NCBI Summary
This gene, which is upregulated in human umbilical vein endothelial cells, encodes a G protein-coupled receptor. Variations in this gene can affect a person's stature. Multiple transcript variants encoding different proteins have been found for this gene. [provided by RefSeq, Mar 2009].
Protein
Protein (NP_001027566)
Isoform 2 of Adhesion G-protein coupled receptor G6
Adhesion G-protein coupled receptor G6 (Developmentally regulated G-protein-coupled receptor) (G-protein coupled receptor 126) (Vascular inducible G protein-coupled receptor) [Cleaved into: ADGRG6 N-terminal fragment (ADGRG6-NTF); ADGRG6 C-terminal fragment (ADGRG6-CTF)]
ADGRG6
adhesion G protein-coupled receptor G6
Undefined
Very low evidence
Pentraxin
Undefined
b-sandwich / ConA-like
MMFRSDRMWSCHWKWKPSPLLFLFALYIMCVPHSVWGCANCRVVLSNPSGTFTSPCYPNDYPNSQACMWTLRAPTGYIIQITFNDFDIEEAPNCIYDSLSLDNGESQTKFCGATAKGLSFNSSANEMHVSFSSDFSIQKKGFNASYIRVAVSLRNQKVILPQTSDAYQVSVAKSISIPELSAFTLCFEATKVGHEDSDWTAFSYSNASFTQLLSFGKAKSGYFLSISDSKCLLNNALPVKEKEDIFAESFEQLCLVWNNSLGSIGVNFKRNYETVPCDSTISKVIPGNGKLLLGSNQNEIVSLKGDIYNFRLWNFTMNAKILSNLSCNVKGNVVDWQNDFWNIPNLALKAESNLSCGSYLIPLPAAELASCADLGTLCQDGIIYRISVVIQNILRHPEVKVQSKVAEWLNSTFQNWNYTVYVVNISFHLSAGEDKIKVKRSLEDEPRLVLWALLVYNATNNTNLEGKIIQQKLLKNNESLDEGLRLHTVNVRQLGHCLAMEEPKGYYWPSIQPSEYVLPCPDKPGFSASRICFYNATNPLVTYWGPVDISNCLKEANEVANQILNLTADGQNLTSANITNIVEQVKRIVNKEENIDITLGSTLMNIFSNILSSSDSDLLESSSEALKTIDELAFKIDLNSTSHVNITTRNLALSVSSLLPGTNAISNFSIGLPSNNESYFQMDFESGQVDPLASVILPPNLLENLSPEDSVLVRRAQFTFFNKTGLFQDVGPQRKTLVSYVMACSIGNITIQNLKDPVQIKIKHTRTQEVHHPICAFWDLNKNKSFGGWNTSGCVAHRDSDASETVCLCNHFTHFGVLMDLPRSASQLDARNTKVLTFISYIGCGISAIFSAATLLTYVAFEKLRRDYPSKILMNLSTALLFLNLLFLLDGWITSFNVDGLCIAVAVLLHFFLLATFTWMGLEAIHMYIALVKVFNTYIRRYILKFCIIGWGLPALVVSVVLASRNNNEVYGKESYGKEKGDEFCWIQDPVIFYVTCAGYFGVMFFLNIAMFIVVMVQICGRNGKRSNRTLREEVLRNLRSVVSLTFLLGMTWGFAFFAWGPLNIPFMYLFSIFNSLQGLFIFIFHCAMKENVQKQWRQHLCCGRFRLADNSDWSKTATNIIKKSSDNLGKSLSSSSIGSNSTYLTSKSKSSSTTYFKRNSHTDNVSYEHSFNKSGSLRQCFHGQVLVKTGPC
No structure currently available in the PDB RCSB Databank.
Structural models
AlphaFold v2: AF-Q86SQ4-F1DownloadSee the associated sequence to the AlphaFold v2 model, which is different to this entry(NCBI sequence).
SWISS-MODEL structural models
The location of the lectin domain structural model is: 154-356
We infer [ err > 2 Å] as the interval of error of this structural model.
Template 1: 3PVN chain: A, P02741, NP_000558.2, sequence identity: 19.2%, coverage: 93.1%, location in sequence: 19-224, (1-206 in PDB).
Template 2: 1GYK chain: A, P02743, NP_001630.1, sequence identity: 18.7%, coverage: 92.1%, location in sequence: 20-223, (1-204 in PDB).
Template 3: 1HAS chain: A, P07629, NP_0NO0REFSEQ0.0, sequence identity: 18.2%, coverage: 92.6%, location in sequence: 23-234, (1-212 in PDB).
Show the alignment used for the construction of the structural model, Download.
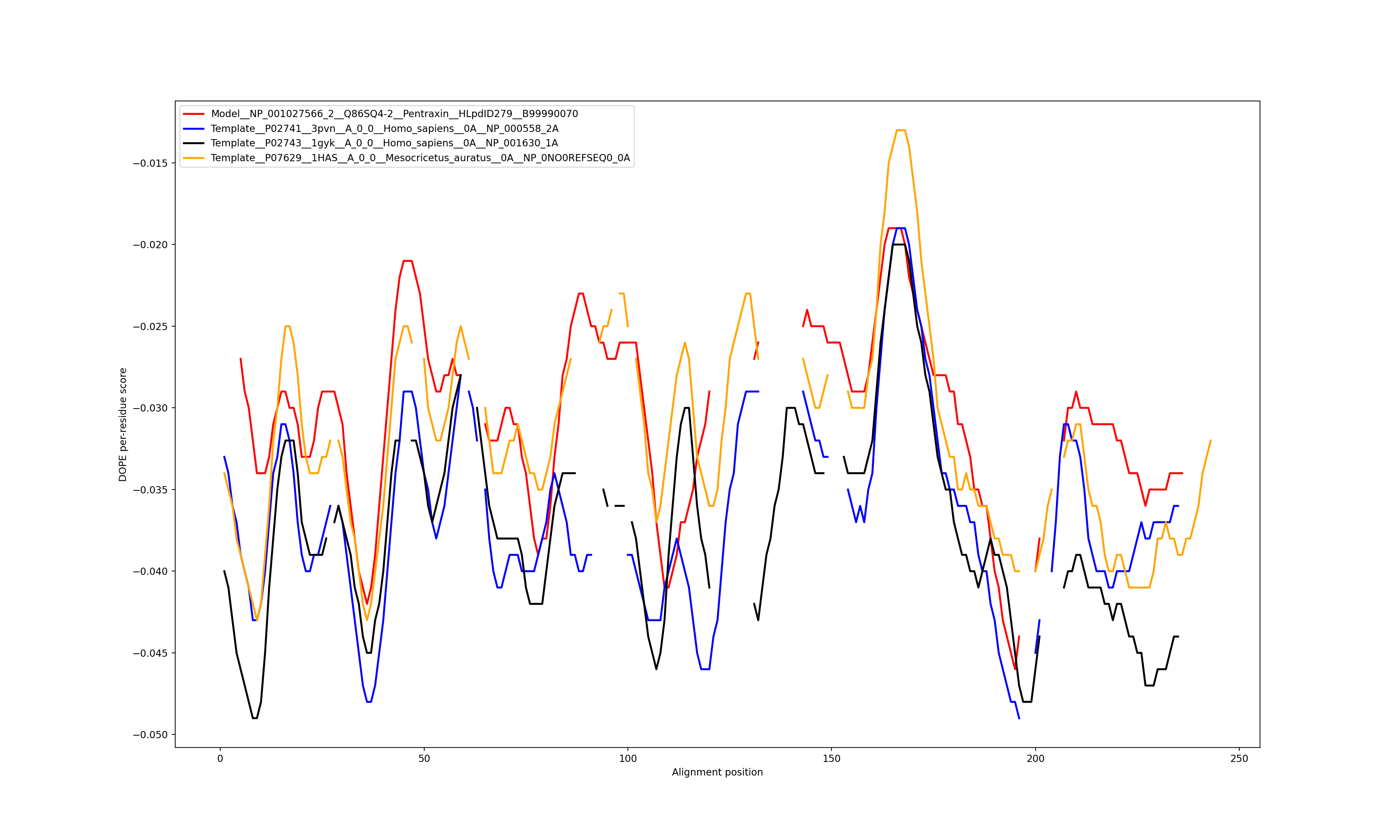
Show the plot of DOPE energy score, Download.
We infer [ err > 2 Å] as the interval of error of this structural model.
Template 1: 3PVN chain: A, P02741, NP_000558.2, sequence identity: 19.2%, coverage: 93.1%, location in sequence: 19-224, (1-206 in PDB).
Template 2: 1GYK chain: A, P02743, NP_001630.1, sequence identity: 18.7%, coverage: 92.1%, location in sequence: 20-223, (1-204 in PDB).
Template 3: 1HAS chain: A, P07629, NP_0NO0REFSEQ0.0, sequence identity: 18.2%, coverage: 92.6%, location in sequence: 23-234, (1-212 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
Heterodimer of 2 chains generated by proteolytic processing; the large extracellular N-terminal fragment and the membrane-bound C-terminal fragment predominantly remain associated and non-covalently linked (By similarity). Interacts with Laminin-2; this interaction stabilizes the receptor in an inactive state (By similarity). Laminin-2 polymerization could facilitate ADGRG6-NTF removal, thereby exposing the tethered agonist to drive myelination (By similarity). Interacts with PRNP (By similarity). Interacts with ITGB1 (By similarity). Interacts with LRP1 (By similarity)
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- Functional genomics of GPR126 in airway smooth muscle and bronchial epithelial cells. [34165809]
- GPR126 regulates colorectal cancer cell proliferation by mediating HDAC2 and GLI2 expression. [33629464]
- Genomic characterization of the adolescent idiopathic scoliosis-associated transcriptome and regulome. [33179741]
- A synthetic method to assay adhesion-family G-protein coupled receptors. Determination of the G-protein coupling profile of ADGRG6(GPR126). [33248691]
- Structural basis for adhesion G protein-coupled receptor Gpr126 function. [31924782]
- A proteomic analysis of human bile. [15084671]
- There exist at least 30 human G-protein-coupled receptors with long Ser/Thr-rich N-termini. [12565841]
- Major recessive gene(s) with considerable residual polygenic effect regulating adult height: confirmation of genomewide scan results for chromosomes 6, 9, and 12. [12119602]
- Genomewide linkage analysis of stature in multiple populations reveals several regions with evidence of linkage to adult height. [11410839]
- The addition of 5'-coding information to a 3'-directed cDNA library improves analysis of gene expression. [8076819]
UniProt Main References (13 PubMed Identifiers)
- VIGR--a novel inducible adhesion family G-protein coupled receptor in endothelial cells. [15225624]
- DREG, a developmentally regulated G protein-coupled receptor containing two conserved proteolytic cleavage sites. [15189448]
- The full-ORF clone resource of the German cDNA Consortium. [17974005]
- The DNA sequence and analysis of human chromosome 6. [14574404]
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
- Complete sequencing and characterization of 21,243 full-length human cDNAs. [14702039]
- Human plasma N-glycoproteome analysis by immunoaffinity subtraction, hydrazide chemistry, and mass spectrometry. [16335952]
- Identification of ten loci associated with height highlights new biological pathways in human growth. [18391950]
- A quantitative atlas of mitotic phosphorylation. [18669648]
- Gpr126 functions in Schwann cells to control differentiation and myelination via G-protein activation. [24227709] Show more
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_001032394.3)
adhesion G protein-coupled receptor G6, transcript variant a2
m7G-5')ppp(5'-CCGGUCUCCUCAGCACCAGCCCCACGCACACCCUACUUCCUCAGCUUCUCGCCCUCACCCUGCCAACUUCCCUGCGAGGAGGGACCUGCCGCCAGCCUGCUUCCUCGUCCGCAGGCCCUGCGCUGAACGCUGCCGCGCCCAGGGUUCACCUUGCGCCGUCGGGAAAGCCCAUGAACUCUCCAGAAACGGCGUAAAGGAGGGUCCCGCCGCGGCGCAGGGCUGGGGCGCCUGGGUUCCCCCUGGGUGGAGCAGCGGCAGCAGAGCGGGAAAGUGGUGGAGGAUGAUCUUGCGGCCAAAGGGGACCUCGGCGCAGUAAUGUCAACAUGAUGUUUCGCUCAGAUCGAAUGUGGAGCUGCCAUUGGAAAUGGAAGCCCAGUCCUCUCCUGUUCUUAUUUGCUUUAUAUAUCAUGUGUGUUCCUCACUCAGUGUGGGGAUGUGCCAACUGCCGAGUGGUUUUGUCCAACCCUUCUGGGACCUUUACUUCUCCAUGCUACCCUAACGACUACCCAAACAGCCAGGCUUGCAUGUGGACGCUCCGAGCCCCCACCGGUUAUAUCAUUCAGAUAACAUUUAACGACUUUGACAUUGAAGAAGCUCCCAAUUGCAUUUAUGACUCAUUAUCCCUUGAUAAUGGAGAGAGCCAGACUAAAUUUUGUGGAGCAACUGCCAAAGGCCUAUCAUUUAACUCAAGUGCGAAUGAGAUGCAUGUGUCCUUUUCAAGUGACUUUAGCAUCCAGAAGAAAGGUUUCAAUGCCAGCUACAUCAGAGUUGCCGUGUCCUUAAGGAAUCAAAAGGUCAUUUUACCCCAGACAUCAGAUGCUUACCAGGUAUCUGUUGCAAAAAGCAUCUCUAUUCCAGAGCUCAGUGCUUUCACACUCUGCUUUGAAGCAACCAAAGUUGGCCAUGAAGACAGUGAUUGGACAGCUUUCUCCUACUCAAAUGCAUCCUUCACACAAUUGCUCAGUUUUGGAAAGGCCAAGAGUGGCUACUUUCUAUCCAUUUCUGAUUCAAAAUGUUUGUUGAAUAAUGCAUUACCUGUCAAAGAAAAAGAAGACAUUUUUGCAGAAAGCUUUGAACAGCUCUGCCUUGUUUGGAAUAAUUCUUUGGGCUCUAUUGGUGUAAAUUUCAAAAGAAACUAUGAAACAGUUCCAUGUGAUUCUACCAUUAGUAAAGUUAUUCCUGGGAAUGGGAAAUUGUUGUUGGGCUCCAAUCAAAAUGAAAUUGUCUCUCUAAAAGGGGACAUUUAUAACUUUCGACUUUGGAAUUUUACCAUGAAUGCCAAAAUCCUCUCCAACCUCAGCUGUAAUGUGAAAGGGAAUGUAGUCGACUGGCAAAAUGACUUCUGGAAUAUCCCAAACCUAGCUCUGAAAGCUGAAAGCAACCUAAGCUGUGGUUCCUACCUGAUCCCGCUCCCAGCAGCAGAACUGGCCAGCUGUGCAGACCUGGGGACCCUCUGUCAAGAUGGAAUUAUCUAUAGAAUAUCCGUAGUGAUUCAGAACAUCCUUCGUCACCCUGAGGUAAAAGUACAGAGCAAGGUGGCAGAAUGGCUCAAUUCAACCUUCCAAAAUUGGAACUACACGGUUUAUGUCGUUAAUAUCAGUUUUCACCUGAGUGCUGGAGAGGACAAGAUUAAAGUCAAGAGAAGCCUUGAGGAUGAGCCAAGGUUGGUGCUUUGGGCCCUUCUAGUUUACAAUGCUACCAACAAUACUAAUUUGGAAGGAAAAAUCAUUCAGCAGAAGCUCCUAAAAAAUAAUGAGUCCUUGGAUGAAGGCUUGAGGCUACAUACAGUGAAUGUGAGACAACUGGGUCAUUGUCUUGCCAUGGAGGAACCCAAAGGCUACUACUGGCCAUCUAUCCAACCUUCUGAAUACGUUCUUCCUUGUCCAGACAAGCCUGGCUUUUCUGCUUCUCGGAUAUGUUUUUACAAUGCUACCAACCCAUUGGUAACCUACUGGGGACCUGUUGAUAUCUCCAACUGUUUAAAAGAAGCAAAUGAAGUUGCUAACCAGAUUUUAAAUUUAACUGCUGAUGGGCAGAACUUAACCUCAGCCAAUAUUACCAACAUUGUGGAACAGGUCAAAAGAAUUGUGAAUAAAGAAGAAAACAUUGAUAUAACACUUGGCUCAACUCUAAUGAAUAUAUUUUCUAAUAUCUUAAGCAGUUCAGACAGUGACUUGCUUGAGUCAUCUUCUGAAGCUUUAAAAACAAUUGAUGAAUUGGCCUUCAAGAUAGACCUAAAUAGCACAUCACAUGUGAAUAUUACAACUCGGAACUUGGCUCUCAGCGUAUCAUCCCUGUUACCAGGGACAAAUGCAAUUUCAAAUUUUAGCAUUGGUCUUCCAAGCAAUAAUGAAUCGUAUUUCCAGAUGGAUUUUGAGAGUGGACAAGUGGAUCCACUGGCAUCUGUAAUUUUGCCUCCAAACUUACUUGAGAAUUUAAGUCCAGAAGAUUCUGUAUUAGUUAGAAGAGCACAGUUUACUUUCUUCAACAAAACUGGACUUUUCCAGGAUGUAGGACCCCAAAGAAAAACUUUAGUGAGUUAUGUGAUGGCGUGCAGUAUUGGAAACAUUACUAUCCAGAAUCUGAAGGAUCCUGUUCAAAUAAAAAUCAAACAUACAAGAACUCAGGAAGUGCAUCAUCCCAUCUGUGCCUUCUGGGAUCUGAACAAAAACAAAAGUUUUGGAGGAUGGAACACGUCAGGAUGUGUUGCACACAGAGAUUCAGAUGCAAGUGAGACAGUCUGCCUGUGUAACCACUUCACACACUUUGGAGUUCUGAUGGACCUUCCAAGAAGUGCCUCACAGUUAGAUGCAAGAAACACUAAAGUCCUCACUUUCAUCAGCUAUAUUGGGUGUGGAAUAUCUGCUAUUUUUUCAGCAGCAACUCUCCUGACAUAUGUUGCUUUUGAGAAAUUGCGAAGGGAUUAUCCCUCCAAAAUCUUGAUGAACCUGAGCACAGCCCUGCUGUUCCUGAAUCUCCUCUUCCUCCUAGAUGGCUGGAUCACCUCCUUCAAUGUGGAUGGACUUUGCAUUGCUGUUGCAGUCCUGUUGCAUUUCUUCCUUCUGGCAACCUUUACCUGGAUGGGGCUAGAAGCAAUUCACAUGUACAUUGCUCUAGUUAAAGUAUUUAACACUUACAUUCGCCGAUACAUUCUAAAAUUCUGCAUCAUUGGCUGGGGUUUGCCUGCCUUAGUGGUGUCAGUUGUUCUAGCGAGCAGAAACAACAAUGAAGUCUAUGGAAAAGAAAGUUAUGGGAAAGAAAAAGGUGAUGAAUUCUGUUGGAUUCAAGAUCCAGUCAUAUUUUAUGUGACCUGUGCUGGGUAUUUUGGAGUCAUGUUUUUUCUGAACAUUGCCAUGUUCAUUGUGGUAAUGGUGCAGAUCUGUGGGAGGAAUGGCAAGAGAAGCAACCGGACCCUGAGAGAAGAAGUGUUAAGGAACCUGCGCAGUGUGGUUAGCUUGACCUUUCUGUUGGGCAUGACAUGGGGUUUUGCAUUCUUUGCCUGGGGACCCUUAAAUAUCCCCUUCAUGUACCUCUUCUCCAUCUUCAAUUCAUUACAAGGCUUAUUUAUAUUCAUCUUCCACUGUGCUAUGAAGGAGAAUGUUCAGAAACAGUGGCGGCAGCAUCUCUGCUGUGGUAGAUUUCGGUUAGCAGAUAACUCAGAUUGGAGUAAGACAGCUACCAAUAUCAUCAAGAAAAGUUCUGAUAAUCUAGGAAAAUCUUUGUCUUCAAGCUCCAUUGGUUCCAACUCAACCUAUCUUACAUCCAAAUCUAAAUCCAGCUCUACCACCUAUUUCAAAAGGAAUAGCCACACAGAUAAUGUCUCCUAUGAGCAUUCCUUCAACAAAAGUGGAUCACUCAGACAGUGCUUCCAUGGACAAGUCCUUGUCAAAACUGGCCCAUGCUGAUGGAGAUCAAACAUCAAUCAUCCCUGUCCAUCAGGUCAUUGAUAAGGUCAAGGGUUAUUGCAAUGCUCAUUCAGACAACUUCUAUAAAAAUAUUAUCAUGUCAGACACCUUCAGCCACAGCACAAAGUUUUAAUGUCUUUAAGAAAAAGAAAUCAAUCUGCAGAAAUGUGAAGAUUUGCAAGCAGUGUAAACUGCAACUAGUGAUGUAAAUGUGCUAUUACCUAGGUAACUGCAUAUAUAUAAGGAAUGUAUUUUGUUAAGAAGGCUUUUGUGAAAUUCAGAAUUUUUCUUUUUAAUAUAUUUCUUCCAUGGAAGAGUUGUCAUCACUAAAACUUCAGUACUGAGAGUAACAUGACUCAGUAGCCACAGAAGCUAUGAUUUGUAAAAUAUAUAAUUGAAUCAGAGUAAUCAUAAUGCAGGGGAGACAUUCAAAUUAGAGACAAGGGAGAAGCAAUGCUGAGGAAGACCCUAGAUAGAGCUCAUUUUACUCCACCUAAUCGUUAUAUCUGGAUAUACCCAUUUUCUGCAUCUUCUUUCUCAACAAUAAAAAAUGUAACUAUUUUGAAUGCCCACAAAUCCCAUUCCAGUGUUACUUUCUGUGAAUGCAGUACCAUAUUCUCAUUUUCAAUGACAUUUCAACCACAGGCAGAAAAGACUGUUUACUCCUUGACCCAAAGAUUAAAAAGGAUUUUUUAUUAUUUUAAAUAUUACACCUUCAGAACCAUAACAUGCUUAAGAAAACUUUCCCAAAAUGUUGACCUAGUUAAAUGAGGCUAUAUAAAUUUCUAAUAUUUUACUUAUUCUAUUCAAGGCAUAGGGCCAAAGCAUUAAGUAUAAUUUAAUCCCAUACAUUCGAGUUAAGUUUAGUGUUGAUGUUCCAUCAUUCUGGACCUCCCAGGAGUUGUUUAAGAAUGAAUCUCUUACACCUCUACUUUUGCCCCUCUACUGUAUAUUAAGCCCAUAGGCUUGUGGGAGGAAGGAGAAUUUCCAUUAGGCAAGCUGUAUGCAGUGGAAUUUUCCUUUUAGGAGACACACAAUUAAGACUCUCUGGUUCUGUCCUUGCUUUGGAGACUUUAAGACAUUUCCUAAAGCACAAAUAAAAGCCUCGUAUUUCCCCAUUGAGAGUUUUGUUCCAAGGAAUAUGAAGUGAGACAUAUGGGUGAGUCAUAAUAAUCAAAAUAAUUUAUGAAGAGCUGGGUCUGCAAUAGCUAGUCUAAAAACUACUUGUGUGUCAGUCCUCUGGUUAUAGUAUAUAAGAGCCUGAGGAGGUCUGGCAAGAUAGAUGGUGUAUUAUUUAUGGAUCAGGCUGCUGCAUACAAACCUUGCAUACUAUUAUGCAGCUUACCUAACUCUCAGACUAUUCUGAGUAAUGCUUGCUUGCUAAUGAAUGUAUAGGAGACCACAUUGUAAUUGUUCUUAGAUGAUGGAGUCCAUGCAGUUUCUUAGAAAUCGGUCUCAGUGCAUGCUGUGCUUUUUCACAUUUGCUCUGGGUUAUCUGGGAAGUAUCAGGUUCUGGGAGGCAACAGCAUUAAGUGAUAAGAAAAGGAGACAUUCUGGCAAAGCCAAUCUGCUUAAAGGCAAAGUCCAGAACCUGGAACCUAGAGGCCUUUCUCUCUGCACGAAAAACAGGUAGUUUGCAGUCUGAGAUAUGGGAGAGCUUUUAGGCUACACAGCAACCCAAGGGACCUCUCACCUUUUGCUGAGCUUCAAUCAGGAAGCUAUUUGCCUGGCUCCAGCAGAUGAUGAGAUAAUGAGGUAGUGGGUUUUUUAUUACUGUUCCAUUUUGCAACAUCCUGCAACACCAUCCUGGGAGACAAGAGCAUUACCCAGCUUGGCUUUCACGGGGGAGGGUUGUAUUCAGUAAAAAAGAAUAGUAAAUAUAAGGUCACUGAGAUUCUAAGUAAGAUAGUAAAUCUAAGGUCACUGAGCCAAAUCCUUUUCAAUAGGCAUAUAUUAACAGGCUGCUUAUUUUGGCGGAGGUUACAUAUGGAUGAAAAUGAAUCUUAGUCACUGAAUAUUCAUAUACAUUUCCCCCAAAACCUUAGACAUUCAUAGUAGAUUUUAAUUAGUUAGCUUUCUAACUAGUCAGAUUUCUGCCCAAAGUGCUUAGUCAAUAGUAAUUAAGAUAUAGCUUCAAAAAUGGCUUUGCUUUUGAUUUCUACUCAUAUUCGUAUGGCUCCAGAAAAAUAUUUUUUUCAUAUUUGACAAUGUCAGCUCCACUUUAGAAAUUUUCAAUAACCAGAUGAGAAAAAAAUUAAGAAAUUGCUCAAGGGAAACAUUUGUAAAUGGAUUUGAAAGAUUGAGCCAAAUUCUGUUGUCAGUUCUAAGCAUGCAGUUCUCACCUCCAUUUAGUCCCCCAUCAGAACAGAGGUCAGGAAUUUAGCUGGGGAGCCUAAAUUUAGUUCAGCUUACCUUUGAGAAUAGCAUCAAUUCAGACUCUCUUUUCAUUAUGUUUUCUUUUCUUUUUCCCUCUUUUUAAACUACAUUGUGUUAGAGUCAUAGUCUAGGAUCCUGAGAGAUUUUCCAUUCUUGUCACCAUUCACUUGCAUUGUAAAGAUUUUCUUUGUCUGUUGUUGGCAUAGAUUCUUUUGUACAUAUUUAUUUAUUUGUGUUUAUAUAUGUCAAUUGGUUUCCUUUCUUAGCUUGAUAUUGCCUAGCUUUGUUGUUUUAAUUAACUUUCUAUUAGAGAGACUGUAUAUAUUUUUUCUAAAUACUUUGUGAAAUCAUUUUUGGUAGCAAUAUCUUUGAAUAUGAUGAAUAAAAGUGACUGUGAGUGCAAAUAGAAUUAGCAGUAAGAAGCUACUCUAGCUAAUUUGCCAUUUUACUUAAAUGGAAAAUGUUUUUCAAAUAAAUACUUAUGUUGUUCAUGUUCCAAGUUA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 57211)
adhesion G protein-coupled receptor G6
strand +
NCBI CDS gene sequence (3582 bp)
5'-ATGATGTTTCGCTCAGATCGAATGTGGAGCTGCCATTGGAAATGGAAGCCCAGTCCTCTCCTGTTCTTATTTGCTTTATATATCATGTGTGTTCCTCACTCAGTGTGGGGATGTGCCAACTGCCGAGTGGTTTTGTCCAACCCTTCTGGGACCTTTACTTCTCCATGCTACCCTAACGACTACCCAAACAGCCAGGCTTGCATGTGGACGCTCCGAGCCCCCACCGGTTATATCATTCAGATAACATTTAACGACTTTGACATTGAAGAAGCTCCCAATTGCATTTATGACTCATTATCCCTTGATAATGGAGAGAGCCAGACTAAATTTTGTGGAGCAACTGCCAAAGGCCTATCATTTAACTCAAGTGCGAATGAGATGCATGTGTCCTTTTCAAGTGACTTTAGCATCCAGAAGAAAGGTTTCAATGCCAGCTACATCAGAGTTGCCGTGTCCTTAAGGAATCAAAAGGTCATTTTACCCCAGACATCAGATGCTTACCAGGTATCTGTTGCAAAAAGCATCTCTATTCCAGAGCTCAGTGCTTTCACACTCTGCTTTGAAGCAACCAAAGTTGGCCATGAAGACAGTGATTGGACAGCTTTCTCCTACTCAAATGCATCCTTCACACAATTGCTCAGTTTTGGAAAGGCCAAGAGTGGCTACTTTCTATCCATTTCTGATTCAAAATGTTTGTTGAATAATGCATTACCTGTCAAAGAAAAAGAAGACATTTTTGCAGAAAGCTTTGAACAGCTCTGCCTTGTTTGGAATAATTCTTTGGGCTCTATTGGTGTAAATTTCAAAAGAAACTATGAAACAGTTCCATGTGATTCTACCATTAGTAAAGTTATTCCTGGGAATGGGAAATTGTTGTTGGGCTCCAATCAAAATGAAATTGTCTCTCTAAAAGGGGACATTTATAACTTTCGACTTTGGAATTTTACCATGAATGCCAAAATCCTCTCCAACCTCAGCTGTAATGTGAAAGGGAATGTAGTCGACTGGCAAAATGACTTCTGGAATATCCCAAACCTAGCTCTGAAAGCTGAAAGCAACCTAAGCTGTGGTTCCTACCTGATCCCGCTCCCAGCAGCAGAACTGGCCAGCTGTGCAGACCTGGGGACCCTCTGTCAAGATGGAATTATCTATAGAATATCCGTAGTGATTCAGAACATCCTTCGTCACCCTGAGGTAAAAGTACAGAGCAAGGTGGCAGAATGGCTCAATTCAACCTTCCAAAATTGGAACTACACGGTTTATGTCGTTAATATCAGTTTTCACCTGAGTGCTGGAGAGGACAAGATTAAAGTCAAGAGAAGCCTTGAGGATGAGCCAAGGTTGGTGCTTTGGGCCCTTCTAGTTTACAATGCTACCAACAATACTAATTTGGAAGGAAAAATCATTCAGCAGAAGCTCCTAAAAAATAATGAGTCCTTGGATGAAGGCTTGAGGCTACATACAGTGAATGTGAGACAACTGGGTCATTGTCTTGCCATGGAGGAACCCAAAGGCTACTACTGGCCATCTATCCAACCTTCTGAATACGTTCTTCCTTGTCCAGACAAGCCTGGCTTTTCTGCTTCTCGGATATGTTTTTACAATGCTACCAACCCATTGGTAACCTACTGGGGACCTGTTGATATCTCCAACTGTTTAAAAGAAGCAAATGAAGTTGCTAACCAGATTTTAAATTTAACTGCTGATGGGCAGAACTTAACCTCAGCCAATATTACCAACATTGTGGAACAGGTCAAAAGAATTGTGAATAAAGAAGAAAACATTGATATAACACTTGGCTCAACTCTAATGAATATATTTTCTAATATCTTAAGCAGTTCAGACAGTGACTTGCTTGAGTCATCTTCTGAAGCTTTAAAAACAATTGATGAATTGGCCTTCAAGATAGACCTAAATAGCACATCACATGTGAATATTACAACTCGGAACTTGGCTCTCAGCGTATCATCCCTGTTACCAGGGACAAATGCAATTTCAAATTTTAGCATTGGTCTTCCAAGCAATAATGAATCGTATTTCCAGATGGATTTTGAGAGTGGACAAGTGGATCCACTGGCATCTGTAATTTTGCCTCCAAACTTACTTGAGAATTTAAGTCCAGAAGATTCTGTATTAGTTAGAAGAGCACAGTTTACTTTCTTCAACAAAACTGGACTTTTCCAGGATGTAGGACCCCAAAGAAAAACTTTAGTGAGTTATGTGATGGCGTGCAGTATTGGAAACATTACTATCCAGAATCTGAAGGATCCTGTTCAAATAAAAATCAAACATACAAGAACTCAGGAAGTGCATCATCCCATCTGTGCCTTCTGGGATCTGAACAAAAACAAAAGTTTTGGAGGATGGAACACGTCAGGATGTGTTGCACACAGAGATTCAGATGCAAGTGAGACAGTCTGCCTGTGTAACCACTTCACACACTTTGGAGTTCTGATGGACCTTCCAAGAAGTGCCTCACAGTTAGATGCAAGAAACACTAAAGTCCTCACTTTCATCAGCTATATTGGGTGTGGAATATCTGCTATTTTTTCAGCAGCAACTCTCCTGACATATGTTGCTTTTGAGAAATTGCGAAGGGATTATCCCTCCAAAATCTTGATGAACCTGAGCACAGCCCTGCTGTTCCTGAATCTCCTCTTCCTCCTAGATGGCTGGATCACCTCCTTCAATGTGGATGGACTTTGCATTGCTGTTGCAGTCCTGTTGCATTTCTTCCTTCTGGCAACCTTTACCTGGATGGGGCTAGAAGCAATTCACATGTACATTGCTCTAGTTAAAGTATTTAACACTTACATTCGCCGATACATTCTAAAATTCTGCATCATTGGCTGGGGTTTGCCTGCCTTAGTGGTGTCAGTTGTTCTAGCGAGCAGAAACAACAATGAAGTCTATGGAAAAGAAAGTTATGGGAAAGAAAAAGGTGATGAATTCTGTTGGATTCAAGATCCAGTCATATTTTATGTGACCTGTGCTGGGTATTTTGGAGTCATGTTTTTTCTGAACATTGCCATGTTCATTGTGGTAATGGTGCAGATCTGTGGGAGGAATGGCAAGAGAAGCAACCGGACCCTGAGAGAAGAAGTGTTAAGGAACCTGCGCAGTGTGGTTAGCTTGACCTTTCTGTTGGGCATGACATGGGGTTTTGCATTCTTTGCCTGGGGACCCTTAAATATCCCCTTCATGTACCTCTTCTCCATCTTCAATTCATTACAAGGCTTATTTATATTCATCTTCCACTGTGCTATGAAGGAGAATGTTCAGAAACAGTGGCGGCAGCATCTCTGCTGTGGTAGATTTCGGTTAGCAGATAACTCAGATTGGAGTAAGACAGCTACCAATATCATCAAGAAAAGTTCTGATAATCTAGGAAAATCTTTGTCTTCAAGCTCCATTGGTTCCAACTCAACCTATCTTACATCCAAATCTAAATCCAGCTCTACCACCTATTTCAAAAGGAATAGCCACACAGATAATGTCTCCTATGAGCATTCCTTCAACAAAAGTGGATCACTCAGACAGTGCTTCCATGGACAAGTCCTTGTCAAAACTGGCCCATGCTGA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.