NCBI Summary
This RefSeq record was created from transcript and genomic sequence data to make the sequence consistent with the reference genome assembly. The genomic coordinates used for the transcript record were based on transcript alignments.
Protein
Protein (NP_001335293)
SIGLEC-16
Sialic acid-binding Ig-like lectin 16 (Siglec-16) (Siglec-P16)
SIGLEC16
sialic acid binding Ig like lectin 16
Undefined
Curated
I-type lectin
I-Type Lectins - CD33-related Siglecs
b-sandwich / Ig-like
NeuAc / Neu5Ac(a2-8)Neu5Ac(a2-3)Gal
Undefined
0.495
MLLLPLLLPVLGAGSLNKDPSYSLQVQRQVPVPEGLCVIVSCNLSYPRDGWDESTAAYGYWFKGWTSPKTGAPVATNNQSREVEMSTRDRFQLTGDPGKGSCSLVIRDAQREDEAWYFFRVERGSRVRHSFVNNLFFLKVTALTQKPDVYIPETLEPGQPVTVICVFNWAFKKCPAPSFSWTGAALSPRRTRPSTSHFSVLSFTPSPQDHDTDLTCHVDFSRKGVSAQRTVRLRVASLELQGNVIYLEVQKGQFLRLLCAADSQPPATLSWVLQDRVLSSSHPWGPRTLGLELRGVRAGDSGRYTCRAENRLGSQQRALDLSVQYPPENLRVMVSQANRTVLENLRNGTSLRVLEGQSLRLVCVTHSSPPARLSWTRWGQTVGPSQPSDPGVLELPRVQMEHEGEFTCHARHPLGSQRVSLSFSVHCKSGPMTGVVLVAVGEVAMKILLLCLCLILLRVRSCRRKAARAALGMEAADAVTD
No structure currently available in the PDB RCSB Databank.
Structural models
AlphaFold v2: AF-A6NMB1-F1DownloadSee the associated sequence to the AlphaFold v2 model, which is different to this entry(NCBI sequence).
SWISS-MODEL structural models
The location of the lectin domain structural model is: 19-147
We infer [1.26, 1.53] Å as the interval of error of this structural model.
Template 1: 2N7B chain: A, Q9NYZ4, NP_055257.2, sequence identity: 48.8%, coverage: 93.8%, location in sequence: 26-152, (10-136 in PDB).
Template 2: 2ZG1 chain: A, O15389, NP_003821.1, sequence identity: 47.3%, coverage: 94.6%, location in sequence: 20-141, (25-146 in PDB).
Template 3: 6D4A chain: B, P20138, NP_001763.3, sequence identity: 41.9%, coverage: 96.1%, location in sequence: 18-141, (18-141 in PDB).
Show the alignment used for the construction of the structural model, Download.
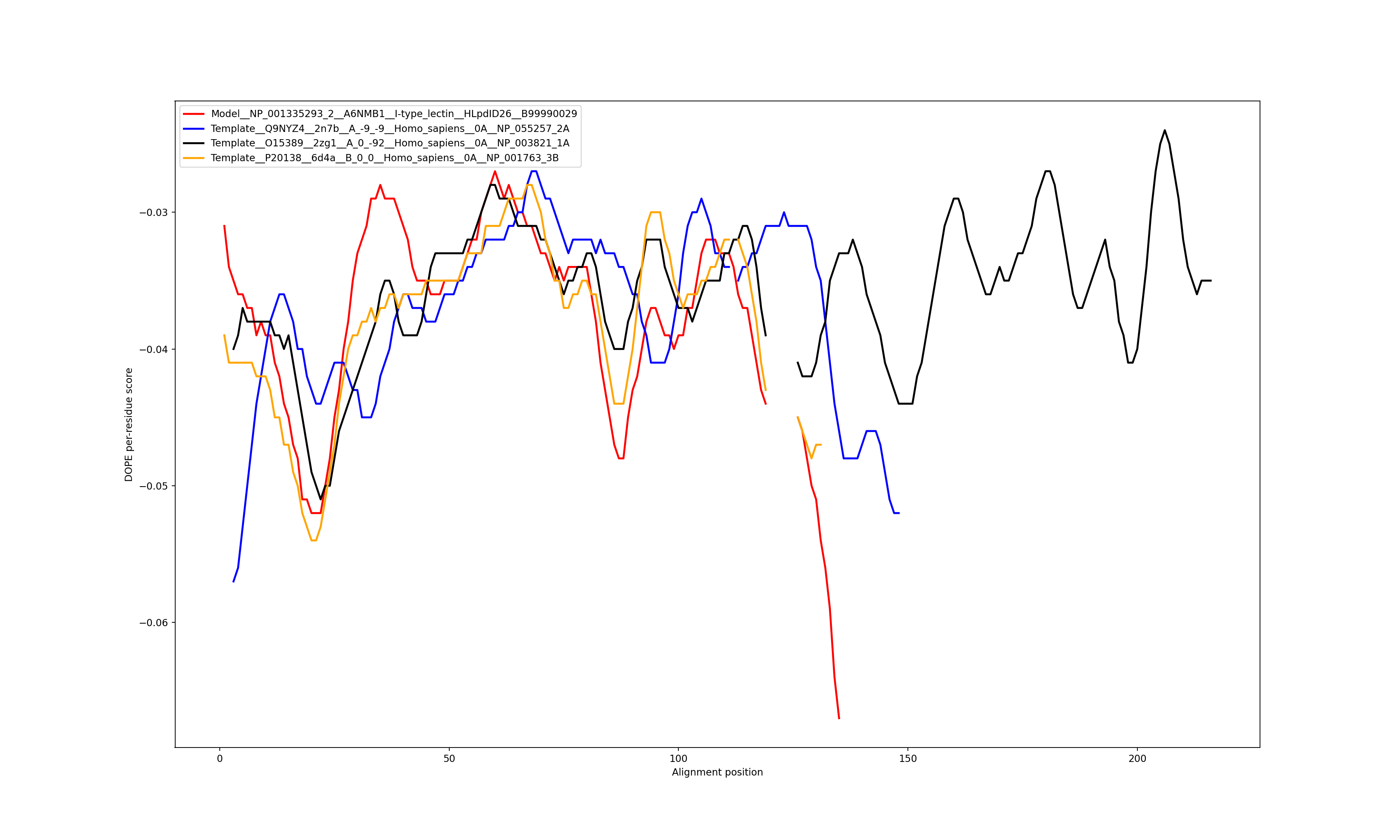
Show the plot of DOPE energy score, Download.
We infer [1.26, 1.53] Å as the interval of error of this structural model.
Template 1: 2N7B chain: A, Q9NYZ4, NP_055257.2, sequence identity: 48.8%, coverage: 93.8%, location in sequence: 26-152, (10-136 in PDB).
Template 2: 2ZG1 chain: A, O15389, NP_003821.1, sequence identity: 47.3%, coverage: 94.6%, location in sequence: 20-141, (25-146 in PDB).
Template 3: 6D4A chain: B, P20138, NP_001763.3, sequence identity: 41.9%, coverage: 96.1%, location in sequence: 18-141, (18-141 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (7 PubMed Identifiers)
- Paired Siglec receptors generate opposite inflammatory responses to a human-specific pathogen. [28100677]
- Evolution of siglec-11 and siglec-16 genes in hominins. [22383531]
- SIGLEC16 encodes a DAP12-associated receptor expressed in macrophages that evolved from its inhibitory counterpart SIGLEC11 and has functional and non-functional alleles in humans. [18629938]
- A human-specific gene in microglia. [16151003]
- The DNA sequence and biology of human chromosome 19. [15057824]
- Cloning and characterization of human Siglec-11. A recently evolved signaling molecule that can interact with SHP-1 and SHP-2 and is expressed by tissue macrophages, including brain microglia. [11986327]
- A second uniquely human mutation affecting sialic acid biology. [11546777]
UniProt Main References (1 PubMed Identifiers)
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
RNA
RNA (Transcript ID: NM_001348364.2)
sialic acid binding Ig like lectin 16, transcript variant 1
m7G-5')ppp(5'-AGAUGGUCCCGGGACAGGCCCAGCCCCAGAGCCCAGAGAUGCUGCUGCUGCCCCUGCUGCUGCCCGUGCUGGGGGCGGGGUCCCUGAACAAGGAUCCCAGUUACAGUCUUCAAGUGCAGAGGCAGGUGCCGGUGCCGGAGGGCCUGUGUGUCAUCGUGUCUUGCAACCUCUCCUACCCCCGGGAUGGCUGGGACGAGUCUACUGCUGCUUAUGGCUACUGGUUCAAAGGAUGGACCAGCCCAAAGACGGGUGCUCCUGUGGCCACUAACAACCAGAGUCGAGAGGUGGAAAUGAGCACCCGGGACCGAUUCCAGCUCACUGGGGAUCCCGGCAAAGGGAGCUGCUCCUUGGUGAUCAGAGACGCGCAGAGGGAGGAUGAGGCAUGGUACUUCUUUCGGGUGGAGAGAGGAAGCCGUGUGAGACAUAGUUUCGUGAACAAUUUGUUAAAAGUAACAGCCCUGACUCAGAAGCCUGAUGUCUACAUCCCCGAGACCCUGGAGCCCGGGCAGCCGGUGACGGUCAUCUGUGUGUUUAACUGGGCUUUCAAGAAAUGUCCAGCCCCUUCUUUCUCCUGGACGGGGGCUGCCCUCUCCCCUAGAAGAACCAGACCAAGCACCUCCCACUUCUCAGUGCUCAGCUUCACGCCCAGCCCCCAGGACCACGACACCGACCUCACCUGCCAUGUGGACUUCUCCAGAAAGGGUGUGAGCGCACAGAGGACCGUCCGACUCCGUGUGGCCUCCCUGGAACUCCAGGGAAACGUCAUAUAUCUGGAAGUUCAGAAAGGCCAGUUCCUGCGGCUCCUCUGUGCUGCUGACAGCCAGCCCCCUGCCACGCUGAGCUGGGUCCUGCAGGACAGAGUCCUCUCCUCGUCCCACCCCUGGGGCCCCAGAACCCUGGGGCUGGAGCUGCGUGGGGUAAGGGCCGGGGAUUCAGGGCGCUACACCUGCCGAGCGGAGAACAGGCUUGGCUCCCAGCAGCGAGCCCUGGACCUCUCUGUGCAGUAUCCUCCAGAGAACCUGAGAGUGAUGGUUUCCCAAGCAAACAGGACAGUCCUGGAAAACCUGAGGAACGGCACAUCCCUCCGGGUCCUGGAGGGCCAAAGCCUGCGUCUGGUCUGUGUCACACACAGCAGCCCCCCAGCCAGGCUGAGCUGGACCCGGUGGGGACAGACCGUGGGCCCCUCCCAGCCCUCAGACCCUGGGGUCCUGGAGCUGCCUCGGGUUCAAAUGGAGCACGAAGGAGAGUUCACCUGCCACGCUCGGCACCCGCUGGGCUCCCAGCGCGUCUCUCUCAGCUUCUCCGUGCACUGCAAAUCAGGGCCCAUGACGGGGGUGGUUCUGGUGGCUGUUGGGGAGGUGGCUAUGAAGAUCCUGCUUCUCUGCCUCUGCCUCAUCCUCCUCAGAGUGAGGUCUUGCAGGAGGAAGGCAGCAAGGGCAGCAUUGGGCAUGGAGGCUGCAGACGCUGUCACGGACUAAUCUCCAGACUCCAGACUGCUUCCAGAUGCCUCCUCAUCCAGUUCCUCCACAGUCUGAGCGGCCGUGUUUCCUCUGCAGGCUUUGCAUGGUCUGUCCCCUGCUGGACUCUCCUGAUCCCUCCUUUCCCUGUCACCCAACAUCUCCCCAAACCCUCCGGGCCAAGGACUCUGCGGCUCUUGACACUUUGCACGUGUAGUUUCUUCUCCUGAAACACCCUUCCCUCCUGCCAAACCACGUCUGGACCCUCCUUCAGGUUCACUUUUUUUUUUUUUUUUUGAGACACAGUCUCACUUUGUCACCCAGGCUGGAGUGCAGUGGCGCGAUCUCGGCUCACUGCAACCUCUGUCUCCCAGGUUCAAGCGAUUCUCAUGUCUCAGCCUCCUGAGUAGCUGGGAUUAUAGGCGCCCGCCACCACGCCUGGCUCAUUUUUGUAUUUUUGGUAGAGACAGGGUUUCACCAUGUCGGCCAGGCUGGUCUUGAACUCCCGACUUCAGGUGAUCCGCCAGCCUCGGCCUCCCAAAGUGGUGGGGUUACAUGUGUGAGCCACCGUGCCCAGCCAGCUGUGUCUUCUUUUUGCAGGAUUUACUUACAAAAUUCCUUGCAGCUGCAGUCUGCGUUCCACCCACAUCCUAAUAUGGUGUUUGCGGUGGUCACAUCCAACUUCCUUCCUCCUCCAUCCAUGGAACGUGCAUUAGGGAGGAACCACACGCACCACGUGCAAGAUGAGCCAGUUCCCUGAACGGCCGGCCACGGCGUUAACCGCGCUGCUCUGGGCUCUGCACGUCUCAUCUGCUGAGGCGCAUUACUGCAUCUUUCAUGCAGAACUUGCUUUCCAUGCCUCACAUCUCCACAUGUGUGGGGAUAUGUCCUGAGAAAUGCACGGUUAGGUGAUUCUGUCGUGUGAGCAUCCUUGAAUGUGCUUACACAGUCAUAAAUGGUACAGCCUACCACACGCCGAGGCUAUACGGUAUAGCCCAUUGCUCCUAGACUAUACACCUGCACGGCAUGUUCCUGUAGUGAAAGCUGUAGGCAAUUAUAACGCAAUGGAUAGGUUAAAGACAGAGUUUUAGUAAAAAUAUGGCAUAAUAGGCCAGGCGUGGUGGCUCAUGCCUGUAAUCCCAGCACUUUGGGAGGCCAAGGCAGGCAGAUCACAAGGUCAGGAGUUUGAGACCAGCCUGGCCAAUAUGGUGAAACCCAGUCUCUACUAAAAAUACAAAAAUUAGCCGGGUGUGGUGGCGGGCGCCUGUAGUCCCAGCUACUCGGGAGGCUGAGGCAGAAGAAUCAUUUGAACCAGGAGGUGGAGGUUGCAGUGAGCCGAGAUCGCAUCACUGCACUCCAGCCUGGGCGACAGAGCAAGACUGUCUCAAAAACUAAAACAAAAAAACACCACCACCACCACCAAUGUCUGAUUAAAUCUAAGCCACGGUUCCAUUUUGGGGCAAGGGGCAGGGUGUGGGUGUGGUGGACAGAGAACGGGCUCCAGCCACCAUCAGCUGCACGUCCUGGUAGCACCUGAGCCAUUCCCAGUCUCCUGUGCUGGGAGAUCAUCAUCUAAUCCUGAUGAUGACGCCCUCCUCUCAGAGCUCGGGGGAUGAGCUGCCAAAACCCAUGGAGGUUCAAAACCCGGGCUCUGGAGACAGAAGACACUGGGCUCAGAGACAUGGGGCCACUGUCCAGGCUUUCCCUGGGCCUGGACCUGGGCUCCUUCCACUGUCUGAGCAGGGUCAGCCUGGGCUGGCUGUGCUGGUUCAAGAGAUGAGGGAGGAGGACACAGCGGUUGCCAGGACCCUGAGGCACUGGACUGGGCACUGCCCCAAGGGGCAGAGGAUGGAACCCGGUGUUGAUAUUGUGAUGCUGACCCGUCUGCUCACCUGAUUUGGGUGCUGAAGGGCAGCUGACCCCCCUAAUCUUUUAUAGACUUGUGAAACGAAAAUAAAUAAAAGUCAAGCUGGGAACAGCUUAGGGCAAACCUGCCUCCCAUUCUAUUCAAAGCCACCCCUCUGCUCACUGAGAUAGAUGCAUGUCUGAUCACCUCAGUUGGGAAAGGCUAAUCAGAAACUCCAAAGAAUGCAUCUGUUCAUCUCUCACCCAUCUGUGACCUGGAAGCCCCCUCCCCACUUCGAGUCUUCCUGCCUUUGCUUCAAGUUUUCCCGCCUUUCCAAAUGGAACCAAAGUACUUCUUACAUAUAGUGACUCAUGUCUCAAGUCUCCCUAAAACGUAUAAAACUAAGCUGUGCCCCAACCACGCUGACCAUGUCAUCAGGACCUCCUGAGGCUGUGUCACGGCCUGUGUCCUCAACCUUGGCAAAAUAAACUUUCUAAAUUAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 400709)
sialic acid binding Ig like lectin 16
strand +
NCBI CDS gene sequence (1440 bp)
5'-ATGCTGCTGCTGCCCCTGCTGCTGCCCGTGCTGGGGGCGGGGTCCCTGAACAAGGATCCCAGTTACAGTCTTCAAGTGCAGAGGCAGGTGCCGGTGCCGGAGGGCCTGTGTGTCATCGTGTCTTGCAACCTCTCCTACCCCCGGGATGGCTGGGACGAGTCTACTGCTGCTTATGGCTACTGGTTCAAAGGATGGACCAGCCCAAAGACGGGTGCTCCTGTGGCCACTAACAACCAGAGTCGAGAGGTGGAAATGAGCACCCGGGACCGATTCCAGCTCACTGGGGATCCCGGCAAAGGGAGCTGCTCCTTGGTGATCAGAGACGCGCAGAGGGAGGATGAGGCATGGTACTTCTTTCGGGTGGAGAGAGGAAGCCGTGTGAGACATAGTTTCGTGAACAATTTGTTAAAAGTAACAGCCCTGACTCAGAAGCCTGATGTCTACATCCCCGAGACCCTGGAGCCCGGGCAGCCGGTGACGGTCATCTGTGTGTTTAACTGGGCTTTCAAGAAATGTCCAGCCCCTTCTTTCTCCTGGACGGGGGCTGCCCTCTCCCCTAGAAGAACCAGACCAAGCACCTCCCACTTCTCAGTGCTCAGCTTCACGCCCAGCCCCCAGGACCACGACACCGACCTCACCTGCCATGTGGACTTCTCCAGAAAGGGTGTGAGCGCACAGAGGACCGTCCGACTCCGTGTGGCCTCCCTGGAACTCCAGGGAAACGTCATATATCTGGAAGTTCAGAAAGGCCAGTTCCTGCGGCTCCTCTGTGCTGCTGACAGCCAGCCCCCTGCCACGCTGAGCTGGGTCCTGCAGGACAGAGTCCTCTCCTCGTCCCACCCCTGGGGCCCCAGAACCCTGGGGCTGGAGCTGCGTGGGGTAAGGGCCGGGGATTCAGGGCGCTACACCTGCCGAGCGGAGAACAGGCTTGGCTCCCAGCAGCGAGCCCTGGACCTCTCTGTGCAGTATCCTCCAGAGAACCTGAGAGTGATGGTTTCCCAAGCAAACAGGACAGTCCTGGAAAACCTGAGGAACGGCACATCCCTCCGGGTCCTGGAGGGCCAAAGCCTGCGTCTGGTCTGTGTCACACACAGCAGCCCCCCAGCCAGGCTGAGCTGGACCCGGTGGGGACAGACCGTGGGCCCCTCCCAGCCCTCAGACCCTGGGGTCCTGGAGCTGCCTCGGGTTCAAATGGAGCACGAAGGAGAGTTCACCTGCCACGCTCGGCACCCGCTGGGCTCCCAGCGCGTCTCTCTCAGCTTCTCCGTGCACTGCAAATCAGGGCCCATGACGGGGGTGGTTCTGGTGGCTGTTGGGGAGGTGGCTATGAAGATCCTGCTTCTCTGCCTCTGCCTCATCCTCCTCAGAGTGAGGTCTTGCAGGAGGAAGGCAGCAAGGGCAGCATTGGGCATGGAGGCTGCAGACGCTGTCACGGACTAA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.