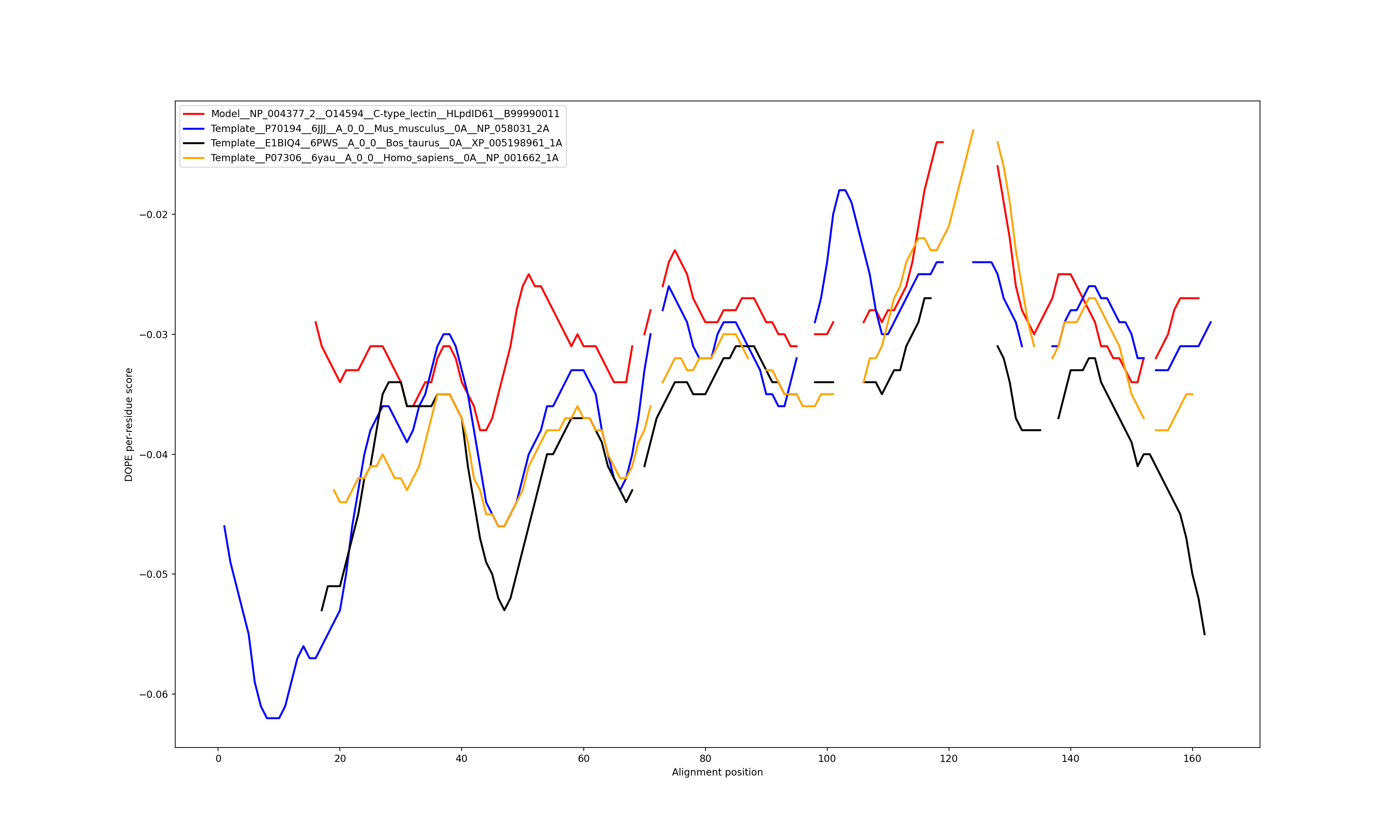
Show the plot of DOPE energy score, Download.
We infer [1.44, 1.81] Å as the interval of error of this structural model.
Template 1: 6JJJ chain: A, P70194, NP_058031.2, sequence identity: 36.2%, coverage: 96.9%, location in sequence: 393-543, (393-543 in PDB).
Template 2: 6PWS chain: A, E1BIQ4, XP_005198961.1, sequence identity: 35.4%, coverage: 96.9%, location in sequence: 174-302, (162-290 in PDB).
Template 3: 6YAU chain: A, P07306, NP_001662.1, sequence identity: 35.4%, coverage: 93.8%, location in sequence: 153-281, (152-280 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- Neurocan genome-wide psychiatric risk variant affects explicit memory performance and hippocampal function in healthy humans. [32583466]
- Role of NCAN rs2228603 polymorphism in the incidence of nonalcoholic fatty liver disease: a case-control study. [27887608]
- Replication analysis of genetic association of the NCAN-CILP2 region with plasma lipid levels and non-alcoholic fatty liver disease in Asian and Pacific ethnic groups. [26758378]
- NCAN Cross-Disorder Risk Variant Is Associated With Limbic Gray Matter Deficits in Healthy Subjects and Major Depression. [25801500]
- A genome-wide supported psychiatric risk variant in NCAN influences brain function and cognitive performance in healthy subjects. [25220293]
- Analysis of neurocan structures interacting with the neural cell adhesion molecule N-CAM. [8910306]
- TAG-1/axonin-1 is a high-affinity ligand of neurocan, phosphacan/protein-tyrosine phosphatase-zeta/beta, and N-CAM. [8663515]
- Structure and chromosomal localization of the mouse neurocan gene. [7490074]
- The neuronal chondroitin sulfate proteoglycan neurocan binds to the neural cell adhesion molecules Ng-CAM/L1/NILE and N-CAM, and inhibits neuronal adhesion and neurite outgrowth. [7513709]
- Cloning and primary structure of neurocan, a developmentally regulated, aggregating chondroitin sulfate proteoglycan of brain. [1326557]
UniProt Main References (3 PubMed Identifiers)
- Characterization of the human neurocan gene, CSPG3. [9795216]
- The DNA sequence and biology of human chromosome 19. [15057824]
- LC-MS/MS characterization of O-glycosylation sites and glycan structures of human cerebrospinal fluid glycoproteins. [23234360]
RNA
RNA (Transcript ID: NM_004386.3)
m7G-5')ppp(5'-GGAGCGCAGGGCGCAGGGGCUGGACCCGGCGCGGAGCUGGCUGAGUCGGAGCGCAGCGUCCUUUGUGCCCGGCGGCCGCCCCGGGAUGCGUCCGAGCUAGGAGCCAGAUCCAGGAUGGGGGCCCCGUUUGUCUGGGCCUUGGGCCUUUUGAUGCUGCAGAUGCUGCUCUUUGUGGCUGGGGAACAGGGCACACAGGAUAUCACCGAUGCCAGCGAAAGGGGGCUCCACAUGCAGAAGCUGGGGUCUGGGUCAGUGCAGGCUGCGCUGGCGGAGCUGGUGGCCCUGCCCUGUCUCUUUACCCUGCAGCCACGGCCAAGCGCAGCCCGAGAUGCCCCUCGGAUAAAGUGGACCAAGGUGCGGACUGCGUCGGGCCAGCGACAGGACUUGCCCAUCCUGGUGGCCAAGGACAAUGUCGUGAGGGUGGCCAAAAGCUGGCAGGGACGAGUGUCACUGCCUUCCUACCCCCGGCGCCGAGCCAACGCCACGCUACUUCUGGGGCCACUGAGGGCCAGUGACUCUGGGCUGUACCGCUGCCAGGUGGUGAGGGGCAUCGAGGAUGAGCAGGACCUGGUGCCCUUGGAGGUGACAGGUGUUGUGUUCCACUACCGAUCAGCCCGGGACCGCUAUGCACUGACCUUCGCUGAGGCCCAGGAGGCCUGCCGUCUCAGCUCAGCCAUCAUUGCAGCCCCUCGGCAUCUACAGGCUGCCUUUGAGGAUGGCUUUGACAACUGUGAUGCUGGCUGGCUCUCUGACCGCACUGUUCGGUAUCCUAUCACCCAGUCCCGUCCUGGUUGCUAUGGCGACCGUAGCAGCCUUCCAGGGGUUCGGAGCUAUGGGAGGCGCAACCCACAGGAACUCUACGAUGUGUAUUGCUUUGCCCGGGAGCUGGGGGGCGAGGUCUUCUACGUGGGCCCGGCCCGCCGCCUGACACUGGCCGGCGCGCGUGCACAGUGCCGCCGCCAGGGUGCCGCGCUGGCCUCGGUGGGACAGCUGCACCUGGCCUGGCAUGAGGGCCUGGACCAGUGCGACCCGGGCUGGCUGGCCGACGGCAGCGUGCGCUACCCGAUCCAGACGCCGCGCCGGCGCUGCGGGGGCCCAGCCCCGGGCGUGCGCACCGUCUACCGCUUCGCUAACCGGACCGGCUUCCCCUCACCCGCCGAGCGCUUCGACGCCUACUGCUUCCGAGCUCAUCACCCCACGUCACAACAUGGAGACCUAGAGACCCCAUCCUCUGGGGAUGAGGGGGAGAUUCUGUCAGCAGAGGGGCCCCCAGUUAGAGAACUGGAGCCCACCCUGGAGGAGGAAGAGGUGGUCACCCCUGACUUCCAGGAGCCUCUGGUGUCCAGUGGGGAAGAAGAAACCCUGAUUUUGGAGGAGAAGCAGGAGUCUCAACAGACCCUCAGCCCUACCCCUGGGGACCCCAUGCUGGCCUCAUGGCCCACUGGGGAAGUGUGGCUAAGCACGGUGGCCCCCAGCCCUAGCGACAUGGGGGCAGGCACUGCAGCAAGUUCACACACGGAGGUGGCCCCAACUGACCCUAUGCCUAGGAGAAGGGGGCGCUUCAAAGGGUUGAAUGGGCGCUACUUCCAGCAGCAGGAACCGGAGCCGGGGCUGCAAGGGGGGAUGGAGGCCAGCGCCCAGCCCCCCACCUCAGAGGCUGCAGUGAACCAAAUGGAGCCUCCGUUGGCCAUGGCAGUCACAGAGAUGUUGGGCAGUGGCCAGAGCCGGAGCCCCUGGGCUGAUCUGACCAAUGAGGUGGAUAUGCCUGGAGCUGGUUCUGCUGGUGGCAAGAGCUCCCCAGAGCCCUGGCUGUGGCCCCCUACCAUGGUCCCACCCAGCAUCUCAGGCCACAGCAGGGCCCCUGUCCUGGAGCUAGAGAAAGCCGAGGGCCCCAGUGCCAGGCCAGCCACCCCAGACCUGUUUUGGUCCCCCUUGGAGGCCACUGUCUCAGCUCCCAGCCCUGCCCCCUGGGAGGCAUUCCCUGUGGCCACCUCCCCAGAUCUCCCUAUGAUGGCCAUGCUGCGUGGUCCCAAAGAGUGGAUGCUACCACACCCCACCCCCAUCUCCACCGAGGCCAAUAGAGUUGAGGCACAUGGUGAGGCCACCGCCACGGCUCCACCCUCCCCUGCUGCAGAGACCAAGGUGUAUUCCCUGCCUCUCUCUUUGACCCCAACAGGACAGGGUGGAGAGGCCAUGCCCACAACACCUGAGUCCCCCAGGGCAGACUUCAGAGAAACUGGGGAGACCAGCCCUGCUCAGGUCAACAAAGCUGAGCACUCCAGCUCCAGCCCAUGGCCUUCUGUAAACAGGAAUGUGGCUGUAGGUUUUGUCCCCACUGAGACUGCCACUGAGCCAACGGGCCUCAGGGGUAUCCCGGGGUCUGAGUCUGGGGUCUUCGACACAGCAGAAAGCCCCACUUCUGGCUUGCAGGCCACUGUAGAUGAGGUGCAGGACCCCUGGCCCUCAGUGUACAGCAAAGGGCUGGAUGCAAGUUCCCCAUCUGCCCCCCUGGGGAGCCCUGGAGUCUUCUUGGUACCCAAAGUCACCCCAAAUUUGGAGCCUUGGGUUGCUACAGAUGAAGGACCCACUGUGAAUCCCAUGGAUUCCACAGUCACGCCGGCCCCCAGUGAUGCUAGUGGAAUUUGGGAACCUGGAUCCCAGGUGUUUGAAGAAGCCGAAAGCACCACCUUGAGCCCUCAGGUGGCCCUGGAUACAAGCAUUGUGACGCCCCUCACGACCCUGGAGCAGGGGGACAAGGUUGGAGUUCCAGCCAUGUCUACACUGGGCUCCUCAAGCUCCCAACCCCACCCAGAGCCAGAGGAUCAGGUGGAGACCCAGGGAACAUCAGGAGCUUCAGUGCCUCCGCAUCAGAGCAGUCCCCUAGGGAAACCGGCUGUUCCUCCUGGGACACCGACUGCAGCCAGUGUGGGCGAGUCUGCCUCAGUUUCCUCAGGGGAGCCUACGGUACCGUGGGACCCCUCCAGCACCCUGCUGCCUGUCACCCUGGGCAUAGAGGACUUCGAACUGGAGGUCCUGGCAGGGAGCCCGGGUGUAGAGAGCUUCUGGGAGGAGGUGGCAAGUGGAGAGGAGCCAGCCCUGCCAGGGACCCCUAUGAAUGCAGGUGCGGAGGAGGUGCACUCAGAUCCCUGUGAGAACAACCCUUGUCUUCAUGGAGGGACAUGUAAUGCCAAUGGCACCAUGUAUGGCUGUAGCUGUGAUCAGGGCUUCGCCGGGGAGAACUGUGAGAUUGACAUUGAUGACUGCCUCUGCAGCCCCUGUGAGAAUGGAGGCACCUGUAUUGAUGAGGUCAAUGGCUUUGUCUGCCUUUGCCUCCCCAGCUAUGGGGGCAGCUUUUGUGAGAAAGACACCGAGGGCUGUGACCGCGGCUGGCAUAAGUUCCAGGGCCACUGUUACCGCUAUUUUGCCCACCGGAGGGCAUGGGAAGAUGCCGAGAAGGACUGCCGCCGCCGCUCCGGCCACCUGACCAGCGUCCACUCACCGGAGGAACACAGCUUCAUUAAUAGCUUUGGGCAUGAAAACACGUGGAUCGGCCUGAACGACAGGAUCGUGGAGAGAGAUUUCCAGUGGACGGACAACACCGGGCUGCAAUUUGAGAACUGGCGAGAGAACCAGCCGGACAAUUUCUUCGCGGGUGGCGAGGACUGUGUGGUGAUGGUGGCGCAUGAAAGCGGGCGCUGGAACGAUGUCCCCUGCAACUACAACCUACCCUAUGUCUGCAAGAAGGGCACAGUGCUCUGUGGUCCCCCUCCGGCAGUGGAGAAUGCCUCACUCAUCGGUGCCCGCAAGGCCAAGUACAAUGUCCAUGCCACUGUAAGGUACCAGUGCAAUGAAGGAUUUGCCCAGCACCAUGUGGCCACCAUUCGAUGCCGGAGCAAUGGCAAGUGGGACAGGCCCCAAAUUGUCUGCACCAAACCCAGACGUUCACAUCGGAUGCGGCGACACCACCACCACCACCAACACCACCACCAGCAUCACCACCACAAAUCCCGCAAGGAGCGCAGAAAACACAAGAAACACCCAACGGAGGACUGGGAGAAGGACGAAGGGAAUUUCUGCUGAAGAACCAGAAAAAAGAAAGCACAACACCUUUCCCAUGCCUCCUCUGGAGCCUUCGCCUGGGGAGACAGAACCCAGAGAGAAACAAGAGAGUCCAGAAGUCCCUGAACCCCAAACCACAUCCCCCACACACAUAAUCCUUUGUACAAAGCUCCUCUUUUCCCUUUUUUUACAUACACAAGAUCCUCUUGGCAGGUGGAGCCAGGUGUCUGAAAAGUUCAUUCUCGUCUGGCUGAACUCUGGGAGUGUGUCCCAGCUGAGGGAAGCACAAGUAGCAAAGCUCAUUGGUCUGGUCUCUUGUUUGCCAGGCUGAUUGAAGCAGGCCUUGAUGAGGGUGCAUGAGUGUAUGUUUGCAUUCACAUGAAGGAAUUGCUUUUCACACCAGAAAUUCAGACUUAGUCAAUGUUGGCUGAAUUCCUAAAUCCAGGAAGAAGCCUGGACGUAGGGUCAUUAGCUUUGGGAAUAGAAGGCUACACAGAAGCACACUGUUUUUGAACUUGACAACAGCUCUCCCUUUACCCUGGACUUCAGCCCAAGUUCCGUCUUUGGUCUUGGUGGAUAAACACACAGUGUGGAGAUCCCACGUACUGCAUUUUAGGGAUGUUUUUAGGACAACCUCCCUCCAUGCCUUCAGAGUUAGGAGUGAGAAUGAUCAAAGCAAUAUGUAGGUGAUGGAGGGAGAGUGUAUUGCUAACCCUUCCAGGUCUAGUCCAGCGCUGAGAUUUGGUGGUUCUGCAUGUGUGAUGAAUCUCUUUCACACAAAUAGACGAGAGGAUAUUUAGGGCUAGAUGAGCCCAGAUUUCUUCCCCCUCCAUCUCUCAGGGAGACAAAGAACCUCCUUCCUGGACCAAGGAGGUGCUGCCAAGUUUUCUAGCCCAGUGCACAUACCCAGUCCUUAAGCAGACAUUGGUAGUGCCCCUGCCCUGGGUCCCACUCCUGCCCCACCCCACCCUUGUCCCUGGCCAUUGCCUGGUGGUCUAGAAACACUUAAAACUUGAAGUAGUGACACCUACCUGCGGUCAUAUUGUAGAGAGAUGCUCAGUGUUAAAACUGAAACACACAAACACACACACACACACAUUUUUCUCUUGUAGAUUUUAAUUUUUUAAGUGGGAAAGAACUCACCUUGCCUUCCUCCCCCAAAUGUGCAACCUGUAAAAGGUCUCUCCACACCAGGGGCCAGGAUCCAGUUCCCUCAUCUCUGGCAGGAAAGAUCCACAGCUUUUCCUCCAUGUCUGUUACUCACUUUCAGCAGUCCGGGUAAAAUCUGUGGAUCAGGGUUAAAAAAGCACCGUGGAGAAUGGCCCUCUUCAGGAAAGAAAAAUAAGCAAAUGAAUGGUCCACCUAGGGGUUCAGUAAAGAAAGAAAUGUGUUAACUGAGCCUGAAUCCCUUCUGGGAAGUAAUAAUGACCAUUGACAACUAAGAAGUAGACACCAUGCUAAAGACUUACAUACAAUCUCCUUGAAUCUUCUCAAUAGCCCAUUGACUUAGAAACUGUUACUUUCCCAUUUUACACACAGUGAAACUGAGGCUCAGAUAUAAAGGAAAGGUACUGGCUUGAAGUCACAACCACGACAGGAGUAAGGAUUUGGAAUAAGGAUUUGGUCCUGUUUUCUGGACCAAAUCCUUACUCUGGCUCUGCUUACACUUUCUCUCCAUCACCAAAUCCUUACUCCAAAUCCAGAAGUCAGAGCCAACUCCCAUCUUGGUUCUGACCCAAAUCCUGCUCUGGACUCUGGAGAGGAGAUUGAAAUAUAAUUGCACCCUCAUACACAUUUAGGAAAUGGUUAAGAAGUGUAAACUGAACCCUUAUCCUUGUCUUCAAUCUUCCUCCCUGUAGACAUCUAUCUUAUUAUGGUUAUUAUUCAGAAAACCCAGGGAUACAGGUUUGUCUUCUUACUUUGAUAACUCUUCUUAGUUUAAAAUAAUAAUAAUAACACAUCUUUGGUCAUCUAUGUCACACAAAAAUUUUCCUUUGUUUGCGGGGGGCUGGGGAUGCAGUGUUUUUUGGGGGGUCUUGGUUUAUGCUCCCUGCCCUUGAGCCCCUCAGCCGUUUGCCCUGCCCCCACCUCGGCUCCAUGGUGGGAGGGGGCUCUGGUCUUUUCUAAAGUGGGCGGUUUGUCUUUUGAUCUUUCCCUUUUGGAUGUGCGUGUGUGUCUGCGUGUGCCAUGUGCGUGGCACGCAUAUGAGUGUGUGUGCGUGUGAACGGCUUUGGGUCCUGCUGGUUUUGCUGUGAGCUGCAGUGUUCUGUGGGUCUGUGGUAUCUGACACUGUGGACAUUAAUGUACUUCUUGGACAUUUUAAUAAAUUUUUUAACAGUUCAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 1463)
neurocan
strand +
NCBI CDS gene sequence (3966 bp)
5'-ATGGGGGCCCCGTTTGTCTGGGCCTTGGGCCTTTTGATGCTGCAGATGCTGCTCTTTGTGGCTGGGGAACAGGGCACACAGGATATCACCGATGCCAGCGAAAGGGGGCTCCACATGCAGAAGCTGGGGTCTGGGTCAGTGCAGGCTGCGCTGGCGGAGCTGGTGGCCCTGCCCTGTCTCTTTACCCTGCAGCCACGGCCAAGCGCAGCCCGAGATGCCCCTCGGATAAAGTGGACCAAGGTGCGGACTGCGTCGGGCCAGCGACAGGACTTGCCCATCCTGGTGGCCAAGGACAATGTCGTGAGGGTGGCCAAAAGCTGGCAGGGACGAGTGTCACTGCCTTCCTACCCCCGGCGCCGAGCCAACGCCACGCTACTTCTGGGGCCACTGAGGGCCAGTGACTCTGGGCTGTACCGCTGCCAGGTGGTGAGGGGCATCGAGGATGAGCAGGACCTGGTGCCCTTGGAGGTGACAGGTGTTGTGTTCCACTACCGATCAGCCCGGGACCGCTATGCACTGACCTTCGCTGAGGCCCAGGAGGCCTGCCGTCTCAGCTCAGCCATCATTGCAGCCCCTCGGCATCTACAGGCTGCCTTTGAGGATGGCTTTGACAACTGTGATGCTGGCTGGCTCTCTGACCGCACTGTTCGGTATCCTATCACCCAGTCCCGTCCTGGTTGCTATGGCGACCGTAGCAGCCTTCCAGGGGTTCGGAGCTATGGGAGGCGCAACCCACAGGAACTCTACGATGTGTATTGCTTTGCCCGGGAGCTGGGGGGCGAGGTCTTCTACGTGGGCCCGGCCCGCCGCCTGACACTGGCCGGCGCGCGTGCACAGTGCCGCCGCCAGGGTGCCGCGCTGGCCTCGGTGGGACAGCTGCACCTGGCCTGGCATGAGGGCCTGGACCAGTGCGACCCGGGCTGGCTGGCCGACGGCAGCGTGCGCTACCCGATCCAGACGCCGCGCCGGCGCTGCGGGGGCCCAGCCCCGGGCGTGCGCACCGTCTACCGCTTCGCTAACCGGACCGGCTTCCCCTCACCCGCCGAGCGCTTCGACGCCTACTGCTTCCGAGCTCATCACCCCACGTCACAACATGGAGACCTAGAGACCCCATCCTCTGGGGATGAGGGGGAGATTCTGTCAGCAGAGGGGCCCCCAGTTAGAGAACTGGAGCCCACCCTGGAGGAGGAAGAGGTGGTCACCCCTGACTTCCAGGAGCCTCTGGTGTCCAGTGGGGAAGAAGAAACCCTGATTTTGGAGGAGAAGCAGGAGTCTCAACAGACCCTCAGCCCTACCCCTGGGGACCCCATGCTGGCCTCATGGCCCACTGGGGAAGTGTGGCTAAGCACGGTGGCCCCCAGCCCTAGCGACATGGGGGCAGGCACTGCAGCAAGTTCACACACGGAGGTGGCCCCAACTGACCCTATGCCTAGGAGAAGGGGGCGCTTCAAAGGGTTGAATGGGCGCTACTTCCAGCAGCAGGAACCGGAGCCGGGGCTGCAAGGGGGGATGGAGGCCAGCGCCCAGCCCCCCACCTCAGAGGCTGCAGTGAACCAAATGGAGCCTCCGTTGGCCATGGCAGTCACAGAGATGTTGGGCAGTGGCCAGAGCCGGAGCCCCTGGGCTGATCTGACCAATGAGGTGGATATGCCTGGAGCTGGTTCTGCTGGTGGCAAGAGCTCCCCAGAGCCCTGGCTGTGGCCCCCTACCATGGTCCCACCCAGCATCTCAGGCCACAGCAGGGCCCCTGTCCTGGAGCTAGAGAAAGCCGAGGGCCCCAGTGCCAGGCCAGCCACCCCAGACCTGTTTTGGTCCCCCTTGGAGGCCACTGTCTCAGCTCCCAGCCCTGCCCCCTGGGAGGCATTCCCTGTGGCCACCTCCCCAGATCTCCCTATGATGGCCATGCTGCGTGGTCCCAAAGAGTGGATGCTACCACACCCCACCCCCATCTCCACCGAGGCCAATAGAGTTGAGGCACATGGTGAGGCCACCGCCACGGCTCCACCCTCCCCTGCTGCAGAGACCAAGGTGTATTCCCTGCCTCTCTCTTTGACCCCAACAGGACAGGGTGGAGAGGCCATGCCCACAACACCTGAGTCCCCCAGGGCAGACTTCAGAGAAACTGGGGAGACCAGCCCTGCTCAGGTCAACAAAGCTGAGCACTCCAGCTCCAGCCCATGGCCTTCTGTAAACAGGAATGTGGCTGTAGGTTTTGTCCCCACTGAGACTGCCACTGAGCCAACGGGCCTCAGGGGTATCCCGGGGTCTGAGTCTGGGGTCTTCGACACAGCAGAAAGCCCCACTTCTGGCTTGCAGGCCACTGTAGATGAGGTGCAGGACCCCTGGCCCTCAGTGTACAGCAAAGGGCTGGATGCAAGTTCCCCATCTGCCCCCCTGGGGAGCCCTGGAGTCTTCTTGGTACCCAAAGTCACCCCAAATTTGGAGCCTTGGGTTGCTACAGATGAAGGACCCACTGTGAATCCCATGGATTCCACAGTCACGCCGGCCCCCAGTGATGCTAGTGGAATTTGGGAACCTGGATCCCAGGTGTTTGAAGAAGCCGAAAGCACCACCTTGAGCCCTCAGGTGGCCCTGGATACAAGCATTGTGACGCCCCTCACGACCCTGGAGCAGGGGGACAAGGTTGGAGTTCCAGCCATGTCTACACTGGGCTCCTCAAGCTCCCAACCCCACCCAGAGCCAGAGGATCAGGTGGAGACCCAGGGAACATCAGGAGCTTCAGTGCCTCCGCATCAGAGCAGTCCCCTAGGGAAACCGGCTGTTCCTCCTGGGACACCGACTGCAGCCAGTGTGGGCGAGTCTGCCTCAGTTTCCTCAGGGGAGCCTACGGTACCGTGGGACCCCTCCAGCACCCTGCTGCCTGTCACCCTGGGCATAGAGGACTTCGAACTGGAGGTCCTGGCAGGGAGCCCGGGTGTAGAGAGCTTCTGGGAGGAGGTGGCAAGTGGAGAGGAGCCAGCCCTGCCAGGGACCCCTATGAATGCAGGTGCGGAGGAGGTGCACTCAGATCCCTGTGAGAACAACCCTTGTCTTCATGGAGGGACATGTAATGCCAATGGCACCATGTATGGCTGTAGCTGTGATCAGGGCTTCGCCGGGGAGAACTGTGAGATTGACATTGATGACTGCCTCTGCAGCCCCTGTGAGAATGGAGGCACCTGTATTGATGAGGTCAATGGCTTTGTCTGCCTTTGCCTCCCCAGCTATGGGGGCAGCTTTTGTGAGAAAGACACCGAGGGCTGTGACCGCGGCTGGCATAAGTTCCAGGGCCACTGTTACCGCTATTTTGCCCACCGGAGGGCATGGGAAGATGCCGAGAAGGACTGCCGCCGCCGCTCCGGCCACCTGACCAGCGTCCACTCACCGGAGGAACACAGCTTCATTAATAGCTTTGGGCATGAAAACACGTGGATCGGCCTGAACGACAGGATCGTGGAGAGAGATTTCCAGTGGACGGACAACACCGGGCTGCAATTTGAGAACTGGCGAGAGAACCAGCCGGACAATTTCTTCGCGGGTGGCGAGGACTGTGTGGTGATGGTGGCGCATGAAAGCGGGCGCTGGAACGATGTCCCCTGCAACTACAACCTACCCTATGTCTGCAAGAAGGGCACAGTGCTCTGTGGTCCCCCTCCGGCAGTGGAGAATGCCTCACTCATCGGTGCCCGCAAGGCCAAGTACAATGTCCATGCCACTGTAAGGTACCAGTGCAATGAAGGATTTGCCCAGCACCATGTGGCCACCATTCGATGCCGGAGCAATGGCAAGTGGGACAGGCCCCAAATTGTCTGCACCAAACCCAGACGTTCACATCGGATGCGGCGACACCACCACCACCACCAACACCACCACCAGCATCACCACCACAAATCCCGCAAGGAGCGCAGAAAACACAAGAAACACCCAACGGAGGACTGGGAGAAGGACGAAGGGAATTTCTGCTGA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.