NCBI Summary
This gene encodes a member of the calnexin family of molecular chaperones. The encoded protein is a calcium-binding, endoplasmic reticulum (ER)-associated protein that interacts transiently with newly synthesized N-linked glycoproteins, facilitating protein folding and assembly. It may also play a central role in the quality control of protein folding by retaining incorrectly folded protein subunits within the ER for degradation. Alternatively spliced transcript variants encoding different isoforms have been described. [provided by RefSeq, Jun 2018].
Protein
Protein (NP_001737)
Calnexin
Calnexin (IP90) (Major histocompatibility complex class I antigen-binding protein p88) (p90)
CANX
calnexin
Undefined
Curated
calnexin-calreticulin like
L-Type Lectins
b-sandwich / ConA-like
Glc(a1-3)Man(a1-2)Man(a1-2)Man / glucosylated N-glycan
0.608
MEGKWLLCMLLVLGTAIVEAHDGHDDDVIDIEDDLDDVIEEVEDSKPDTTAPPSSPKVTYKAPVPTGEVYFADSFDRGTLSGWILSKAKKDDTDDEIAKYDGKWEVEEMKESKLPGDKGLVLMSRAKHHAISAKLNKPFLFDTKPLIVQYEVNFQNGIECGGAYVKLLSKTPELNLDQFHDKTPYTIMFGPDKCGEDYKLHFIFRHKNPKTGIYEEKHAKRPDADLKTYFTDKKTHLYTLILNPDNSFEILVDQSVVNSGNLLNDMTPPVNPSREIEDPEDRKPEDWDERPKIPDPEAVKPDDWDEDAPAKIPDEEATKPEGWLDDEPEYVPDPDAEKPEDWDEDMDGEWEAPQIANPRCESAPGCGVWQRPVIDNPNYKGKWKPPMIDNPSYQGIWKPRKIPNPDFFEDLEPFRMTPFSAIGLELWSMTSDIFFDNFIICADRRIVDDWANDGWGLKKAADGAAEPGVVGQMIEAAEERPWLWVVYILTVALPVFLVILFCCSGKKQTSGMEYKKTDAPQPDVKEEEEEKEEEKDKGDEEEEGEEKLEEKQKSDAEEDGGTVSQEEEDRKPKAEEDEILNRSPRNRKPRRE
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
The location of the lectin domain structural model is: 68-466
We infer [0.3, 0.78] Å as the interval of error of this structural model.
Template 1: 1JHN chain: A, P24643, NP_001003232.1, sequence identity: 94.0%, coverage: 97.7%, location in sequence: 61-458, (61-458 in PDB).
Template 2: 6ENY chain: G, P27797, NP_004334.1, sequence identity: 38.6%, coverage: 84.2%, location in sequence: 18-386, (18-386 in PDB).
Template 3: 3O0W chain: A, P14211, NP_031617.1, sequence identity: 38.1%, coverage: 84.2%, location in sequence: 18-362, (18-362 in PDB).
Show the alignment used for the construction of the structural model, Download.
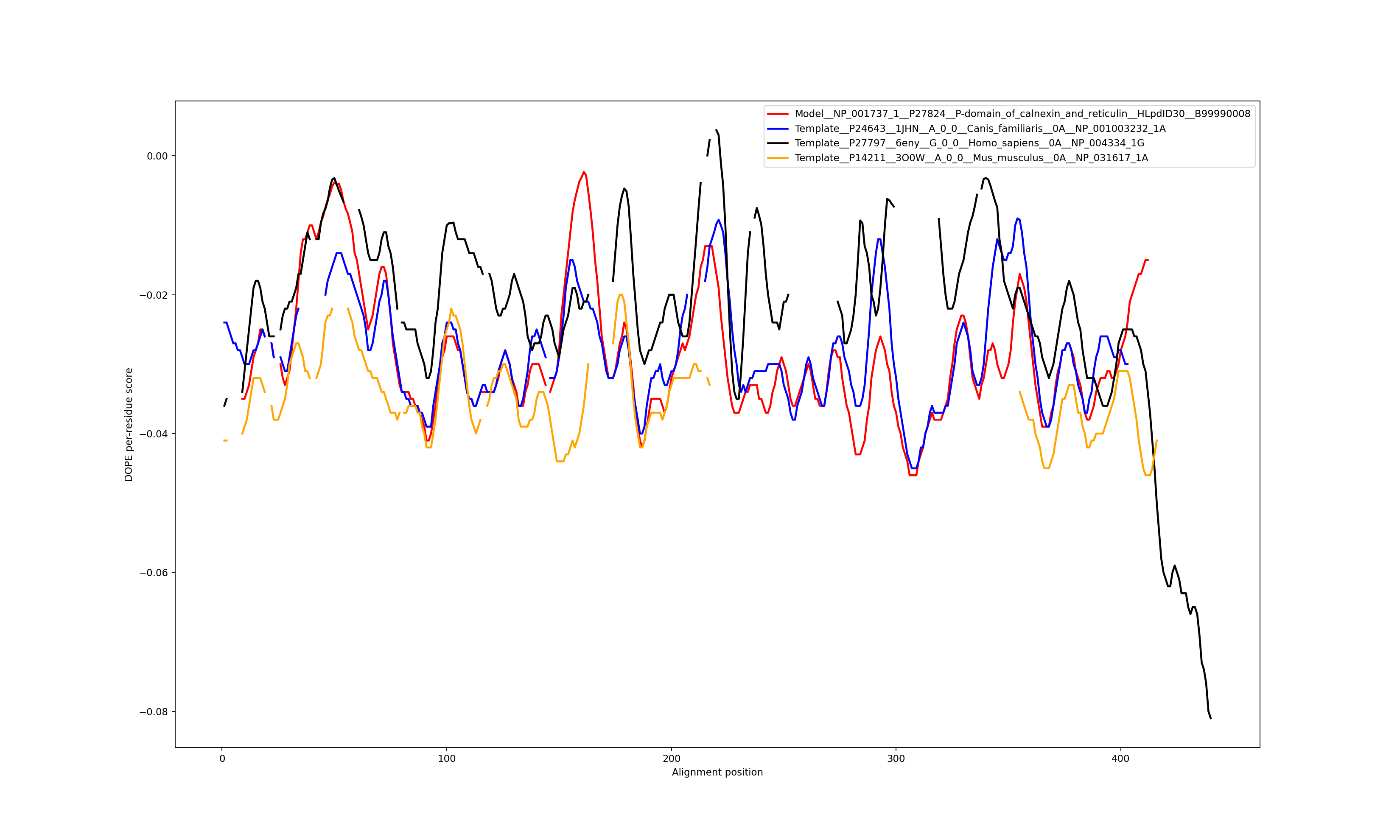
Show the plot of DOPE energy score, Download.
We infer [0.3, 0.78] Å as the interval of error of this structural model.
Template 1: 1JHN chain: A, P24643, NP_001003232.1, sequence identity: 94.0%, coverage: 97.7%, location in sequence: 61-458, (61-458 in PDB).
Template 2: 6ENY chain: G, P27797, NP_004334.1, sequence identity: 38.6%, coverage: 84.2%, location in sequence: 18-386, (18-386 in PDB).
Template 3: 3O0W chain: A, P14211, NP_031617.1, sequence identity: 38.1%, coverage: 84.2%, location in sequence: 18-362, (18-362 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
Interacts with MAPK3/ERK1 (By similarity). Interacts with KCNH2 (PubMed:16361248). Associates with ribosomes (By similarity). Interacts with SGIP1; involved in negative regulation of endocytosis (By similarity). The palmitoylated form interacts with the ribosome-translocon complex component SSR1, promoting efficient folding of glycoproteins (PubMed:22314232). Interacts with SERPINA2P/SERPINA2 and with the S and Z variants of SERPINA1 (PubMed:23826168). Interacts with PPIB (PubMed:20801878). Interacts with ZNRF4 (PubMed:21205830). Interacts with SMIM22 (PubMed:29765154). Interacts with TMX2 (PubMed:31735293). Interacts with TMEM35A/NACHO (By similarity). Interacts with CHRNA7 (PubMed:32783947). Interacts with reticulophagy regulators RETREG2 and RETREG3 (PubMed:34338405). Interacts with DNM1L; may form part of a larger protein complex at the ER-mitochondrial interface during mitochondrial fission (PubMed:24196833). Interacts with ADAM7 (By similarity)
(Microbial infection) Interacts with HBV large envelope protein, isoform L
(Microbial infection) Interacts with HBV large envelope protein, isoform M; this association may be essential for isoform M proper secretion
(Microbial infection) Interacts with HBV large envelope protein, isoform L
(Microbial infection) Interacts with HBV large envelope protein, isoform M; this association may be essential for isoform M proper secretion
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- Circulating small extracellular vesicles increase after an acute bout of moderate-intensity exercise in pregnant compared to non-pregnant women. [34135428]
- Ca2+ Regulates ERp57-Calnexin Complex Formation. [34064874]
- The Role of Cardiolipin as a Scaffold Mitochondrial Phospholipid in Autophagosome Formation: In Vitro Evidence. [33562550]
- Calnexin mediates the maturation of GPI-anchors through ER retention. [32967966]
- ER-resident oxidoreductases are glycosylated and trafficked to the cell surface to promote matrix degradation by tumour cells. [33077910]
- The integrin chains beta 1 and alpha 6 associate with the chaperone calnexin prior to integrin assembly. [8163531]
- Human, mouse, and rat calnexin cDNA cloning: identification of potential calcium binding motifs and gene localization to human chromosome 5. [8136357]
- The molecular chaperones HSP28, GRP78, endoplasmin, and calnexin exhibit strikingly different levels in quiescent keratinocytes as compared to their proliferating normal and transformed counterparts: cDNA cloning and expression of calnexin. [8055875]
- Microsequences of 145 proteins recorded in the two-dimensional gel protein database of normal human epidermal keratinocytes. [1286667]
- The major histocompatibility complex class I antigen-binding protein p88 is the product of the calnexin gene. [1326756]
UniProt Main References (30 PubMed Identifiers)
- Interaction with newly synthesized and retained proteins in the endoplasmic reticulum suggests a chaperone function for human integral membrane protein IP90 (calnexin). [8486646]
- Complete sequencing and characterization of 21,243 full-length human cDNAs. [14702039]
- The DNA sequence and comparative analysis of human chromosome 5. [15372022]
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
- Formation of intracellular particles by hepatitis B virus large surface protein. [9188622]
- Role for calnexin and N-linked glycosylation in the assembly and secretion of hepatitis B virus middle envelope protein particles. [9420286]
- Proteomic analysis of early melanosomes: identification of novel melanosomal proteins. [12643545]
- Global, in vivo, and site-specific phosphorylation dynamics in signaling networks. [17081983]
- Mechanisms of pharmacological rescue of trafficking-defective hERG mutant channels in human long QT syndrome. [16361248]
- Proteomic and bioinformatic characterization of the biogenesis and function of melanosomes. [17081065] Show more
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_001746.4)
m7G-5')ppp(5'-AGCGGUGGCCGAGGCCUCUUGGUUCUGCGGCACGUGACGGUCGGGCCGCCUCCGCCUCUCUCUUUACUGCGGCGCGGGGCAAGGUGUGCGGGCGGGAAGGGGCACGGGCACCCCCGCGGUCCCCGGGAGGCUAGAGAUCAUGGAAGGGAAGUGGUUGCUGUGUAUGUUACUGGUGCUUGGAACUGCUAUUGUUGAGGCUCAUGAUGGACAUGAUGAUGAUGUGAUUGAUAUUGAGGAUGACCUUGACGAUGUCAUUGAAGAGGUAGAAGACUCAAAACCAGAUACCACUGCUCCUCCUUCAUCUCCCAAGGUUACUUACAAAGCUCCAGUUCCAACAGGGGAAGUAUAUUUUGCUGAUUCUUUUGACAGAGGAACUCUGUCAGGGUGGAUUUUAUCCAAAGCCAAGAAAGACGAUACCGAUGAUGAAAUUGCCAAAUAUGAUGGAAAGUGGGAGGUAGAGGAAAUGAAGGAGUCAAAGCUUCCAGGUGAUAAAGGACUUGUGUUGAUGUCUCGGGCCAAGCAUCAUGCCAUCUCUGCUAAACUGAACAAGCCCUUCCUGUUUGACACCAAGCCUCUCAUUGUUCAGUAUGAGGUUAAUUUCCAAAAUGGAAUAGAAUGUGGUGGUGCCUAUGUGAAACUGCUUUCUAAAACACCAGAACUCAACCUGGAUCAGUUCCAUGACAAGACCCCUUAUACGAUUAUGUUUGGUCCAGAUAAAUGUGGAGAGGACUAUAAACUGCACUUCAUCUUCCGACACAAAAACCCCAAAACGGGUAUCUAUGAAGAAAAACAUGCUAAGAGGCCAGAUGCAGAUCUGAAGACCUAUUUUACUGAUAAGAAAACACAUCUUUACACACUAAUCUUGAAUCCAGAUAAUAGUUUUGAAAUACUGGUUGACCAAUCUGUGGUGAAUAGUGGAAAUCUGCUCAAUGACAUGACUCCUCCUGUAAAUCCUUCACGUGAAAUUGAGGACCCAGAAGACCGGAAGCCCGAGGAUUGGGAUGAAAGACCAAAAAUCCCAGAUCCAGAAGCUGUCAAGCCAGAUGACUGGGAUGAAGAUGCCCCUGCUAAGAUUCCAGAUGAAGAGGCCACAAAACCCGAAGGCUGGUUAGAUGAUGAGCCUGAGUACGUACCUGAUCCAGACGCAGAGAAACCUGAGGAUUGGGAUGAAGACAUGGAUGGAGAAUGGGAGGCUCCUCAGAUUGCCAACCCUAGAUGUGAGUCAGCUCCUGGAUGUGGUGUCUGGCAGCGACCUGUGAUUGACAACCCCAAUUAUAAAGGCAAAUGGAAGCCUCCUAUGAUUGACAAUCCCAGUUACCAGGGAAUCUGGAAACCCAGGAAAAUACCAAAUCCAGAUUUCUUUGAAGAUCUGGAACCUUUCAGAAUGACUCCUUUUAGUGCUAUUGGUUUGGAGCUGUGGUCCAUGACCUCUGACAUUUUUUUUGACAACUUUAUCAUUUGUGCUGAUCGAAGAAUAGUUGAUGAUUGGGCCAAUGAUGGAUGGGGCCUGAAGAAAGCUGCUGAUGGGGCUGCUGAGCCAGGCGUUGUGGGGCAGAUGAUCGAGGCAGCUGAAGAGCGCCCGUGGCUGUGGGUAGUCUAUAUUCUAACUGUAGCCCUUCCUGUGUUCCUGGUUAUCCUCUUCUGCUGUUCUGGAAAGAAACAGACCAGUGGUAUGGAGUAUAAGAAAACUGAUGCACCUCAACCGGAUGUGAAGGAAGAGGAAGAAGAGAAGGAAGAGGAAAAGGACAAGGGAGAUGAGGAGGAGGAAGGAGAAGAGAAACUUGAAGAGAAACAGAAAAGUGAUGCUGAAGAAGAUGGUGGCACUGUCAGUCAAGAGGAGGAAGACAGAAAACCUAAAGCAGAGGAGGAUGAAAUUUUGAACAGAUCACCAAGAAACAGAAAGCCACGAAGAGAGUGAAACAAUCUUAAGAGCUUGAUCUGUGAUUUCUUCUCCCUCCUCCCCUGCAAGAGUGGUCCUAGGAGAGGACCUGGCACACCUUAGGUUGACAUUCAGAAAACUUCAAGACAUCACCAUCAGCAGGCUCCAGUUGAACACUAGUCUGUGUAACUUUAAACAUCUAGCAGUAAAUACUUGCAGUUGUGAUAUAAAGGACCCUGUUUCUGUAGAAAAGAAAACAUUUAACAUAAUGGUUGUGAAAUGUAACAUGAAGCAAACUAACUUUUUUUUUUUUAACAUCUUUGUUUUUAAAAUAGAAUGAUAGAACUUUGCCAGUCUUUAAGAUCUUGGCUUAAUUUAAUGUAUUAAUCUGUUUGUGCAAACAUAAUACCACCAUUUAAAAAUGUUAGGGAGAUGAGUUGCAGUUUUUAUAAUAGAUUUUUUUUAAAGUUUGGUAUUGUAAAACAUUCACACCUCUGUCCCUCAAAAUUGAUAAUUACGUUUAAAGUGCAGUCAUUUGUGGUUAGAAUCUUGUUUUGUUUGCUUCCAUUAUUGAGUUCCUCCUAAGGAAAUUGAGGAGAGGGACUGAAUAGAAGCCCAAAUUCAUAUAAAAGUUGCGUUUAAGUUGUAUUAAAAAUAGAUAUAUAAGAAAAAAUUCUUUCACUUGAUGUUUGUUAGACCAGAAAGUGUGUGUGUUCUGUAGCUCAGUUCCCAGACAGCUUUUUAGGUAGUGGAGGAGGUGGCUUCAUGUGGCACUUGGGCAUUUAUAUUCCACUUGGGAGGGUCAGGCUGUGGCCUUCUGGAGCAGGUGGCUUGUUAAGGAAUGCUAGCAGGGCAUGGCACGUGAGCUCCGGAAUAGAUGUCUUCAUCACUUCUUCCACUGUGUGUUGACACUGUUUUCCUUACCUAUUUCCUCAGAUCCCCAGCUUUCUCCUCUGCUAUGCAUUUUCUUCACAGUGCAGCUUGCAGUCCGUUGCUGAAAAUGAUUAUAAGCCCUGCAUAAUGUUAAGCUUUAUUGUGAUUACGUGUAUGUUUCUUCUUUCUUUUAAGCAGACCCAUACCUUUCCAGGGUCAAAGUACAGAAUAGAAUACAUUGAUACAAAGUACAGAAAAAUACUUUGAUUUUUAUCCAUUUCUUUUACUCUGUGUAAAGACUUGAGAAGUCUAAUUCACAGGCAAACCAAUACAGAAUUGACUGCAGUUGAACAGACUAGAAGUAUUUGUGGGAGGAGUGACAUGAAGCAUGAGUUAUCUGAUUUUUUUUGUAGCUGCUAUAUAUUUUAAGCCUUCAUUUGCAAUUCAUGUAACAGUUGUGUCAUAAAUUACACAAUAAAGCAGUCCUGUUCAAAUUUUUUUUUAACGUGGCUUGUAGAAUUUUUAAAAAAGUGAUCUUAGGUUUGUUUUUUCAUGCGGGAUGCAGAUGGGUGCUAUCAGAGCCUCUCCCACACCACUAUAGUGUAAUAAUGUUAUUAUUACUCUACACUGAAACGUAUUCAGAGUUAGAUAUUAUUUUAGCUUCAGUUGUUCUUUAGAGGCUUUCAAAUGUACCGAUGAUACUGUUUCUUGCACUGAAUAUAUAAACACUCCACAGUGUUUAUAUUGGGAAGAUAUUGGGAAGGAAAUAUAUUUGUAAAAGAUGAAGGCUGUAUCUAUUUUUUUUUCUUUUUAAAGUUUGUUCACUUAAAUUCUUUUGAGGAUGGGAUGUAUUUUUCUUGCUGUUCAGUGCUUUUUCCUUUUCAUCUGUUGUUCUGUGGUCACAGUGACCUUAGCUACAUAGCAGACUUUCCCAAAUGUAUUGAUUACAAAUAAACAGUUGUUACUUAGCAAGACCUGAAAAUAUGUCUGCAGGUUUCUCCUUGAAGCAAAUGUGUGGGAUCAUUGCAUUUCCAGAAAUCUGCCUCCUUCACCCUCCGUUGACAGUAUAUGUCAUGCCUCACUUUCUUCUAGCUGAGCUUUAAAUCAUUAGAGCUUAAAUUGUCAGAUCGUUCAUUGCCUUUCCAGGGUUAUUUAGUAAAGUUUGUUGAAAACAAAAACGCCUUUUCUUGGUUCUUUUUUCAGUUAUUUUGAAGGUCCAGCAUCCUGAUUAAAUGUCUGACACAUUAAUGAAUGACCAGCAGCAGCUUUCAGCUCUUAAAAAGACACUUAUAUUUUGAUUUUACAUGCUGGUUACCUGUUCCAUUGUUGUCAAAUGCCCACUCUCCAUCAGAUGUGUUCCUCCAUUUUCUUAUCCACAAAGUACUCCUCACUUUUCAAUUUGUCAUGUUACUAAAUGGUGUUACAUUAAAGCCCUGUGUUAAGUGUCUGCUUUUGACUGAAUUUCUUCAUAGUAACCUUCAGUGUGUGUGUGUGACUAUGUUCAAUUAGUGGGUUGAUCUUCGUAUAAUUGGCCACUAUGUGAGAGUUCACUACUAGGCAGAAACUAUUAUGGACAGUGAAAUAAUGACUUUUAUCUCACCACGUGAGUUUGAUGCAGUCUUUUCUGUCUAGCCCUUGCCUCUUCCUGCCCAUGUGAUUGCGGUGCAGUAGUUUCUGUUGUAUAAUAGUGUGGACAGCAGCUCAGAAAAGGAGGGAAUGCUACUGAUAAUUUGUAGAUAAUAUUCUUUAAGACUUAGGGGAACCAUUGAACUUUGAAAUUUUUAUUAGAAAAUUAUUUGUUCAGAAUCAGACUCCAUUAUUUUACAUAUACUUAAAUACUUUAGGGGUAUUUUUGAAAGUUAGCCCAGUUUUUUAUGUGCUAUUAAAUUUUUAGAUUACAUACUAAAGAAAAGUAUGUACACAGAAUGUAGUGCUCCUAGUUACUAUUUUUUCUAUUAAGAAAUAGUUUAGUUCUGGUGUAAAAUUUGUUUGAAUGCUAAAAAAAAAAAAGCAGGACUGCAUUAUGGCACUUUUGCCUUGGUGGCCCACUUUCUCCAUUUAAAACAUUAGGAUUUGUAUUUUUCUGCUGCGUUUGUAUGAAGACAUAUUUGAUUGUUGUUUUCUCUUGAUUUUAAAAUAAAACCUCAUGAGCCCUAGUAAAAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 821)
calnexin
strand +
CNX, IP90, P90
NCBI CDS gene sequence (1779 bp)
5'-ATGGAAGGGAAGTGGTTGCTGTGTATGTTACTGGTGCTTGGAACTGCTATTGTTGAGGCTCATGATGGACATGATGATGATGTGATTGATATTGAGGATGACCTTGACGATGTCATTGAAGAGGTAGAAGACTCAAAACCAGATACCACTGCTCCTCCTTCATCTCCCAAGGTTACTTACAAAGCTCCAGTTCCAACAGGGGAAGTATATTTTGCTGATTCTTTTGACAGAGGAACTCTGTCAGGGTGGATTTTATCCAAAGCCAAGAAAGACGATACCGATGATGAAATTGCCAAATATGATGGAAAGTGGGAGGTAGAGGAAATGAAGGAGTCAAAGCTTCCAGGTGATAAAGGACTTGTGTTGATGTCTCGGGCCAAGCATCATGCCATCTCTGCTAAACTGAACAAGCCCTTCCTGTTTGACACCAAGCCTCTCATTGTTCAGTATGAGGTTAATTTCCAAAATGGAATAGAATGTGGTGGTGCCTATGTGAAACTGCTTTCTAAAACACCAGAACTCAACCTGGATCAGTTCCATGACAAGACCCCTTATACGATTATGTTTGGTCCAGATAAATGTGGAGAGGACTATAAACTGCACTTCATCTTCCGACACAAAAACCCCAAAACGGGTATCTATGAAGAAAAACATGCTAAGAGGCCAGATGCAGATCTGAAGACCTATTTTACTGATAAGAAAACACATCTTTACACACTAATCTTGAATCCAGATAATAGTTTTGAAATACTGGTTGACCAATCTGTGGTGAATAGTGGAAATCTGCTCAATGACATGACTCCTCCTGTAAATCCTTCACGTGAAATTGAGGACCCAGAAGACCGGAAGCCCGAGGATTGGGATGAAAGACCAAAAATCCCAGATCCAGAAGCTGTCAAGCCAGATGACTGGGATGAAGATGCCCCTGCTAAGATTCCAGATGAAGAGGCCACAAAACCCGAAGGCTGGTTAGATGATGAGCCTGAGTACGTACCTGATCCAGACGCAGAGAAACCTGAGGATTGGGATGAAGACATGGATGGAGAATGGGAGGCTCCTCAGATTGCCAACCCTAGATGTGAGTCAGCTCCTGGATGTGGTGTCTGGCAGCGACCTGTGATTGACAACCCCAATTATAAAGGCAAATGGAAGCCTCCTATGATTGACAATCCCAGTTACCAGGGAATCTGGAAACCCAGGAAAATACCAAATCCAGATTTCTTTGAAGATCTGGAACCTTTCAGAATGACTCCTTTTAGTGCTATTGGTTTGGAGCTGTGGTCCATGACCTCTGACATTTTTTTTGACAACTTTATCATTTGTGCTGATCGAAGAATAGTTGATGATTGGGCCAATGATGGATGGGGCCTGAAGAAAGCTGCTGATGGGGCTGCTGAGCCAGGCGTTGTGGGGCAGATGATCGAGGCAGCTGAAGAGCGCCCGTGGCTGTGGGTAGTCTATATTCTAACTGTAGCCCTTCCTGTGTTCCTGGTTATCCTCTTCTGCTGTTCTGGAAAGAAACAGACCAGTGGTATGGAGTATAAGAAAACTGATGCACCTCAACCGGATGTGAAGGAAGAGGAAGAAGAGAAGGAAGAGGAAAAGGACAAGGGAGATGAGGAGGAGGAAGGAGAAGAGAAACTTGAAGAGAAACAGAAAAGTGATGCTGAAGAAGATGGTGGCACTGTCAGTCAAGAGGAGGAAGACAGAAAACCTAAAGCAGAGGAGGATGAAATTTTGAACAGATCACCAAGAAACAGAAAGCCACGAAGAGAGTGA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.