NCBI Summary
This gene is a member of the aggrecan/versican proteoglycan family. The protein encoded is a large chondroitin sulfate proteoglycan and is a major component of the extracellular matrix. This protein is involved in cell adhesion, proliferation, proliferation, migration and angiogenesis and plays a central role in tissue morphogenesis and maintenance. Mutations in this gene are the cause of Wagner syndrome type 1. Multiple transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Aug 2009].
Protein
Protein (NP_004376)
Versican
Versican core protein (Chondroitin sulfate proteoglycan core protein 2) (Chondroitin sulfate proteoglycan 2) (Glial hyaluronate-binding protein) (GHAP) (Large fibroblast proteoglycan) (PG-M)
VCAN
versican
Undefined
Curated
C-type lectin
Undefined
C-type - Proteoglycans or lecticans
a/b mixed / C-type lectin-like
MFINIKSILWMCSTLIVTHALHKVKVGKSPPVRGSLSGKVSLPCHFSTMPTLPPSYNTSEFLRIKWSKIEVDKNGKDLKETTVLVAQNGNIKIGQDYKGRVSVPTHPEAVGDASLTVVKLLASDAGLYRCDVMYGIEDTQDTVSLTVDGVVFHYRAATSRYTLNFEAAQKACLDVGAVIATPEQLFAAYEDGFEQCDAGWLADQTVRYPIRAPRVGCYGDKMGKAGVRTYGFRSPQETYDVYCYVDHLDGDVFHLTVPSKFTFEEAAKECENQDARLATVGELQAAWRNGFDQCDYGWLSDASVRHPVTVARAQCGGGLLGVRTLYRFENQTGFPPPDSRFDAYCFKPKEATTIDLSILAETASPSLSKEPQMVSDRTTPIIPLVDELPVIPTEFPPVGNIVSFEQKATVQPQAITDSLATKLPTPTGSTKKPWDMDDYSPSASGPLGKLDISEIKEEVLQSTTGVSHYATDSWDGVVEDKQTQESVTQIEQIEVGPLVTSMEILKHIPSKEFPVTETPLVTARMILESKTEKKMVSTVSELVTTGHYGFTLGEEDDEDRTLTVGSDESTLIFDQIPEVITVSKTSEDTIHTHLEDLESVSASTTVSPLIMPDNNGSSMDDWEERQTSGRITEEFLGKYLSTTPFPSQHRTEIELFPYSGDKILVEGISTVIYPSLQTEMTHRRERTETLIPEMRTDTYTDEIQEEITKSPFMGKTEEEVFSGMKLSTSLSEPIHVTESSVEMTKSFDFPTLITKLSAEPTEVRDMEEDFTATPGTTKYDENITTVLLAHGTLSVEAATVSKWSWDEDNTTSKPLESTEPSASSKLPPALLTTVGMNGKDKDIPSFTEDGADEFTLIPDSTQKQLEEVTDEDIAAHGKFTIRFQPTTSTGIAEKSTLRDSTTEEKVPPITSTEGQVYATMEGSALGEVEDVDLSKPVSTVPQFAHTSEVEGLAFVSYSSTQEPTTYVDSSHTIPLSVIPKTDWGVLVPSVPSEDEVLGEPSQDILVIDQTRLEATISPETMRTTKITEGTTQEEFPWKEQTAEKPVPALSSTAWTPKEAVTPLDEQEGDGSAYTVSEDELLTGSERVPVLETTPVGKIDHSVSYPPGAVTEHKVKTDEVVTLTPRIGPKVSLSPGPEQKYETEGSSTTGFTSSLSPFSTHITQLMEETTTEKTSLEDIDLGSGLFEKPKATELIEFSTIKVTVPSDITTAFSSVDRLHTTSAFKPSSAITKKPPLIDREPGEETTSDMVIIGESTSHVPPTTLEDIVAKETETDIDREYFTTSSPPATQPTRPPTVEDKEAFGPQALSTPQPPASTKFHPDINVYIIEVRENKTGRMSDLSVIGHPIDSESKEDEPCSEETDPVHDLMAEILPEFPDIIEIDLYHSEENEEEEEECANATDVTTTPSVQYINGKHLVTTVPKDPEAAEARRGQFESVAPSQNFSDSSESDTHPFVIAKTELSTAVQPNESTETTESLEVTWKPETYPETSEHFSGGEPDVFPTVPFHEEFESGTAKKGAESVTERDTEVGHQAHEHTEPVSLFPEESSGEIAIDQESQKIAFARATEVTFGEEVEKSTSVTYTPTIVPSSASAYVSEEEAVTLIGNPWPDDLLSTKESWVEATPRQVVELSGSSSIPITEGSGEAEEDEDTMFTMVTDLSQRNTTDTLITLDTSRIITESFFEVPATTIYPVSEQPSAKVVPTKFVSETDTSEWISSTTVEEKKRKEEEGTTGTASTFEVYSSTQRSDQLILPFELESPNVATSSDSGTRKSFMSLTTPTQSEREMTDSTPVFTETNTLENLGAQTTEHSSIHQPGVQEGLTTLPRSPASVFMEQGSGEAAADPETTTVSSFSLNVEYAIQAEKEVAGTLSPHVETTFSTEPTGLVLSTVMDRVVAENITQTSREIVISERLGEPNYGAEIRGFSTGFPLEEDFSGDFREYSTVSHPIAKEETVMMEGSGDAAFRDTQTSPSTVPTSVHISHISDSEGPSSTMVSTSAFPWEEFTSSAEGSGEQLVTVSSSVVPVLPSAVQKFSGTASSIIDEGLGEVGTVNEIDRRSTILPTAEVEGTKAPVEKEEVKVSGTVSTNFPQTIEPAKLWSRQEVNPVRQEIESETTSEEQIQEEKSFESPQNSPATEQTIFDSQTFTETELKTTDYSVLTTKKTYSDDKEMKEEDTSLVNMSTPDPDANGLESYTTLPEATEKSHFFLATALVTESIPAEHVVTDSPIKKEESTKHFPKGMRPTIQESDTELLFSGLGSGEEVLPTLPTESVNFTEVEQINNTLYPHTSQVESTSSDKIEDFNRMENVAKEVGPLVSQTDIFEGSGSVTSTTLIEILSDTGAEGPTVAPLPFSTDIGHPQNQTVRWAEEIQTSRPQTITEQDSNKNSSTAEINETTTSSTDFLARAYGFEMAKEFVTSAPKPSDLYYEPSGEGSGEVDIVDSFHTSATTQATRQESSTTFVSDGSLEKHPEVPSAKAVTADGFPTVSVMLPLHSEQNKSSPDPTSTLSNTVSYERSTDGSFQDRFREFEDSTLKPNRKKPTENIIIDLDKEDKDLILTITESTILEILPELTSDKNTIIDIDHTKPVYEDILGMQTDIDTEVPSEPHDSNDESNDDSTQVQEIYEAAVNLSLTEETFEGSADVLASYTQATHDESMTYEDRSQLDHMGFHFTTGIPAPSTETELDVLLPTATSLPIPRKSATVIPEIEGIKAEAKALDDMFESSTLSDGQAIADQSEIIPTLGQFERTQEEYEDKKHAGPSFQPEFSSGAEEALVDHTPYLSIATTHLMDQSVTEVPDVMEGSNPPYYTDTTLAVSTFAKLSSQTPSSPLTIYSGSEASGHTEIPQPSALPGIDVGSSVMSPQDSFKEIHVNIEATFKPSSEEYLHITEPPSLSPDTKLEPSEDDGKPELLEEMEASPTELIAVEGTEILQDFQNKTDGQVSGEAIKMFPTIKTPEAGTVITTADEIELEGATQWPHSTSASATYGVEAGVVPWLSPQTSERPTLSSSPEINPETQAALIRGQDSTIAASEQQVAARILDSNDQATVNPVEFNTEVATPPFSLLETSNETDFLIGINEESVEGTAIYLPGPDRCKMNPCLNGGTCYPTETSYVCTCVPGYSGDQCELDFDECHSNPCRNGATCVDGFNTFRCLCLPSYVGALCEQDTETCDYGWHKFQGQCYKYFAHRRTWDAAERECRLQGAHLTSILSHEEQMFVNRVGHDYQWIGLNDKMFEHDFRWTDGSTLQYENWRPNQPDSFFSAGEDCVVIIWHENGQWNDVPCNYHLTYTCKKGTVACGQPPVVENAKTFGKMKPRYEINSLIRYHCKDGFIQRHLPTIRCLGNGRWAIPKITCMNPSAYQRTYSMKYFKNSSSAKDNSINTSKHDHRWSRRWQESRR
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
The location of the lectin domain structural model is: 3166-3294
We infer [1.43, 1.79] Å as the interval of error of this structural model.
Template 1: 6JJJ chain: A, P70194, NP_058031.2, sequence identity: 37.2%, coverage: 96.9%, location in sequence: 393-543, (393-543 in PDB).
Template 2: 6PY1 chain: A, Q8IUN9, NP_878910.1, sequence identity: 36.4%, coverage: 95.3%, location in sequence: 179-308, (179-308 in PDB).
Template 3: 6PWS chain: A, E1BIQ4, XP_005198961.1, sequence identity: 34.9%, coverage: 97.7%, location in sequence: 174-302, (162-290 in PDB).
Show the alignment used for the construction of the structural model, Download.
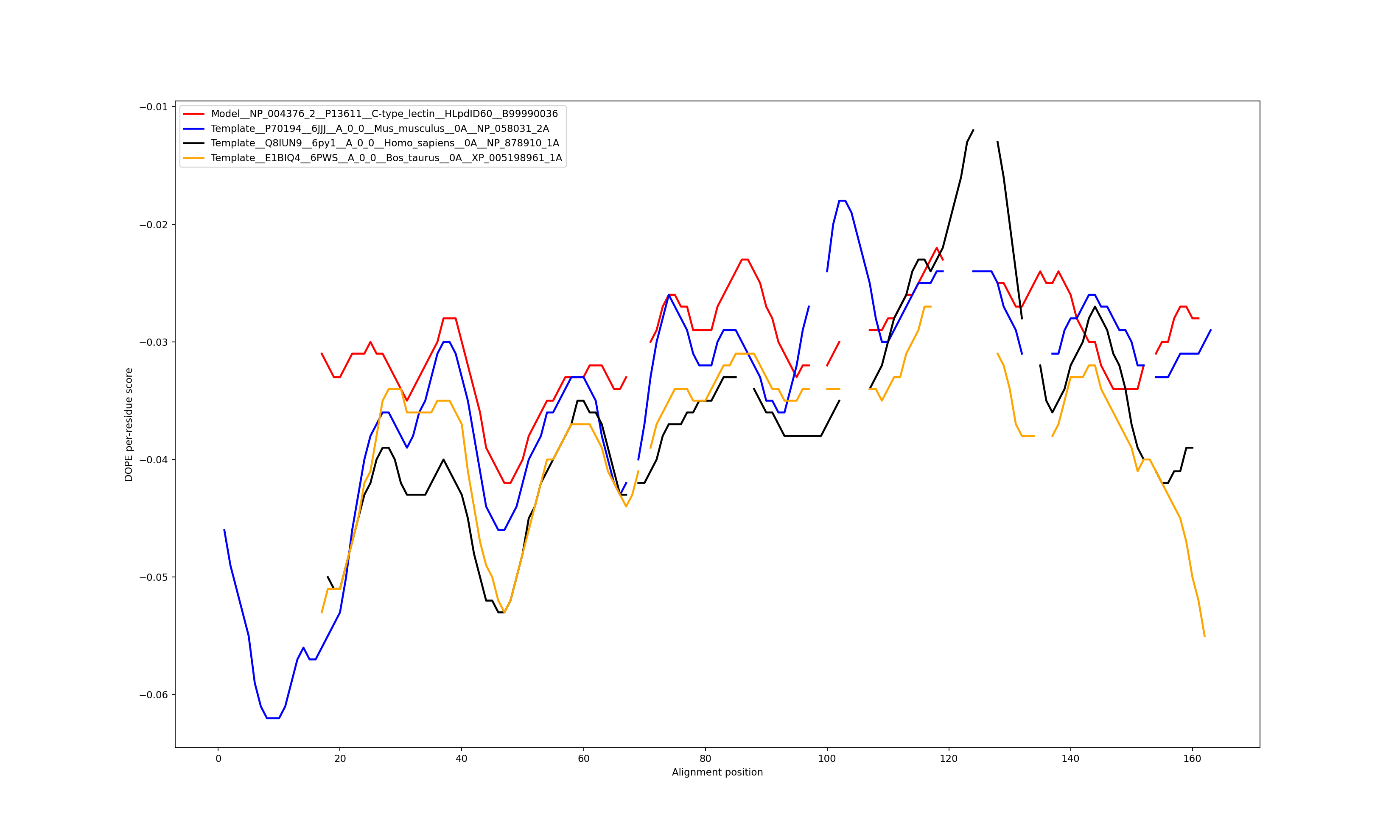
Show the plot of DOPE energy score, Download.
We infer [1.43, 1.79] Å as the interval of error of this structural model.
Template 1: 6JJJ chain: A, P70194, NP_058031.2, sequence identity: 37.2%, coverage: 96.9%, location in sequence: 393-543, (393-543 in PDB).
Template 2: 6PY1 chain: A, Q8IUN9, NP_878910.1, sequence identity: 36.4%, coverage: 95.3%, location in sequence: 179-308, (179-308 in PDB).
Template 3: 6PWS chain: A, E1BIQ4, XP_005198961.1, sequence identity: 34.9%, coverage: 97.7%, location in sequence: 174-302, (162-290 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
Interacts with FBLN1
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- Identification of novel ADAMTS1, ADAMTS4 and ADAMTS5 cleavage sites in versican using a label-free quantitative proteomics approach. [34450332]
- INHBA promotes the proliferation, migration and invasion of colon cancer cells through the upregulation of VCAN. [34130530]
- Bioinformatics analysis of the prognosis and biological significance of VCAN in gastric cancer. [33631054]
- Expression of PG-M(V3), an alternatively spliced form of PG-M without a chondroitin sulfate attachment in region in mouse and human tissues. [7876137]
- Characterization of the complete genomic structure of the human versican gene and functional analysis of its promoter. [7528742]
- VCAN-Related Vitreoretinopathy [20301747]
- Mapping of the versican proteoglycan gene (CSPG2) to the long arm of human chromosome 5 (5q12-5q14). [1478664]
- Isolation of a large aggregating proteoglycan from human brain. [1429726]
- Isolation and partial characterization of a glial hyaluronate-binding protein. [2466833]
- Structural similarity of hyaluronate binding proteins in brain and cartilage. [2469524]
UniProt Main References (12 PubMed Identifiers)
- Multiple domains of the large fibroblast proteoglycan, versican. [2583089]
- A novel glycosaminoglycan attachment domain identified in two alternative splice variants of human versican. [7806529]
- Identification of the proteoglycan versican in aorta and smooth muscle cells by DNA sequence analysis, in situ hybridization and immunohistochemistry. [7921538]
- A fibroblast chondroitin sulfate proteoglycan core protein contains lectin-like and growth factor-like sequences. [2820964]
- Versican/PG-M isoforms in vascular smooth muscle cells. [10397680]
- Differential expression of versican isoforms in brain tumors. [8627343]
- Identification of a novel splice site mutation of the CSPG2 gene in a Japanese family with Wagner syndrome. [16043844]
- Initial characterization of the human central proteome. [21269460]
- Novel VCAN mutations and evidence for unbalanced alternative splicing in the pathogenesis of Wagner syndrome. [22739342]
- An enzyme assisted RP-RPLC approach for in-depth analysis of human liver phosphoproteome. [24275569] Show more
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_004385.5)
m7G-5')ppp(5'-GCAUUUGAACUUGCAGGCGAGCUGCCCCGAGCCUUUCUGGGGAAGAACUCCAGGCGUGCGGACGCAACAGCCGAGAACAUUAGGUGUUGUGGACAGGAGCUGGGACCAAGAUCUUCGGCCAGCCCCGCAUCCUCCCGCAUCUUCCAGCACCGUCCCGCACCCUCCGCAUCCUUCCCCGGGCCACCACGCUUCCUAUGUGACCCGCCUGGGCAACGCCGAACCCAGUCGCGCAGCGCUGCAGUGAAUUUUCCCCCCAAACUGCAAUAAGCCGCCUUCCAAGGCCAAGAUGUUCAUAAAUAUAAAGAGCAUCUUAUGGAUGUGUUCAACCUUAAUAGUAACCCAUGCGCUACAUAAAGUCAAAGUGGGAAAAAGCCCACCGGUGAGGGGCUCCCUCUCUGGAAAAGUCAGCCUACCUUGUCAUUUUUCAACGAUGCCUACUUUGCCACCCAGUUACAACACCAGUGAAUUUCUCCGCAUCAAAUGGUCUAAGAUUGAAGUGGACAAAAAUGGAAAAGAUUUGAAAGAGACUACUGUCCUUGUGGCCCAAAAUGGAAAUAUCAAGAUUGGUCAGGACUACAAAGGGAGAGUGUCUGUGCCCACACAUCCCGAGGCUGUGGGCGAUGCCUCCCUCACUGUGGUCAAGCUGCUGGCAAGUGAUGCGGGUCUUUACCGCUGUGACGUCAUGUACGGGAUUGAAGACACACAAGACACGGUGUCACUGACUGUGGAUGGGGUUGUGUUUCACUACAGGGCGGCAACCAGCAGGUACACACUGAAUUUUGAGGCUGCUCAGAAGGCUUGUUUGGACGUUGGGGCAGUCAUAGCAACUCCAGAGCAGCUCUUUGCUGCCUAUGAAGAUGGAUUUGAGCAGUGUGACGCAGGCUGGCUGGCUGAUCAGACUGUCAGAUAUCCCAUCCGGGCUCCCAGAGUAGGCUGUUAUGGAGAUAAGAUGGGAAAGGCAGGAGUCAGGACUUAUGGAUUCCGUUCUCCCCAGGAAACUUACGAUGUGUAUUGUUAUGUGGAUCAUCUGGAUGGUGAUGUGUUCCACCUCACUGUCCCCAGUAAAUUCACCUUCGAGGAGGCUGCAAAAGAGUGUGAAAACCAGGAUGCCAGGCUGGCAACAGUGGGGGAACUCCAGGCGGCAUGGAGGAACGGCUUUGACCAGUGCGAUUACGGGUGGCUGUCGGAUGCCAGCGUGCGCCACCCUGUGACUGUGGCCAGGGCCCAGUGUGGAGGUGGUCUACUUGGGGUGAGAACCCUGUAUCGUUUUGAGAACCAGACAGGCUUCCCUCCCCCUGAUAGCAGAUUUGAUGCCUACUGCUUUAAACCUAAAGAGGCUACAACCAUCGAUUUGAGUAUCCUCGCAGAAACUGCAUCACCCAGUUUAUCCAAAGAACCACAAAUGGUUUCUGAUAGAACUACACCAAUCAUCCCUUUAGUUGAUGAAUUACCUGUCAUUCCAACAGAGUUCCCUCCCGUGGGAAAUAUUGUCAGUUUUGAACAGAAAGCCACAGUCCAACCUCAGGCUAUCACAGAUAGUUUAGCCACCAAAUUACCCACACCUACUGGCAGUACCAAGAAGCCCUGGGAUAUGGAUGACUACUCACCUUCUGCUUCAGGACCUCUUGGAAAGCUAGACAUAUCAGAAAUUAAGGAAGAAGUGCUCCAGAGUACAACUGGCGUCUCUCAUUAUGCUACGGAUUCAUGGGAUGGUGUCGUGGAAGAUAAACAAACACAAGAAUCGGUUACACAGAUUGAACAAAUAGAAGUGGGUCCUUUGGUAACAUCUAUGGAAAUCUUAAAGCACAUUCCUUCCAAGGAAUUCCCUGUAACUGAAACACCAUUGGUAACUGCAAGAAUGAUCCUGGAAUCCAAAACUGAAAAGAAAAUGGUAAGCACUGUUUCUGAAUUGGUAACCACAGGUCACUAUGGAUUCACCUUGGGAGAAGAGGAUGAUGAAGACAGAACACUUACAGUUGGAUCUGAUGAGAGCACCUUGAUCUUUGACCAAAUUCCUGAAGUCAUUACGGUGUCAAAGACUUCAGAAGACACCAUCCACACUCAUUUAGAAGACUUGGAGUCAGUCUCAGCAUCCACAACUGUUUCCCCUUUAAUUAUGCCUGAUAAUAAUGGAUCAUCCAUGGAUGACUGGGAAGAGAGACAAACUAGUGGUAGGAUAACGGAAGAGUUUCUUGGCAAAUAUCUGUCUACUACACCUUUUCCAUCACAGCAUCGUACAGAAAUAGAAUUGUUUCCUUAUUCUGGUGAUAAAAUAUUAGUAGAGGGAAUUUCCACAGUUAUUUAUCCUUCUCUACAAACAGAAAUGACACAUAGAAGAGAAAGAACAGAAACACUAAUACCAGAGAUGAGAACAGAUACUUAUACAGAUGAAAUACAAGAAGAGAUCACUAAAAGUCCAUUUAUGGGAAAAACAGAAGAAGAAGUCUUCUCUGGGAUGAAACUCUCUACAUCUCUCUCAGAGCCAAUUCAUGUUACAGAGUCUUCUGUGGAAAUGACCAAGUCUUUUGAUUUCCCAACAUUGAUAACAAAGUUAAGUGCAGAGCCAACAGAAGUAAGAGAUAUGGAGGAAGACUUUACAGCAACUCCAGGUACUACAAAAUAUGAUGAAAAUAUUACAACAGUGCUUUUGGCCCAUGGUACUUUAAGUGUUGAAGCAGCCACUGUAUCAAAAUGGUCAUGGGAUGAAGAUAAUACAACAUCCAAGCCUUUAGAGUCUACAGAACCUUCAGCCUCUUCAAAAUUGCCCCCUGCCUUACUCACAACUGUGGGGAUGAAUGGAAAGGAUAAAGACAUCCCAAGUUUCACUGAAGAUGGAGCAGAUGAAUUUACUCUUAUUCCAGAUAGUACUCAAAAGCAGUUAGAGGAGGUUACUGAUGAAGACAUAGCAGCCCAUGGAAAAUUCACAAUUAGAUUUCAGCCAACUACAUCAACUGGUAUUGCAGAAAAGUCAACUUUGAGAGAUUCUACAACUGAAGAAAAAGUUCCACCUAUCACAAGCACUGAAGGCCAAGUUUAUGCAACCAUGGAAGGAAGUGCUUUGGGUGAAGUAGAAGAUGUGGACCUCUCUAAGCCAGUAUCUACUGUUCCCCAAUUUGCACACACUUCAGAGGUGGAAGGAUUAGCAUUUGUUAGUUAUAGUAGCACCCAAGAGCCUACUACUUAUGUAGACUCUUCCCAUACCAUUCCUCUUUCUGUAAUUCCCAAGACAGACUGGGGAGUGUUAGUACCUUCUGUUCCAUCAGAAGAUGAAGUUCUAGGUGAACCCUCUCAAGACAUACUUGUCAUUGAUCAGACUCGCCUUGAAGCGACUAUUUCUCCAGAAACUAUGAGAACAACAAAAAUCACAGAGGGAACAACUCAGGAAGAAUUCCCUUGGAAAGAACAGACUGCAGAGAAACCAGUUCCUGCUCUCAGUUCUACAGCUUGGACUCCCAAGGAGGCAGUAACACCACUGGAUGAACAAGAGGGCGAUGGAUCAGCAUAUACAGUCUCUGAAGAUGAAUUGUUGACAGGUUCUGAGAGGGUCCCAGUUUUAGAAACAACUCCAGUUGGAAAAAUUGAUCACAGUGUGUCUUAUCCACCAGGUGCUGUAACUGAGCACAAAGUGAAAACAGAUGAAGUGGUAACACUAACACCACGCAUUGGGCCAAAAGUAUCUUUAAGUCCAGGGCCUGAACAAAAAUAUGAAACAGAAGGUAGUAGUACAACAGGAUUUACAUCAUCUUUGAGUCCUUUUAGUACCCACAUUACCCAGCUUAUGGAAGAAACCACUACUGAGAAAACAUCCCUAGAGGAUAUUGAUUUAGGCUCAGGAUUAUUUGAAAAGCCCAAAGCCACAGAACUCAUAGAAUUUUCAACAAUCAAAGUCACAGUUCCAAGUGAUAUUACCACUGCCUUCAGUUCAGUAGACAGACUUCACACAACUUCAGCAUUCAAGCCAUCUUCCGCGAUCACUAAGAAACCACCUCUCAUCGACAGGGAACCUGGUGAAGAAACAACCAGUGACAUGGUAAUCAUUGGAGAAUCAACAUCUCAUGUUCCUCCCACUACCCUUGAAGAUAUUGUAGCCAAGGAAACAGAAACCGAUAUUGAUAGAGAGUAUUUCACGACUUCAAGUCCUCCUGCUACACAGCCAACAAGACCACCCACUGUGGAAGACAAAGAGGCCUUUGGACCUCAGGCGCUUUCUACGCCACAGCCCCCAGCAAGCACAAAAUUUCACCCUGACAUUAAUGUUUAUAUUAUUGAGGUCAGAGAAAAUAAGACAGGUCGAAUGAGUGAUUUGAGUGUAAUUGGUCAUCCAAUAGAUUCAGAAUCUAAAGAAGAUGAACCUUGUAGUGAAGAAACAGAUCCAGUGCAUGAUCUAAUGGCUGAAAUUUUACCUGAAUUCCCUGACAUAAUUGAAAUAGACCUAUACCACAGUGAAGAAAAUGAAGAAGAAGAAGAAGAGUGUGCAAAUGCUACUGAUGUGACAACCACCCCAUCUGUGCAGUACAUAAAUGGGAAGCAUCUCGUUACCACUGUGCCCAAGGACCCAGAAGCUGCAGAAGCUAGGCGUGGCCAGUUUGAAAGUGUUGCACCUUCUCAGAAUUUCUCGGACAGCUCUGAAAGUGAUACUCAUCCAUUUGUAAUAGCCAAAACGGAAUUGUCUACUGCUGUGCAACCUAAUGAAUCUACAGAAACAACUGAGUCUCUUGAAGUUACAUGGAAGCCUGAGACUUACCCUGAAACAUCAGAACAUUUUUCAGGUGGUGAGCCUGAUGUUUUCCCCACAGUCCCAUUCCAUGAGGAAUUUGAAAGUGGAACAGCCAAAAAAGGGGCAGAAUCAGUCACAGAGAGAGAUACUGAAGUUGGUCAUCAGGCACAUGAACAUACUGAACCUGUAUCUCUGUUUCCUGAAGAGUCUUCAGGAGAGAUUGCCAUUGACCAAGAAUCUCAGAAAAUAGCCUUUGCAAGGGCUACAGAAGUAACAUUUGGUGAAGAGGUAGAAAAAAGUACUUCUGUCACAUACACUCCCACUAUAGUUCCAAGUUCUGCAUCAGCAUAUGUUUCAGAGGAAGAAGCAGUUACCCUAAUAGGAAAUCCUUGGCCAGAUGACCUGUUGUCUACCAAAGAAAGCUGGGUAGAAGCAACUCCUAGACAAGUUGUAGAGCUCUCAGGGAGUUCUUCGAUUCCAAUUACAGAAGGCUCUGGAGAAGCAGAAGAAGAUGAAGAUACAAUGUUCACCAUGGUAACUGAUUUAUCACAGAGAAAUACUACUGAUACACUCAUUACUUUAGACACUAGCAGGAUAAUCACAGAAAGCUUUUUUGAGGUUCCUGCAACCACCAUUUAUCCAGUUUCUGAACAACCUUCUGCAAAAGUGGUGCCUACCAAGUUUGUAAGUGAAACAGACACUUCUGAGUGGAUUUCCAGUACCACUGUUGAGGAAAAGAAAAGGAAGGAGGAGGAGGGAACUACAGGUACGGCUUCUACAUUUGAGGUAUAUUCAUCUACACAGAGAUCGGAUCAAUUAAUUUUACCCUUUGAAUUAGAAAGUCCAAAUGUAGCUACAUCUAGUGAUUCAGGUACCAGGAAAAGUUUUAUGUCCUUGACAACACCAACACAGUCUGAAAGGGAAAUGACAGAUUCUACUCCUGUCUUUACAGAAACAAAUACAUUAGAAAAUUUGGGGGCACAGACCACUGAGCACAGCAGUAUCCAUCAACCUGGGGUUCAGGAAGGGCUGACCACUCUCCCACGUAGUCCUGCCUCUGUCUUUAUGGAGCAGGGCUCUGGAGAAGCUGCUGCCGACCCAGAAACCACCACUGUUUCUUCAUUUUCAUUAAACGUAGAGUAUGCAAUUCAAGCCGAAAAGGAAGUAGCUGGCACUUUGUCUCCGCAUGUGGAAACUACAUUCUCCACUGAGCCAACAGGACUGGUUUUGAGUACAGUAAUGGACAGAGUAGUUGCUGAAAAUAUAACCCAAACAUCCAGGGAAAUAGUGAUUUCAGAGCGAUUAGGAGAACCAAAUUAUGGGGCAGAAAUAAGGGGCUUUUCCACAGGUUUUCCUUUGGAGGAAGAUUUCAGUGGUGACUUUAGAGAAUACUCAACAGUGUCUCAUCCCAUAGCAAAAGAAGAAACGGUAAUGAUGGAAGGCUCUGGAGAUGCAGCAUUUAGGGACACCCAGACUUCACCAUCUACAGUACCUACUUCAGUUCACAUCAGUCACAUAUCUGACUCAGAAGGACCCAGUAGCACCAUGGUCAGCACUUCAGCCUUCCCCUGGGAAGAGUUUACAUCCUCAGCUGAGGGCUCAGGUGAGCAACUGGUCACAGUCAGCAGCUCUGUUGUUCCAGUGCUUCCCAGUGCUGUGCAAAAGUUUUCUGGUACAGCUUCCUCCAUUAUCGACGAAGGAUUGGGAGAAGUGGGUACUGUCAAUGAAAUUGAUAGAAGAUCCACCAUUUUACCAACAGCAGAAGUGGAAGGUACGAAAGCUCCAGUAGAGAAGGAGGAAGUAAAGGUCAGUGGCACAGUUUCAACAAACUUUCCCCAAACUAUAGAGCCAGCCAAAUUAUGGUCUAGGCAAGAAGUCAACCCUGUAAGACAAGAAAUUGAAAGUGAAACAACAUCAGAGGAACAAAUUCAAGAAGAAAAGUCAUUUGAAUCCCCUCAAAACUCUCCUGCAACAGAACAAACAAUCUUUGAUUCACAGACAUUUACUGAAACUGAACUCAAAACCACAGAUUAUUCUGUACUAACAACAAAGAAAACUUACAGUGAUGAUAAAGAAAUGAAGGAGGAAGACACUUCUUUAGUUAACAUGUCUACUCCAGAUCCAGAUGCAAAUGGCUUGGAAUCUUACACAACUCUCCCUGAAGCUACUGAAAAGUCACAUUUUUUCUUAGCUACUGCAUUAGUAACUGAAUCUAUACCAGCUGAACAUGUAGUCACAGAUUCACCAAUCAAAAAGGAAGAAAGUACAAAACAUUUUCCGAAAGGCAUGAGACCAACAAUUCAAGAGUCAGAUACUGAGCUCUUAUUCUCUGGACUGGGAUCAGGAGAAGAAGUUUUACCUACUCUACCAACAGAGUCAGUGAAUUUUACUGAAGUGGAACAAAUCAAUAACACAUUAUAUCCCCACACUUCUCAAGUGGAAAGUACCUCAAGUGACAAAAUUGAAGACUUUAACAGAAUGGAAAAUGUGGCAAAAGAAGUUGGACCACUCGUAUCUCAAACAGACAUCUUUGAAGGUAGUGGGUCAGUAACCAGCACAACAUUAAUAGAAAUUUUAAGUGACACUGGAGCAGAAGGACCCACGGUGGCACCUCUCCCUUUCUCCACGGACAUCGGACAUCCUCAAAAUCAGACUGUCAGGUGGGCAGAAGAAAUCCAGACUAGUAGACCACAAACCAUAACUGAACAAGACUCUAACAAGAAUUCUUCAACAGCAGAAAUUAACGAAACAACAACCUCAUCUACUGAUUUUCUGGCUAGAGCUUAUGGUUUUGAAAUGGCCAAAGAAUUUGUUACAUCAGCACCAAAACCAUCUGACUUGUAUUAUGAACCUUCUGGAGAAGGAUCUGGAGAAGUGGAUAUUGUUGAUUCAUUUCACACUUCUGCAACUACUCAGGCAACCAGACAAGAAAGCAGCACCACAUUUGUUUCUGAUGGGUCCCUGGAAAAACAUCCUGAGGUGCCAAGCGCUAAAGCUGUUACUGCUGAUGGAUUCCCAACAGUUUCAGUGAUGCUGCCUCUUCAUUCAGAGCAGAACAAAAGCUCCCCUGAUCCAACUAGCACACUGUCAAAUACAGUGUCAUAUGAGAGGUCCACAGACGGUAGUUUCCAAGACCGUUUCAGGGAAUUCGAGGAUUCCACCUUAAAACCUAACAGAAAAAAACCCACUGAAAAUAUUAUCAUAGACCUGGACAAAGAGGACAAGGAUUUAAUAUUGACAAUUACAGAGAGUACCAUCCUUGAAAUUCUACCUGAGCUGACAUCGGAUAAAAAUACUAUCAUAGAUAUUGAUCAUACUAAACCUGUGUAUGAAGACAUUCUUGGAAUGCAAACAGAUAUAGAUACAGAGGUACCAUCAGAACCACAUGACAGUAAUGAUGAAAGUAAUGAUGACAGCACUCAAGUUCAAGAGAUCUAUGAGGCAGCUGUCAACCUUUCUUUAACUGAGGAAACAUUUGAGGGCUCUGCUGAUGUUCUGGCUAGCUACACUCAGGCAACACAUGAUGAAUCAAUGACUUAUGAAGAUAGAAGCCAACUAGAUCACAUGGGCUUUCACUUCACAACUGGGAUCCCUGCUCCUAGCACAGAAACAGAAUUAGACGUUUUACUUCCCACGGCAACAUCCCUGCCAAUUCCUCGUAAGUCUGCCACAGUUAUUCCAGAGAUUGAAGGAAUAAAAGCUGAAGCAAAAGCCCUGGAUGACAUGUUUGAAUCAAGCACUUUGUCUGAUGGUCAAGCUAUUGCAGACCAAAGUGAAAUAAUACCAACAUUGGGCCAAUUUGAAAGGACUCAGGAGGAGUAUGAAGACAAAAAACAUGCUGGUCCUUCUUUUCAGCCAGAAUUCUCUUCAGGAGCUGAGGAGGCAUUAGUAGACCAUACUCCCUAUCUAAGUAUUGCUACUACCCACCUUAUGGAUCAGAGUGUAACAGAGGUGCCUGAUGUGAUGGAAGGAUCCAAUCCCCCAUAUUACACUGAUACAACAUUAGCAGUUUCAACAUUUGCGAAGUUGUCUUCUCAGACACCAUCAUCUCCCCUCACUAUCUACUCAGGCAGUGAAGCCUCUGGACACACAGAGAUCCCCCAGCCCAGUGCUCUGCCAGGAAUAGACGUCGGCUCAUCUGUAAUGUCCCCACAGGAUUCUUUUAAGGAAAUUCAUGUAAAUAUUGAAGCGACUUUCAAACCAUCAAGUGAGGAAUACCUUCACAUAACUGAGCCUCCCUCUUUAUCUCCUGACACAAAAUUAGAACCUUCAGAAGAUGAUGGUAAACCUGAGUUAUUAGAAGAAAUGGAAGCUUCUCCCACAGAACUUAUUGCUGUGGAAGGAACUGAGAUUCUCCAAGAUUUCCAAAACAAAACCGAUGGUCAAGUUUCUGGAGAAGCAAUCAAGAUGUUUCCCACCAUUAAAACACCUGAGGCUGGAACUGUUAUUACAACUGCCGAUGAAAUUGAAUUAGAAGGUGCUACACAGUGGCCACACUCUACUUCUGCUUCUGCCACCUAUGGGGUCGAGGCAGGUGUGGUGCCUUGGCUAAGUCCACAGACUUCUGAGAGGCCCACGCUUUCUUCUUCUCCAGAAAUAAACCCUGAAACUCAAGCAGCUUUAAUCAGAGGGCAGGAUUCCACGAUAGCAGCAUCAGAACAGCAAGUGGCAGCGAGAAUUCUUGAUUCCAAUGAUCAGGCAACAGUAAACCCUGUGGAAUUUAAUACUGAGGUUGCAACACCACCAUUUUCCCUUCUGGAGACUUCUAAUGAAACAGAUUUCCUGAUUGGCAUUAAUGAAGAGUCAGUGGAAGGCACGGCAAUCUAUUUACCAGGACCUGAUCGCUGCAAAAUGAACCCGUGCCUUAACGGAGGCACCUGUUAUCCUACUGAAACUUCCUACGUAUGCACCUGUGUGCCAGGAUACAGCGGAGACCAGUGUGAACUUGAUUUUGAUGAAUGUCACUCUAAUCCCUGUCGUAAUGGAGCCACUUGUGUUGAUGGUUUUAACACAUUCAGGUGCCUCUGCCUUCCAAGUUAUGUUGGUGCACUUUGUGAGCAAGAUACCGAGACAUGUGACUAUGGCUGGCACAAAUUCCAAGGGCAGUGCUACAAAUACUUUGCCCAUCGACGCACAUGGGAUGCAGCUGAACGGGAAUGCCGUCUGCAGGGUGCCCAUCUCACAAGCAUCCUGUCUCACGAAGAACAAAUGUUUGUUAAUCGUGUGGGCCAUGAUUAUCAGUGGAUAGGCCUCAAUGACAAGAUGUUUGAGCAUGACUUCCGUUGGACUGAUGGCAGCACACUGCAAUACGAGAAUUGGAGACCCAACCAGCCAGACAGCUUCUUUUCUGCUGGAGAAGACUGUGUUGUAAUCAUUUGGCAUGAGAAUGGCCAGUGGAAUGAUGUUCCCUGCAAUUACCAUCUCACCUAUACGUGCAAGAAAGGAACAGUCGCUUGCGGCCAGCCCCCUGUUGUAGAAAAUGCCAAGACCUUUGGAAAGAUGAAACCUCGUUAUGAAAUCAACUCCCUGAUUAGAUACCACUGCAAAGAUGGUUUCAUUCAACGUCACCUUCCAACUAUCCGGUGCUUAGGAAAUGGAAGAUGGGCUAUACCUAAAAUUACCUGCAUGAACCCAUCUGCAUACCAAAGGACUUAUUCUAUGAAAUACUUUAAAAAUUCCUCAUCAGCAAAGGACAAUUCAAUAAAUACAUCCAAACAUGAUCAUCGUUGGAGCCGGAGGUGGCAGGAGUCGAGGCGCUGAUCCCUAAAAUGGCGAACAUGUGUUUUCAUCAUUUCAGCCAAAGUCCUAACUUCCUGUGCCUUUCCUAUCACCUCGAGAAGUAAUUAUCAGUUGGUUUGGAUUUUUGGACCACCGUUCAGUCAUUUUGGGUUGCCGUGCUCCCAAAACAUUUUAAAUGAAAGUAUUGGCAUUCAAAAAGACAGCAGACAAAAUGAAAGAAAAUGAGAGCAGAAAGUAAGCAUUUCCAGCCUAUCUAAUUUCUUUAGUUUUCUAUUUGCCUCCAGUGCAGUCCAUUUCCUAAUGUAUACCAGCCUACUGUACUAUUUAAAAUGCUCAAUUUCAGCACCGAUGGCCAUGUAAAUAAGAUGAUUUAAUGUUGAUUUUAAUCCUGUAUAUAAAAUAAAAAGUCACAAUGAGUUUGGGCAUAUUUAAUGAUGAUUAUGGAGCCUUAGAGGUCUUUAAUCAUUGGUUCGGCUGCUUUUAUGUAGUUUAGGCUGGAAAUGGUUUCACUUGCUCUUUGACUGUCAGCAAGACUGAAGAUGGCUUUUCCUGGACAGCUAGAAAACACAAAAUCUUGUAGGUCAUUGCACCUAUCUCAGCCAUAGGUGCAGUUUGCUUCUACAUGAUGCUAAAGGCUGCGAAUGGGAUCCUGAUGGAACUAAGGACUCCAAUGUCGAACUCUUCUUUGCUGCAUUCCUUUUUCUUCACUUACAAGAAAGGCCUGAAUGGAGGACUUUUCUGUAACCAGGAACAUUUUUUAGGGGUCAAAGUGCUAAUAAUUAACUCAACCAGGUCUACUUUUUAAUGGCUUUCAUAACACUAACUCAUAAGGUUACCGAUCAAUGCAUUUCAUACGGAUAUAGACCUAGGGCUCUGGAGGGUGGGGGAUUGUUAAAACACAUGCAAAAAAAAAAAAAAAAAAAAAAAAAGAAAUUUUGUAUAUAUAACCAUUUUAAUCUUUUAUAAAGUUUUGAAUGUUCAUGUAUGAAUGCUGCAGCUGUGAAGCAUACAUAAAUAAAUGAAGUAAGCCAUACUGAUUUAAUUUAUUGGAUGUUAUUUUCCCUAAGACCUGAAAAUGAACAUAGUAUGCUAGUUAUUUUUCAGUGUUAGCCUUUUACUUUCCUCACACAAUUUGGAAUCAUAUAAUAUAGGUACUUUGUCCCUGAUUAAAUAAUGUGACGGAUAGAAUGCAUCAAGUGUUUAUUAUGAAAAGAGUGGAAAAGUAUAUAGCUUUUAGCAAAAGGUGUUUGCCCAUUCUAAGAAAUGAGCGAAUAUAUAGAAAUAGUGUGGGCAUUUCUUCCUGUUAGGUGGAGUGUAUGUGUUGACAUUUCUCCCCAUCUCUUCCCACUCUGUUUUCUCCCCAUUAUUUGAAUAAAGUGACUGCUGAAGAUGACUUUGAAUCCUUAUCCACUUAAUUUAAUGUUUAAAGAAAAACCUGUAAUGGAAAGUAAGACUCCUUCCCUAAUUUCAGUUUAGAGCAACUUGAAGAAGAGUAGACAAAAAAUAAAAUGCACAUAGAAAAAGAGAAAAAGGGCACAAAGGGAUUGGCCCAAUAUUGAUUCUUUUUUUAUAAAACCUCCUUUGGCUUAGAAGGAAUGACUCUAGCUACAAUAAUACACAGUAUGUUUAAGCAGGUUCCCUUGGUUGUUGCAUUAAAUGUAAUCCACCUUUAGGUAUUUUAGAGCACAGAACAACACUGUGUUGAUCUAGUAGGUUUCUAUUUUUCCUUUCUCUUUACAAUGCACAUAAUACUUUCCUGUAUUUAUAUCAUAACGUGUAUAGUGUAAAAUGUGAAUGACUUUUUUUGUGAAUGAAAAUCUAAAAUCUUUGUAACUUUUUAUAUCUGCUUUUGUUUCACCAAAGAAACCUAAAAUCCUUCUUUUACUACA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 1462)
versican
strand +
NCBI CDS gene sequence (10191 bp)
5'-ATGTTCATAAATATAAAGAGCATCTTATGGATGTGTTCAACCTTAATAGTAACCCATGCGCTACATAAAGTCAAAGTGGGAAAAAGCCCACCGGTGAGGGGCTCCCTCTCTGGAAAAGTCAGCCTACCTTGTCATTTTTCAACGATGCCTACTTTGCCACCCAGTTACAACACCAGTGAATTTCTCCGCATCAAATGGTCTAAGATTGAAGTGGACAAAAATGGAAAAGATTTGAAAGAGACTACTGTCCTTGTGGCCCAAAATGGAAATATCAAGATTGGTCAGGACTACAAAGGGAGAGTGTCTGTGCCCACACATCCCGAGGCTGTGGGCGATGCCTCCCTCACTGTGGTCAAGCTGCTGGCAAGTGATGCGGGTCTTTACCGCTGTGACGTCATGTACGGGATTGAAGACACACAAGACACGGTGTCACTGACTGTGGATGGGGTTGTGTTTCACTACAGGGCGGCAACCAGCAGGTACACACTGAATTTTGAGGCTGCTCAGAAGGCTTGTTTGGACGTTGGGGCAGTCATAGCAACTCCAGAGCAGCTCTTTGCTGCCTATGAAGATGGATTTGAGCAGTGTGACGCAGGCTGGCTGGCTGATCAGACTGTCAGATATCCCATCCGGGCTCCCAGAGTAGGCTGTTATGGAGATAAGATGGGAAAGGCAGGAGTCAGGACTTATGGATTCCGTTCTCCCCAGGAAACTTACGATGTGTATTGTTATGTGGATCATCTGGATGGTGATGTGTTCCACCTCACTGTCCCCAGTAAATTCACCTTCGAGGAGGCTGCAAAAGAGTGTGAAAACCAGGATGCCAGGCTGGCAACAGTGGGGGAACTCCAGGCGGCATGGAGGAACGGCTTTGACCAGTGCGATTACGGGTGGCTGTCGGATGCCAGCGTGCGCCACCCTGTGACTGTGGCCAGGGCCCAGTGTGGAGGTGGTCTACTTGGGGTGAGAACCCTGTATCGTTTTGAGAACCAGACAGGCTTCCCTCCCCCTGATAGCAGATTTGATGCCTACTGCTTTAAACCTAAAGAGGCTACAACCATCGATTTGAGTATCCTCGCAGAAACTGCATCACCCAGTTTATCCAAAGAACCACAAATGGTTTCTGATAGAACTACACCAATCATCCCTTTAGTTGATGAATTACCTGTCATTCCAACAGAGTTCCCTCCCGTGGGAAATATTGTCAGTTTTGAACAGAAAGCCACAGTCCAACCTCAGGCTATCACAGATAGTTTAGCCACCAAATTACCCACACCTACTGGCAGTACCAAGAAGCCCTGGGATATGGATGACTACTCACCTTCTGCTTCAGGACCTCTTGGAAAGCTAGACATATCAGAAATTAAGGAAGAAGTGCTCCAGAGTACAACTGGCGTCTCTCATTATGCTACGGATTCATGGGATGGTGTCGTGGAAGATAAACAAACACAAGAATCGGTTACACAGATTGAACAAATAGAAGTGGGTCCTTTGGTAACATCTATGGAAATCTTAAAGCACATTCCTTCCAAGGAATTCCCTGTAACTGAAACACCATTGGTAACTGCAAGAATGATCCTGGAATCCAAAACTGAAAAGAAAATGGTAAGCACTGTTTCTGAATTGGTAACCACAGGTCACTATGGATTCACCTTGGGAGAAGAGGATGATGAAGACAGAACACTTACAGTTGGATCTGATGAGAGCACCTTGATCTTTGACCAAATTCCTGAAGTCATTACGGTGTCAAAGACTTCAGAAGACACCATCCACACTCATTTAGAAGACTTGGAGTCAGTCTCAGCATCCACAACTGTTTCCCCTTTAATTATGCCTGATAATAATGGATCATCCATGGATGACTGGGAAGAGAGACAAACTAGTGGTAGGATAACGGAAGAGTTTCTTGGCAAATATCTGTCTACTACACCTTTTCCATCACAGCATCGTACAGAAATAGAATTGTTTCCTTATTCTGGTGATAAAATATTAGTAGAGGGAATTTCCACAGTTATTTATCCTTCTCTACAAACAGAAATGACACATAGAAGAGAAAGAACAGAAACACTAATACCAGAGATGAGAACAGATACTTATACAGATGAAATACAAGAAGAGATCACTAAAAGTCCATTTATGGGAAAAACAGAAGAAGAAGTCTTCTCTGGGATGAAACTCTCTACATCTCTCTCAGAGCCAATTCATGTTACAGAGTCTTCTGTGGAAATGACCAAGTCTTTTGATTTCCCAACATTGATAACAAAGTTAAGTGCAGAGCCAACAGAAGTAAGAGATATGGAGGAAGACTTTACAGCAACTCCAGGTACTACAAAATATGATGAAAATATTACAACAGTGCTTTTGGCCCATGGTACTTTAAGTGTTGAAGCAGCCACTGTATCAAAATGGTCATGGGATGAAGATAATACAACATCCAAGCCTTTAGAGTCTACAGAACCTTCAGCCTCTTCAAAATTGCCCCCTGCCTTACTCACAACTGTGGGGATGAATGGAAAGGATAAAGACATCCCAAGTTTCACTGAAGATGGAGCAGATGAATTTACTCTTATTCCAGATAGTACTCAAAAGCAGTTAGAGGAGGTTACTGATGAAGACATAGCAGCCCATGGAAAATTCACAATTAGATTTCAGCCAACTACATCAACTGGTATTGCAGAAAAGTCAACTTTGAGAGATTCTACAACTGAAGAAAAAGTTCCACCTATCACAAGCACTGAAGGCCAAGTTTATGCAACCATGGAAGGAAGTGCTTTGGGTGAAGTAGAAGATGTGGACCTCTCTAAGCCAGTATCTACTGTTCCCCAATTTGCACACACTTCAGAGGTGGAAGGATTAGCATTTGTTAGTTATAGTAGCACCCAAGAGCCTACTACTTATGTAGACTCTTCCCATACCATTCCTCTTTCTGTAATTCCCAAGACAGACTGGGGAGTGTTAGTACCTTCTGTTCCATCAGAAGATGAAGTTCTAGGTGAACCCTCTCAAGACATACTTGTCATTGATCAGACTCGCCTTGAAGCGACTATTTCTCCAGAAACTATGAGAACAACAAAAATCACAGAGGGAACAACTCAGGAAGAATTCCCTTGGAAAGAACAGACTGCAGAGAAACCAGTTCCTGCTCTCAGTTCTACAGCTTGGACTCCCAAGGAGGCAGTAACACCACTGGATGAACAAGAGGGCGATGGATCAGCATATACAGTCTCTGAAGATGAATTGTTGACAGGTTCTGAGAGGGTCCCAGTTTTAGAAACAACTCCAGTTGGAAAAATTGATCACAGTGTGTCTTATCCACCAGGTGCTGTAACTGAGCACAAAGTGAAAACAGATGAAGTGGTAACACTAACACCACGCATTGGGCCAAAAGTATCTTTAAGTCCAGGGCCTGAACAAAAATATGAAACAGAAGGTAGTAGTACAACAGGATTTACATCATCTTTGAGTCCTTTTAGTACCCACATTACCCAGCTTATGGAAGAAACCACTACTGAGAAAACATCCCTAGAGGATATTGATTTAGGCTCAGGATTATTTGAAAAGCCCAAAGCCACAGAACTCATAGAATTTTCAACAATCAAAGTCACAGTTCCAAGTGATATTACCACTGCCTTCAGTTCAGTAGACAGACTTCACACAACTTCAGCATTCAAGCCATCTTCCGCGATCACTAAGAAACCACCTCTCATCGACAGGGAACCTGGTGAAGAAACAACCAGTGACATGGTAATCATTGGAGAATCAACATCTCATGTTCCTCCCACTACCCTTGAAGATATTGTAGCCAAGGAAACAGAAACCGATATTGATAGAGAGTATTTCACGACTTCAAGTCCTCCTGCTACACAGCCAACAAGACCACCCACTGTGGAAGACAAAGAGGCCTTTGGACCTCAGGCGCTTTCTACGCCACAGCCCCCAGCAAGCACAAAATTTCACCCTGACATTAATGTTTATATTATTGAGGTCAGAGAAAATAAGACAGGTCGAATGAGTGATTTGAGTGTAATTGGTCATCCAATAGATTCAGAATCTAAAGAAGATGAACCTTGTAGTGAAGAAACAGATCCAGTGCATGATCTAATGGCTGAAATTTTACCTGAATTCCCTGACATAATTGAAATAGACCTATACCACAGTGAAGAAAATGAAGAAGAAGAAGAAGAGTGTGCAAATGCTACTGATGTGACAACCACCCCATCTGTGCAGTACATAAATGGGAAGCATCTCGTTACCACTGTGCCCAAGGACCCAGAAGCTGCAGAAGCTAGGCGTGGCCAGTTTGAAAGTGTTGCACCTTCTCAGAATTTCTCGGACAGCTCTGAAAGTGATACTCATCCATTTGTAATAGCCAAAACGGAATTGTCTACTGCTGTGCAACCTAATGAATCTACAGAAACAACTGAGTCTCTTGAAGTTACATGGAAGCCTGAGACTTACCCTGAAACATCAGAACATTTTTCAGGTGGTGAGCCTGATGTTTTCCCCACAGTCCCATTCCATGAGGAATTTGAAAGTGGAACAGCCAAAAAAGGGGCAGAATCAGTCACAGAGAGAGATACTGAAGTTGGTCATCAGGCACATGAACATACTGAACCTGTATCTCTGTTTCCTGAAGAGTCTTCAGGAGAGATTGCCATTGACCAAGAATCTCAGAAAATAGCCTTTGCAAGGGCTACAGAAGTAACATTTGGTGAAGAGGTAGAAAAAAGTACTTCTGTCACATACACTCCCACTATAGTTCCAAGTTCTGCATCAGCATATGTTTCAGAGGAAGAAGCAGTTACCCTAATAGGAAATCCTTGGCCAGATGACCTGTTGTCTACCAAAGAAAGCTGGGTAGAAGCAACTCCTAGACAAGTTGTAGAGCTCTCAGGGAGTTCTTCGATTCCAATTACAGAAGGCTCTGGAGAAGCAGAAGAAGATGAAGATACAATGTTCACCATGGTAACTGATTTATCACAGAGAAATACTACTGATACACTCATTACTTTAGACACTAGCAGGATAATCACAGAAAGCTTTTTTGAGGTTCCTGCAACCACCATTTATCCAGTTTCTGAACAACCTTCTGCAAAAGTGGTGCCTACCAAGTTTGTAAGTGAAACAGACACTTCTGAGTGGATTTCCAGTACCACTGTTGAGGAAAAGAAAAGGAAGGAGGAGGAGGGAACTACAGGTACGGCTTCTACATTTGAGGTATATTCATCTACACAGAGATCGGATCAATTAATTTTACCCTTTGAATTAGAAAGTCCAAATGTAGCTACATCTAGTGATTCAGGTACCAGGAAAAGTTTTATGTCCTTGACAACACCAACACAGTCTGAAAGGGAAATGACAGATTCTACTCCTGTCTTTACAGAAACAAATACATTAGAAAATTTGGGGGCACAGACCACTGAGCACAGCAGTATCCATCAACCTGGGGTTCAGGAAGGGCTGACCACTCTCCCACGTAGTCCTGCCTCTGTCTTTATGGAGCAGGGCTCTGGAGAAGCTGCTGCCGACCCAGAAACCACCACTGTTTCTTCATTTTCATTAAACGTAGAGTATGCAATTCAAGCCGAAAAGGAAGTAGCTGGCACTTTGTCTCCGCATGTGGAAACTACATTCTCCACTGAGCCAACAGGACTGGTTTTGAGTACAGTAATGGACAGAGTAGTTGCTGAAAATATAACCCAAACATCCAGGGAAATAGTGATTTCAGAGCGATTAGGAGAACCAAATTATGGGGCAGAAATAAGGGGCTTTTCCACAGGTTTTCCTTTGGAGGAAGATTTCAGTGGTGACTTTAGAGAATACTCAACAGTGTCTCATCCCATAGCAAAAGAAGAAACGGTAATGATGGAAGGCTCTGGAGATGCAGCATTTAGGGACACCCAGACTTCACCATCTACAGTACCTACTTCAGTTCACATCAGTCACATATCTGACTCAGAAGGACCCAGTAGCACCATGGTCAGCACTTCAGCCTTCCCCTGGGAAGAGTTTACATCCTCAGCTGAGGGCTCAGGTGAGCAACTGGTCACAGTCAGCAGCTCTGTTGTTCCAGTGCTTCCCAGTGCTGTGCAAAAGTTTTCTGGTACAGCTTCCTCCATTATCGACGAAGGATTGGGAGAAGTGGGTACTGTCAATGAAATTGATAGAAGATCCACCATTTTACCAACAGCAGAAGTGGAAGGTACGAAAGCTCCAGTAGAGAAGGAGGAAGTAAAGGTCAGTGGCACAGTTTCAACAAACTTTCCCCAAACTATAGAGCCAGCCAAATTATGGTCTAGGCAAGAAGTCAACCCTGTAAGACAAGAAATTGAAAGTGAAACAACATCAGAGGAACAAATTCAAGAAGAAAAGTCATTTGAATCCCCTCAAAACTCTCCTGCAACAGAACAAACAATCTTTGATTCACAGACATTTACTGAAACTGAACTCAAAACCACAGATTATTCTGTACTAACAACAAAGAAAACTTACAGTGATGATAAAGAAATGAAGGAGGAAGACACTTCTTTAGTTAACATGTCTACTCCAGATCCAGATGCAAATGGCTTGGAATCTTACACAACTCTCCCTGAAGCTACTGAAAAGTCACATTTTTTCTTAGCTACTGCATTAGTAACTGAATCTATACCAGCTGAACATGTAGTCACAGATTCACCAATCAAAAAGGAAGAAAGTACAAAACATTTTCCGAAAGGCATGAGACCAACAATTCAAGAGTCAGATACTGAGCTCTTATTCTCTGGACTGGGATCAGGAGAAGAAGTTTTACCTACTCTACCAACAGAGTCAGTGAATTTTACTGAAGTGGAACAAATCAATAACACATTATATCCCCACACTTCTCAAGTGGAAAGTACCTCAAGTGACAAAATTGAAGACTTTAACAGAATGGAAAATGTGGCAAAAGAAGTTGGACCACTCGTATCTCAAACAGACATCTTTGAAGGTAGTGGGTCAGTAACCAGCACAACATTAATAGAAATTTTAAGTGACACTGGAGCAGAAGGACCCACGGTGGCACCTCTCCCTTTCTCCACGGACATCGGACATCCTCAAAATCAGACTGTCAGGTGGGCAGAAGAAATCCAGACTAGTAGACCACAAACCATAACTGAACAAGACTCTAACAAGAATTCTTCAACAGCAGAAATTAACGAAACAACAACCTCATCTACTGATTTTCTGGCTAGAGCTTATGGTTTTGAAATGGCCAAAGAATTTGTTACATCAGCACCAAAACCATCTGACTTGTATTATGAACCTTCTGGAGAAGGATCTGGAGAAGTGGATATTGTTGATTCATTTCACACTTCTGCAACTACTCAGGCAACCAGACAAGAAAGCAGCACCACATTTGTTTCTGATGGGTCCCTGGAAAAACATCCTGAGGTGCCAAGCGCTAAAGCTGTTACTGCTGATGGATTCCCAACAGTTTCAGTGATGCTGCCTCTTCATTCAGAGCAGAACAAAAGCTCCCCTGATCCAACTAGCACACTGTCAAATACAGTGTCATATGAGAGGTCCACAGACGGTAGTTTCCAAGACCGTTTCAGGGAATTCGAGGATTCCACCTTAAAACCTAACAGAAAAAAACCCACTGAAAATATTATCATAGACCTGGACAAAGAGGACAAGGATTTAATATTGACAATTACAGAGAGTACCATCCTTGAAATTCTACCTGAGCTGACATCGGATAAAAATACTATCATAGATATTGATCATACTAAACCTGTGTATGAAGACATTCTTGGAATGCAAACAGATATAGATACAGAGGTACCATCAGAACCACATGACAGTAATGATGAAAGTAATGATGACAGCACTCAAGTTCAAGAGATCTATGAGGCAGCTGTCAACCTTTCTTTAACTGAGGAAACATTTGAGGGCTCTGCTGATGTTCTGGCTAGCTACACTCAGGCAACACATGATGAATCAATGACTTATGAAGATAGAAGCCAACTAGATCACATGGGCTTTCACTTCACAACTGGGATCCCTGCTCCTAGCACAGAAACAGAATTAGACGTTTTACTTCCCACGGCAACATCCCTGCCAATTCCTCGTAAGTCTGCCACAGTTATTCCAGAGATTGAAGGAATAAAAGCTGAAGCAAAAGCCCTGGATGACATGTTTGAATCAAGCACTTTGTCTGATGGTCAAGCTATTGCAGACCAAAGTGAAATAATACCAACATTGGGCCAATTTGAAAGGACTCAGGAGGAGTATGAAGACAAAAAACATGCTGGTCCTTCTTTTCAGCCAGAATTCTCTTCAGGAGCTGAGGAGGCATTAGTAGACCATACTCCCTATCTAAGTATTGCTACTACCCACCTTATGGATCAGAGTGTAACAGAGGTGCCTGATGTGATGGAAGGATCCAATCCCCCATATTACACTGATACAACATTAGCAGTTTCAACATTTGCGAAGTTGTCTTCTCAGACACCATCATCTCCCCTCACTATCTACTCAGGCAGTGAAGCCTCTGGACACACAGAGATCCCCCAGCCCAGTGCTCTGCCAGGAATAGACGTCGGCTCATCTGTAATGTCCCCACAGGATTCTTTTAAGGAAATTCATGTAAATATTGAAGCGACTTTCAAACCATCAAGTGAGGAATACCTTCACATAACTGAGCCTCCCTCTTTATCTCCTGACACAAAATTAGAACCTTCAGAAGATGATGGTAAACCTGAGTTATTAGAAGAAATGGAAGCTTCTCCCACAGAACTTATTGCTGTGGAAGGAACTGAGATTCTCCAAGATTTCCAAAACAAAACCGATGGTCAAGTTTCTGGAGAAGCAATCAAGATGTTTCCCACCATTAAAACACCTGAGGCTGGAACTGTTATTACAACTGCCGATGAAATTGAATTAGAAGGTGCTACACAGTGGCCACACTCTACTTCTGCTTCTGCCACCTATGGGGTCGAGGCAGGTGTGGTGCCTTGGCTAAGTCCACAGACTTCTGAGAGGCCCACGCTTTCTTCTTCTCCAGAAATAAACCCTGAAACTCAAGCAGCTTTAATCAGAGGGCAGGATTCCACGATAGCAGCATCAGAACAGCAAGTGGCAGCGAGAATTCTTGATTCCAATGATCAGGCAACAGTAAACCCTGTGGAATTTAATACTGAGGTTGCAACACCACCATTTTCCCTTCTGGAGACTTCTAATGAAACAGATTTCCTGATTGGCATTAATGAAGAGTCAGTGGAAGGCACGGCAATCTATTTACCAGGACCTGATCGCTGCAAAATGAACCCGTGCCTTAACGGAGGCACCTGTTATCCTACTGAAACTTCCTACGTATGCACCTGTGTGCCAGGATACAGCGGAGACCAGTGTGAACTTGATTTTGATGAATGTCACTCTAATCCCTGTCGTAATGGAGCCACTTGTGTTGATGGTTTTAACACATTCAGGTGCCTCTGCCTTCCAAGTTATGTTGGTGCACTTTGTGAGCAAGATACCGAGACATGTGACTATGGCTGGCACAAATTCCAAGGGCAGTGCTACAAATACTTTGCCCATCGACGCACATGGGATGCAGCTGAACGGGAATGCCGTCTGCAGGGTGCCCATCTCACAAGCATCCTGTCTCACGAAGAACAAATGTTTGTTAATCGTGTGGGCCATGATTATCAGTGGATAGGCCTCAATGACAAGATGTTTGAGCATGACTTCCGTTGGACTGATGGCAGCACACTGCAATACGAGAATTGGAGACCCAACCAGCCAGACAGCTTCTTTTCTGCTGGAGAAGACTGTGTTGTAATCATTTGGCATGAGAATGGCCAGTGGAATGATGTTCCCTGCAATTACCATCTCACCTATACGTGCAAGAAAGGAACAGTCGCTTGCGGCCAGCCCCCTGTTGTAGAAAATGCCAAGACCTTTGGAAAGATGAAACCTCGTTATGAAATCAACTCCCTGATTAGATACCACTGCAAAGATGGTTTCATTCAACGTCACCTTCCAACTATCCGGTGCTTAGGAAATGGAAGATGGGCTATACCTAAAATTACCTGCATGAACCCATCTGCATACCAAAGGACTTATTCTATGAAATACTTTAAAAATTCCTCATCAGCAAAGGACAATTCAATAAATACATCCAAACATGATCATCGTTGGAGCCGGAGGTGGCAGGAGTCGAGGCGCTGA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.