Protein
Protein (XP_006717411)
Adhesion G protein-coupled receptor D2
Adhesion G-protein coupled receptor D2 (G-protein coupled receptor 144) (G-protein coupled receptor PGR24)
ADGRD2
adhesion G protein-coupled receptor D2
Undefined
Very low evidence
Pentraxin
L-Type Lectins
b-sandwich / ConA-like
MVTGPEEGNSEMDAPWGAGERWLHGAAVDRSGVSLGPPPTPQVNQGTLGPQVAPVAAGEVVKTAGGVCKFSGQRLSWWQAQESCEQQFGHLALQPPDGVLASRLRDPVWVGQREAPLRRPPQRRARTTAVLVFDERTADRAARLRSPLPELAALTACTHVQWDCASPDPAALFSVAAPALPNALQLRAFAEPGGVVRAALVVRGQHAPFLAAFRADGRWHHVCATWEQRGGRWALFSDGRRRAGARGLGAGHPVPSGGILVLGQDQDSLGGGFSVRHALSGNLTDFHLWARALSPAQLHRARACAPPSEGLLFRWDPGALDVTPSLLPTVWVRLLCPVPSEECPTWNPGPRSEGSELCLEPQPFLCCYRTEPYRRLQDAQSWPGQDVISRVNALANDIVLLPDPLSEVHGALSPAEASSFLGLLEHVLAMEMAPLGPAALLAVVRFLKRVVALGAGDPELLLTGPWEQLSQGVVSVASLVLEEQVADTWLSLREVIGGPMALVASVQRLAPLLSTSMTSERPRMRIQHRHAGLSGVTVIHSWFTSRVFQHTLEGPDLEPQAPASSEEANRVQRFLSTQVGSAIISSEVWDVTGEVNVAMTFHLQHRAQSPLFPPHPPSPYTGGAWATTGCSVAALYLDSTACFCNHSTSFAILLQIYEVQRGPEEESLLRTLSFVGCGVSFCALTTTFLLFLVAGVPKSERTTVHKNLTFSLASAEGFLMTSEWAKANEVACVAVTVAMHFLFLVAFSWMLVEGLLLWRKVVAVSMHPGPGMRLYHATGWGVPVGIVAVTLAMLPHDYVAPGHCWLNVHTNAIWAFVGPVLFVLTANTCILARVVMITVSSARRRARMLSPQPCLQQQIWTQIWATVKPVLVLLPVLGLTWLAGILVHLSPAWAYAAVGLNSIQGLYIFLVYAACNEEVRSALQRMAEKKVAEVLRALGVWGGAAKEHSLPFSVLPLFLPPKPSTPRHPLKAPA
No structure currently available in the PDB RCSB Databank.
Structural models
AlphaFold v2: AF-Q7Z7M1-F1DownloadSee the associated sequence to the AlphaFold v2 model, which is different to this entry(NCBI sequence).
SWISS-MODEL structural models
The location of the lectin domain structural model is: 116-325
We infer [1.63, 2.13] Å as the interval of error of this structural model.
Template 1: 1HAS chain: A, P07629, NP_0NO0REFSEQ0.0, sequence identity: 22.9%, coverage: 91.0%, location in sequence: 23-234, (1-212 in PDB).
Template 2: 3PVN chain: A, P02741, NP_000558.2, sequence identity: 22.4%, coverage: 93.3%, location in sequence: 19-224, (1-206 in PDB).
Template 3: 1GYK chain: A, P02743, NP_001630.1, sequence identity: 22.4%, coverage: 92.4%, location in sequence: 20-223, (1-204 in PDB).
Show the alignment used for the construction of the structural model, Download.
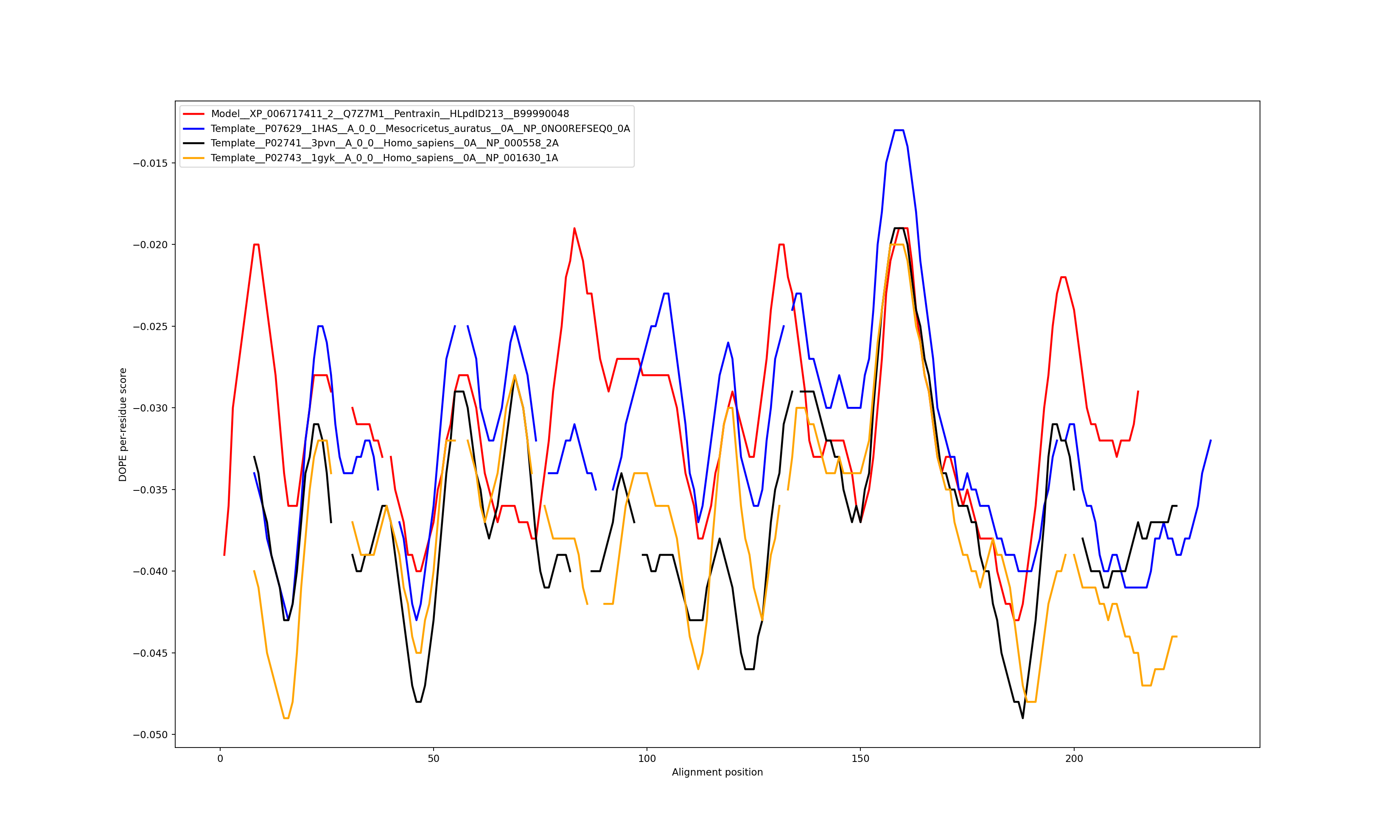
Show the plot of DOPE energy score, Download.
We infer [1.63, 2.13] Å as the interval of error of this structural model.
Template 1: 1HAS chain: A, P07629, NP_0NO0REFSEQ0.0, sequence identity: 22.9%, coverage: 91.0%, location in sequence: 23-234, (1-212 in PDB).
Template 2: 3PVN chain: A, P02741, NP_000558.2, sequence identity: 22.4%, coverage: 93.3%, location in sequence: 19-224, (1-206 in PDB).
Template 3: 1GYK chain: A, P02743, NP_001630.1, sequence identity: 22.4%, coverage: 92.4%, location in sequence: 20-223, (1-204 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
UniProt Main References (5 PubMed Identifiers)
- The human and mouse repertoire of the adhesion family of G-protein-coupled receptors. [15203201]
- DNA sequence and analysis of human chromosome 9. [15164053]
- The G protein-coupled receptor repertoires of human and mouse. [12679517]
- International Union of Basic and Clinical Pharmacology. XCIV. Adhesion G protein-coupled receptors. [25713288]
- CSNK2B splice site mutations in patients cause intellectual disability with or without myoclonic epilepsy. [28585349]
RNA
RNA (Transcript ID: XM_006717348.3)
adhesion G protein-coupled receptor D2, transcript variant X2
m7G-5')ppp(5'-GGCAGUCCAGGCAGGAGGGAUGGCAUGGUCACAGGUCCAGAGGAGGGAAACUCAGAAAUGGACGCACCUUGGGGAGCAGGGGAAAGGUGGCUGCACGGAGCAGCGGUGGACAGAUCAGGAGUCUCUCUGGGACCCCCUCCAACUCCCCAGGUGAAUCAAGGAACCCUUGGGCCCCAGGUUGCCCCCGUGGCCGCCGGCGAGGUGGUGAAGACUGCAGGUGGGGUGUGCAAGUUCUCUGGACAGCGACUGAGCUGGUGGCAGGCCCAAGAGUCCUGCGAGCAGCAGUUUGGCCACUUGGCACUGCAGCCCCCUGAUGGGGUUCUUGCUUCACGGCUGCGCGAUCCGGUCUGGGUGGGCCAAAGAGAGGCCCCUCUGCGGAGACCCCCACAGAGGCGUGCGCGCACCACCGCCGUGCUGGUGUUCGACGAGAGGACGGCUGACCGGGCGGCGCGGCUGCGGAGCCCUCUGCCUGAGCUGGCAGCGCUGACCGCGUGUACUCACGUGCAGUGGGACUGUGCCUCGCCCGACCCCGCAGCGCUCUUCUCCGUUGCCGCGCCCGCGCUGCCCAACGCGCUGCAGCUGCGCGCCUUCGCCGAGCCGGGGGGCGUCGUGCGCGCUGCGCUGGUGGUGCGUGGGCAGCACGCGCCCUUCCUCGCAGCCUUCCGCGCCGACGGCCGCUGGCACCAUGUGUGCGCCACGUGGGAGCAGCGGGGCGGGCGCUGGGCGCUGUUCUCCGAUGGGAGGCGGCGCGCUGGGGCGCGGGGGCUGGGCGCCGGCCACCCGGUGCCGUCCGGCGGCAUCCUGGUGCUGGGCCAGGAUCAGGACUCUCUGGGCGGUGGCUUCUCGGUGCGUCACGCCCUCAGCGGCAACCUCACCGACUUCCACCUGUGGGCGCGGGCGCUGAGCCCCGCUCAGCUGCACCGGGCACGGGCCUGCGCGCCGCCCUCAGAGGGCCUGCUCUUCCGCUGGGACCCGGGCGCCCUGGACGUCACGCCCUCGCUGCUGCCCACUGUGUGGGUGCGCCUUCUCUGUCCCGUGCCCUCCGAGGAGUGCCCUACGUGGAACCCGGGACCUCGCAGUGAGGGCUCUGAGCUCUGCCUGGAGCCGCAGCCCUUCCUCUGCUGCUACCGGACAGAGCCCUAUCGUCGGCUGCAGGAUGCCCAGUCGUGGCCUGGCCAGGAUGUUAUCAGCCGAGUCAAUGCCUUGGCCAACGACAUUGUGCUCCUCCCGGACCCCCUCUCCGAAGUCCAUGGGGCCCUGUCCCCAGCGGAGGCCUCCAGCUUCCUGGGCCUUCUGGAGCAUGUCCUGGCGAUGGAGAUGGCUCCCCUGGGGCCGGCCGCACUGCUGGCUGUUGUCCGCUUCCUGAAGAGGGUGGUGGCCCUCGGGGCUGGGGACCCAGAGCUGUUGUUGACAGGCCCCUGGGAGCAGCUGAGCCAAGGCGUUGUAUCUGUGGCCAGCCUGGUCCUGGAGGAGCAGGUGGCUGACACAUGGCUCUCCCUCCGUGAAGUGAUUGGUGGGCCUAUGGCCCUGGUGGCGAGUGUGCAGCGCCUGGCACCCCUGCUGAGCACCUCAAUGACCUCAGAGCGGCCCCGAAUGCGCAUCCAGCACCGCCAUGCUGGCCUCUCUGGAGUCACCGUGAUCCACAGCUGGUUCACCUCCAGAGUCUUCCAGCACACCCUAGAGGGACCGGACCUAGAGCCCCAGGCCCCUGCCAGCUCAGAGGAGGCAAACAGGGUGCAGAGGUUCCUAAGCACCCAGGUGGGGUCAGCCAUCAUCUCCUCUGAAGUGUGGGACGUCACUGGAGAGGUCAACGUGGCCAUGACCUUUCAUCUCCAGCACCGGGCCCAGAGCCCCCUGUUCCCUCCCCAUCCCCCAAGCCCAUAUACAGGGGGUGCCUGGGCCACCACAGGCUGCUCCGUGGCUGCCCUGUACCUGGACUCCACCGCCUGCUUCUGCAACCACAGCACCAGCUUUGCCAUCCUGCUGCAAAUCUAUGAAGUACAGAGAGGCCCUGAGGAGGAGUCGCUGCUGAGGACUCUGUCAUUUGUGGGCUGUGGCGUGUCCUUCUGCGCCCUCACCACCACCUUCUUGCUCUUCCUGGUGGCCGGGGUCCCCAAGUCAGAGCGAACCACAGUCCACAAGAACCUCACCUUCUCCCUGGCCUCUGCCGAGGGCUUCCUCAUGACCAGCGAGUGGGCCAAGGCCAAUGAGGUGGCAUGUGUGGCUGUCACAGUCGCAAUGCACUUCCUCUUUCUGGUGGCAUUCUCCUGGAUGCUGGUGGAGGGGCUGCUGCUGUGGAGGAAGGUGGUAGCUGUGAGCAUGCACCCGGGCCCAGGCAUGCGGCUCUACCACGCCACAGGCUGGGGCGUGCCUGUGGGCAUCGUGGCGGUCACCCUGGCCAUGCUCCCCCAUGACUACGUGGCCCCCGGACAUUGCUGGCUCAAUGUGCACACAAAUGCCAUCUGGGCCUUCGUGGGGCCUGUGCUCUUCGUGCUGACUGCCAACACCUGCAUCCUGGCCCGUGUGGUAAUGAUCACCGUGUCCAGUGCCCGCCGCCGUGCCCGCAUGUUGAGCCCACAGCCCUGCCUGCAGCAGCAGAUCUGGACCCAGAUAUGGGCCACGGUGAAGCCCGUGCUGGUCCUGCUGCCCGUCCUAGGCCUGACCUGGCUGGCAGGCAUCCUGGUGCACCUGAGCCCCGCCUGGGCCUACGCUGCCGUGGGCCUCAACUCCAUCCAGGGGCUGUACAUCUUCCUGGUUUAUGCUGCCUGCAAUGAGGAGGUGCGGAGCGCCCUGCAGAGGAUGGCUGAGAAGAAGGUGGCCGAGGUGCUCAGGGCACUGGGGGUGUGGGGGGGCGCUGCCAAGGAGCACAGCCUGCCUUUCUCUGUCCUCCCCCUCUUUCUGCCCCCUAAGCCCAGCACCCCCCGUCACCCUCUGAAGGCCCCGGCCUGAUGCCCUAGGAUCCAGAGCCUUCCAAACCCGCUGAGGGAGAAGUGCUUUCCUCCAAGGCUGCGGGUCACCAGCUGGACAGCUGAUGGGGGCAUGACGGGGGCUGAGCAGUGGCAGGGUGGGUACUGUGGGAGGGUGAGGACACCCCAGCUCCGGCUCAGGGAGAGGACUGAAGCCUGGGGAGCUCAGCCGGGCCCAGGGGAGCCAUGCGGACCCUGACCGCUGGCCGCCUCCCUGAGGGAGCACUCCAUCUGAAACCCACACGCCUCAGCCUCCGCCAGGUGACUGUUUCCAGCGAAGGCAAGAGCGCUGUUCACCAGGCCCCUCCCAGGGGCAGGUUCAGUGCUCAGCCCAGGCACCCAGUGAUUCUGAUUCAGAGAGGGGGAGGGGGAGGUGCCUUUCUCCACCCAUUGCGCGGAUGAGGAAGUUGAGGCACAGAAAGGCGCAGCCGCUAGCCAGAGCCCGCACAGAGCCAGAGCCAGGUCCCCACUGGCGCAGAUGGGGGACUGCAGGCACAGCAGUAGCCACGCGGGUGUAAACGUAGAGCCGCGUGAACCCGGGUUGUGGGAUCCCAGGCCCCGACCAGCCCCCAUCCCCGGCUGGCAUCUCGGUCCCGGGGAGUCUCAGCUUCCCUUUCUGCAGAAUGGGCUGGAGGCGCCCCCCACAGGCCCGCCCAGGCGCCCCCCGGGGCCAGCGCC-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 347088)
adhesion G protein-coupled receptor D2
strand +
NCBI CDS gene sequence (2925 bp)
5'-ATGGTCACAGGTCCAGAGGAGGGAAACTCAGAAATGGACGCACCTTGGGGAGCAGGGGAAAGGTGGCTGCACGGAGCAGCGGTGGACAGATCAGGAGTCTCTCTGGGACCCCCTCCAACTCCCCAGGTGAATCAAGGAACCCTTGGGCCCCAGGTTGCCCCCGTGGCCGCCGGCGAGGTGGTGAAGACTGCAGGTGGGGTGTGCAAGTTCTCTGGACAGCGACTGAGCTGGTGGCAGGCCCAAGAGTCCTGCGAGCAGCAGTTTGGCCACTTGGCACTGCAGCCCCCTGATGGGGTTCTTGCTTCACGGCTGCGCGATCCGGTCTGGGTGGGCCAAAGAGAGGCCCCTCTGCGGAGACCCCCACAGAGGCGTGCGCGCACCACCGCCGTGCTGGTGTTCGACGAGAGGACGGCTGACCGGGCGGCGCGGCTGCGGAGCCCTCTGCCTGAGCTGGCAGCGCTGACCGCGTGTACTCACGTGCAGTGGGACTGTGCCTCGCCCGACCCCGCAGCGCTCTTCTCCGTTGCCGCGCCCGCGCTGCCCAACGCGCTGCAGCTGCGCGCCTTCGCCGAGCCGGGGGGCGTCGTGCGCGCTGCGCTGGTGGTGCGTGGGCAGCACGCGCCCTTCCTCGCAGCCTTCCGCGCCGACGGCCGCTGGCACCATGTGTGCGCCACGTGGGAGCAGCGGGGCGGGCGCTGGGCGCTGTTCTCCGATGGGAGGCGGCGCGCTGGGGCGCGGGGGCTGGGCGCCGGCCACCCGGTGCCGTCCGGCGGCATCCTGGTGCTGGGCCAGGATCAGGACTCTCTGGGCGGTGGCTTCTCGGTGCGTCACGCCCTCAGCGGCAACCTCACCGACTTCCACCTGTGGGCGCGGGCGCTGAGCCCCGCTCAGCTGCACCGGGCACGGGCCTGCGCGCCGCCCTCAGAGGGCCTGCTCTTCCGCTGGGACCCGGGCGCCCTGGACGTCACGCCCTCGCTGCTGCCCACTGTGTGGGTGCGCCTTCTCTGTCCCGTGCCCTCCGAGGAGTGCCCTACGTGGAACCCGGGACCTCGCAGTGAGGGCTCTGAGCTCTGCCTGGAGCCGCAGCCCTTCCTCTGCTGCTACCGGACAGAGCCCTATCGTCGGCTGCAGGATGCCCAGTCGTGGCCTGGCCAGGATGTTATCAGCCGAGTCAATGCCTTGGCCAACGACATTGTGCTCCTCCCGGACCCCCTCTCCGAAGTCCATGGGGCCCTGTCCCCAGCGGAGGCCTCCAGCTTCCTGGGCCTTCTGGAGCATGTCCTGGCGATGGAGATGGCTCCCCTGGGGCCGGCCGCACTGCTGGCTGTTGTCCGCTTCCTGAAGAGGGTGGTGGCCCTCGGGGCTGGGGACCCAGAGCTGTTGTTGACAGGCCCCTGGGAGCAGCTGAGCCAAGGCGTTGTATCTGTGGCCAGCCTGGTCCTGGAGGAGCAGGTGGCTGACACATGGCTCTCCCTCCGTGAAGTGATTGGTGGGCCTATGGCCCTGGTGGCGAGTGTGCAGCGCCTGGCACCCCTGCTGAGCACCTCAATGACCTCAGAGCGGCCCCGAATGCGCATCCAGCACCGCCATGCTGGCCTCTCTGGAGTCACCGTGATCCACAGCTGGTTCACCTCCAGAGTCTTCCAGCACACCCTAGAGGGACCGGACCTAGAGCCCCAGGCCCCTGCCAGCTCAGAGGAGGCAAACAGGGTGCAGAGGTTCCTAAGCACCCAGGTGGGGTCAGCCATCATCTCCTCTGAAGTGTGGGACGTCACTGGAGAGGTCAACGTGGCCATGACCTTTCATCTCCAGCACCGGGCCCAGAGCCCCCTGTTCCCTCCCCATCCCCCAAGCCCATATACAGGGGGTGCCTGGGCCACCACAGGCTGCTCCGTGGCTGCCCTGTACCTGGACTCCACCGCCTGCTTCTGCAACCACAGCACCAGCTTTGCCATCCTGCTGCAAATCTATGAAGTACAGAGAGGCCCTGAGGAGGAGTCGCTGCTGAGGACTCTGTCATTTGTGGGCTGTGGCGTGTCCTTCTGCGCCCTCACCACCACCTTCTTGCTCTTCCTGGTGGCCGGGGTCCCCAAGTCAGAGCGAACCACAGTCCACAAGAACCTCACCTTCTCCCTGGCCTCTGCCGAGGGCTTCCTCATGACCAGCGAGTGGGCCAAGGCCAATGAGGTGGCATGTGTGGCTGTCACAGTCGCAATGCACTTCCTCTTTCTGGTGGCATTCTCCTGGATGCTGGTGGAGGGGCTGCTGCTGTGGAGGAAGGTGGTAGCTGTGAGCATGCACCCGGGCCCAGGCATGCGGCTCTACCACGCCACAGGCTGGGGCGTGCCTGTGGGCATCGTGGCGGTCACCCTGGCCATGCTCCCCCATGACTACGTGGCCCCCGGACATTGCTGGCTCAATGTGCACACAAATGCCATCTGGGCCTTCGTGGGGCCTGTGCTCTTCGTGCTGACTGCCAACACCTGCATCCTGGCCCGTGTGGTAATGATCACCGTGTCCAGTGCCCGCCGCCGTGCCCGCATGTTGAGCCCACAGCCCTGCCTGCAGCAGCAGATCTGGACCCAGATATGGGCCACGGTGAAGCCCGTGCTGGTCCTGCTGCCCGTCCTAGGCCTGACCTGGCTGGCAGGCATCCTGGTGCACCTGAGCCCCGCCTGGGCCTACGCTGCCGTGGGCCTCAACTCCATCCAGGGGCTGTACATCTTCCTGGTTTATGCTGCCTGCAATGAGGAGGTGCGGAGCGCCCTGCAGAGGATGGCTGAGAAGAAGGTGGCCGAGGTGCTCAGGGCACTGGGGGTGTGGGGGGGCGCTGCCAAGGAGCACAGCCTGCCTTTCTCTGTCCTCCCCCTCTTTCTGCCCCCTAAGCCCAGCACCCCCCGTCACCCTCTGAAGGCCCCGGCCTGA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.