NCBI Summary
The protein encoded by this gene belongs to the immunoglobulin superfamily. It is a type I membrane protein and may function in selective fasciculation and zone-to-zone projection of the primary olfactory axons. [provided by RefSeq, Jul 2008].
Protein
Protein (NP_004531)
Neural cell adhesion molecule 2
Neural cell adhesion molecule 2 (N-CAM-2) (NCAM-2)
NCAM2
neural cell adhesion molecule 2
Undefined
Very low evidence
I-type lectin
I-Type Lectins
b-sandwich / Ig-like
MSLLLSFYLLGLLVSSGQALLQVTISLSKVELSVGESKFFTCTAIGEPESIDWYNPQGEKIISTQRVVVQKEGVRSRLTIYNANIEDAGIYRCQATDAKGQTQEATVVLEIYQKLTFREVVSPQEFKQGEDAEVVCRVSSSPAPAVSWLYHNEEVTTISDNRFAMLANNNLQILNINKSDEGIYRCEGRVEARGEIDFRDIIVIVNVPPAISMPQKSFNATAERGEEMTFSCRASGSPEPAISWFRNGKLIEENEKYILKGSNTELTVRNIINSDGGPYVCRATNKAGEDEKQAFLQVFVQPHIIQLKNETTYENGQVTLVCDAEGEPIPEITWKRAVDGFTFTEGDKSLDGRIEVKGQHGSSSLHIKDVKLSDSGRYDCEAASRIGGHQKSMYLDIEYAPKFISNQTIYYSWEGNPINISCDVKSNPPASIHWRRDKLVLPAKNTTNLKTYSTGRKMILEIAPTSDNDFGRYNCTATNHIGTRFQEYILALADVPSSPYGVKIIELSQTTAKVSFNKPDSHGGVPIHHYQVDVKEVASEIWKIVRSHGVQTMVVLNNLEPNTTYEIRVAAVNGKGQGDYSKIEIFQTLPVREPSPPSIHGQPSSGKSFKLSITKQDDGGAPILEYIVKYRSKDKEDQWLEKKVQGNKDHIILEHLQWTMGYEVQITAANRLGYSEPTVYEFSMPPKPNIIKDTLFNGLGLGAVIGLGVAALLLILVVTDVSCFFIRQCGLLMCITRRMCGKKSGSSGKSKELEEGKAAYLKDGSKEPIVEMRTEDERVTNHEDGSPVNEPNETTPLTEPEKLPLKEEDGKEALNPETIEIKVSNDIIQSKEDDSKA
Mol* PDB structure viewer
Structural models
SWISS-MODEL structural models
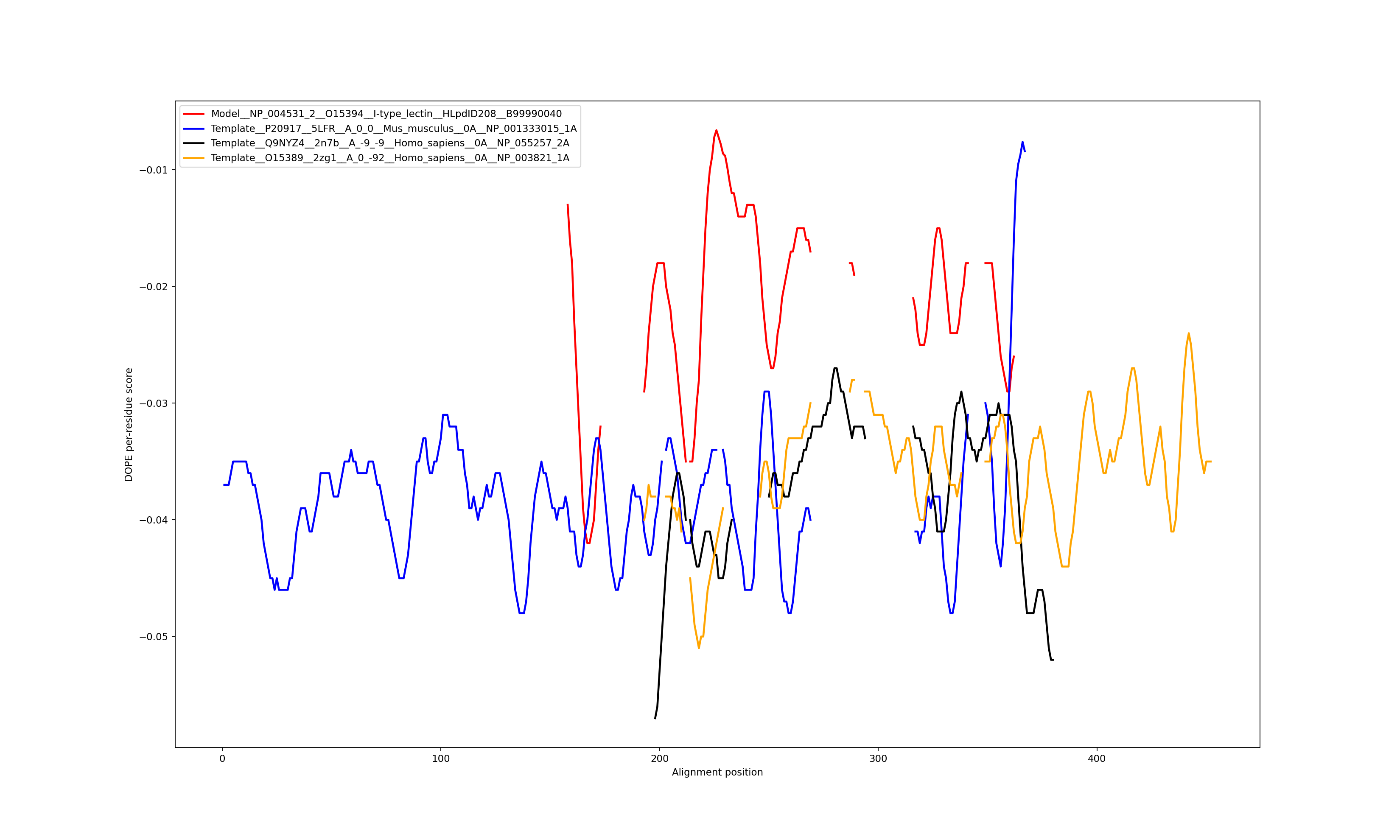
The location of the lectin domain structural model is: 167-302
We infer [1.63, 2.13] Å as the interval of error of this structural model.
Template 1: 5LFR chain: A, P20917, NP_001333015.1, sequence identity: 22.8%, coverage: 94.1%, location in sequence: 19-331, (19-331 in PDB).
Template 2: 2N7B chain: A, Q9NYZ4, NP_055257.2, sequence identity: 18.4%, coverage: 72.8%, location in sequence: 26-152, (10-136 in PDB).
Template 3: 2ZG1 chain: A, O15389, NP_003821.1, sequence identity: 17.6%, coverage: 71.3%, location in sequence: 20-141, (25-146 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
We infer [1.63, 2.13] Å as the interval of error of this structural model.
Template 1: 5LFR chain: A, P20917, NP_001333015.1, sequence identity: 22.8%, coverage: 94.1%, location in sequence: 19-331, (19-331 in PDB).
Template 2: 2N7B chain: A, Q9NYZ4, NP_055257.2, sequence identity: 18.4%, coverage: 72.8%, location in sequence: 26-152, (10-136 in PDB).
Template 3: 2ZG1 chain: A, O15389, NP_003821.1, sequence identity: 17.6%, coverage: 71.3%, location in sequence: 20-141, (25-146 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- Spatiotemporal processing of neural cell adhesion molecules 1 and 2 by BACE1 in vivo. [33548223]
- NCAM2 Fibronectin type-III domains form a rigid structure that binds and activates the Fibroblast Growth Factor Receptor. [29895898]
- NCAM2 deletion in a boy with macrocephaly and autism: Cause, association or predisposition? [27596683]
- Abeta-dependent reduction of NCAM2-mediated synaptic adhesion contributes to synapse loss in Alzheimer's disease. [26611261]
- NCAM2/OCAM/RNCAM: cell adhesion molecule with a role in neuronal compartmentalization. [22155300]
- Crystal structure of the Ig1 domain of the neural cell adhesion molecule NCAM2 displays domain swapping. [18706912]
- Time-controlled transcardiac perfusion cross-linking for the study of protein interactions in complex tissues. [15146195]
- Identification and quantification of N-linked glycoproteins using hydrazide chemistry, stable isotope labeling and mass spectrometry. [12754519]
- Differential function of RNCAM isoforms in precise target selection of olfactory sensory neurons. [12538518]
- Cloning of a novel human neural cell adhesion molecule gene (NCAM2) that maps to chromosome region 21q21 and is potentially involved in Down syndrome. [9226371]
UniProt Main References (3 PubMed Identifiers)
- Complete sequencing and characterization of 21,243 full-length human cDNAs. [14702039]
- The DNA sequence of human chromosome 21. [10830953]
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_004540.5)
neural cell adhesion molecule 2, transcript variant 2
m7G-5')ppp(5'-ACUUUGCGAGGAGGAGCGCGCGGGCUGCGGGCGGCUGGGGCACCGCGGGAGCGGCGGCGGCGGCUCUAGCAGAGGCGGCCGGGGCAGCGAAAGGUUCUCUCUCCAGGGCUGGACUUAAUAACUUUGAAACUGUCCACCGGUGUCACGUCCUGAACAUGAGCCUCCUCCUCUCCUUCUACCUGCUGGGGUUGCUUGUCAGUAGCGGGCAAGCUCUUCUUCAAGUGACAAUUUCACUUAGCAAAGUAGAGCUUAGUGUUGGAGAAUCUAAAUUCUUCACAUGUACAGCGAUUGGUGAACCUGAAAGUAUAGAUUGGUAUAAUCCUCAAGGAGAGAAGAUAAUUUCAACACAGAGGGUAGUAGUGCAAAAGGAAGGUGUUAGGUCACGGUUAACCAUCUACAAUGCAAAUAUAGAAGAUGCAGGGAUAUAUCGUUGUCAAGCAACAGAUGCCAAAGGACAAACACAAGAAGCUACAGUAGUUUUGGAAAUUUACCAAAAACUCACUUUCAGAGAAGUGGUAUCUCCACAAGAAUUCAAACAAGGAGAAGAUGCAGAAGUGGUUUGCCGAGUUAGCAGUUCACCUGCACCUGCUGUCAGCUGGUUGUAUCAUAAUGAGGAAGUCACCACUAUUUCCGACAAUCGGUUCGCUAUGUUAGCAAACAAUAACCUGCAGAUUCUCAACAUCAAUAAAAGUGAUGAAGGUAUAUACAGAUGUGAAGGAAGAGUGGAGGCCAGGGGAGAAAUUGACUUCCGUGAUAUCAUUGUUAUUGUUAAUGUGCCGCCAGCAAUCUCAAUGCCUCAGAAAUCUUUUAAUGCCACAGCAGAGAGAGGAGAAGAAAUGACAUUUUCCUGCAGGGCCUCAGGCUCUCCAGAACCCGCCAUCUCCUGGUUCAGGAAUGGCAAGCUCAUUGAAGAAAAUGAGAAGUACAUAUUGAAAGGGAGCAAUACAGAACUCACUGUCAGGAACAUAAUCAAUAGUGAUGGUGGUCCUUAUGUCUGCAGGGCCACAAAUAAGGCAGGAGAAGAUGAAAAGCAAGCUUUCCUCCAAGUCUUUGUACAGCCUCACAUAAUACAGCUUAAAAAUGAAACUACAUAUGAGAAUGGUCAAGUCACACUCGUAUGUGAUGCGGAAGGGGAGCCUAUUCCAGAAAUCACUUGGAAAAGAGCUGUGGAUGGCUUCACGUUCACUGAAGGCGAUAAGAGCCUGGACGGCCGUAUCGAAGUCAAAGGGCAGCAUGGAAGCUCAUCACUGCAUAUUAAAGAUGUGAAGUUGUCAGAUUCAGGGAGAUAUGACUGUGAAGCUGCAAGCAGAAUUGGAGGGCAUCAAAAGAGCAUGUACCUUGAUAUUGAAUAUGCCCCCAAGUUUAUAUCAAACCAAACAAUUUAUUACUCUUGGGAAGGAAAUCCUAUCAAUAUAAGUUGUGAUGUGAAAUCGAAUCCACCAGCAUCAAUUCACUGGAGAAGAGAUAAAUUAGUCUUACCUGCUAAAAACACGACCAAUUUAAAGACUUAUAGUACAGGAAGAAAGAUGAUAUUAGAGAUUGCACCUACAUCUGACAAUGACUUUGGACGCUAUAAUUGCACAGCCACUAAUCAUAUAGGAACAAGAUUUCAAGAAUAUAUUCUUGCUUUGGCUGACGUGCCAUCCAGUCCCUAUGGAGUGAAGAUCAUAGAGCUGUCGCAGACCACGGCCAAGGUUUCCUUCAACAAACCGGACUCCCAUGGAGGUGUACCUAUUCAUCACUAUCAGGUGGAUGUCAAAGAAGUAGCGUCAGAAAUCUGGAAAAUUGUACGCUCCCAUGGAGUUCAAACAAUGGUUGUUUUGAACAACCUGGAACCAAAUACAACUUAUGAAAUCAGGGUUGCAGCUGUAAAUGGAAAGGGACAAGGAGACUACAGUAAAAUAGAAAUCUUCCAAACAUUACCAGUUCGUGAACCAAGUCCUCCAUCCAUACAUGGACAGCCAAGCAGUGGAAAGAGCUUUAAACUCAGCAUCACCAAACAGGACGAUGGAGGGGCCCCUAUUUUGGAAUACAUUGUGAAAUAUAGAAGUAAAGAUAAGGAAGACCAAUGGCUAGAGAAAAAAGUGCAAGGAAAUAAAGACCACAUCAUUUUGGAGCAUCUCCAGUGGACCAUGGGGUAUGAAGUUCAGAUUACAGCUGCCAAUAGAUUGGGAUAUUCUGAACCGACAGUUUAUGAAUUCAGCAUGCCACCAAAGCCCAACAUUAUUAAAGACACGCUGUUUAAUGGUCUUGGGCUUGGAGCAGUAAUUGGCCUGGGAGUUGCUGCACUGCUGCUAAUUCUUGUGGUAACAGACGUCAGCUGCUUCUUUAUUCGGCAAUGUGGGUUGCUGAUGUGCAUCACUAGGAGAAUGUGUGGAAAGAAAAGUGGCUCCAGUGGCAAAAGUAAAGAACUCGAAGAAGGAAAAGCUGCAUACCUGAAAGAUGGAUCAAAAGAACCAAUAGUGGAGAUGAGAACAGAGGAUGAAAGAGUUACUAAUCACGAAGAUGGGAGCCCAGUAAAUGAGCCAAAUGAAACCACACCACUGACAGAACCUGAAAAAUUGCCUUUAAAGGAAGAAGAUGGGAAAGAAGCUCUAAAUCCAGAAACUAUAGAAAUUAAAGUUUCUAACGACAUCAUUCAAUCAAAAGAAGACGACAGCAAAGCAUAACAACAAUAUUACAGGGGCUUGAACAACACUACGAAGAGUAUUUGGAUUGCGUGACCCUAUGACCAAAACUAUUCCAUUGACCUUAAUUUCUUGGGAAACUUCUAGCUUGGAAUAGCUUGUACACAUAUACAUAUGAUCAAAUACUCCUGCCCAUGAUCCAUUCCCUUUUGUUAUUGUUGUUGUUGUUGCUGUUGUUGUUAAUUUUGUUAAGAAUUUCAAUAUCAAGACUGACUGGCACCAACACUUUGGUAUUCAAUUUGAUUCUAUGACUGAAGUACUGGAAUUUAUUAUGUGGCUAAAGUGCUCUAUUUAUUAAGAACUAUAUUUAAUACCACCAACAAAUAUAGGGGUUAAGGAAAAAAAACGUGAGCUACAUGUGUAAGAAGGCCCUGCAUGUGUAUGAGUCCUAUUCUGGGCAAAUAGAUUCUUAAAGUGGCUUUCAACUUCAAGAUGAAGGAGCUUAAUAAUGGUUACUCAUUUUAUCAGGGGAAUUUCAGGGAACGUAGGCGUCAAAGAGCCAGUUAUCUUUAGCAGAUAUUAAAAAUUGAAAACUUUGGAGAACUCAUUUCAAGUUAUGAUUCAGUGCAUUUUCAACAUUGAUUUUUGAUAGACUGAAGUGCCAGAUCAAAAUUGUUACCCAUUUGAAAGAAUAUUAGUUGUAUAUAAAAUUAGAUUAGAAAGACUUUCUAAAUCUCUAUCUCUUUAUAUAUGUCCUAUUCAUUCACAAUGGAUUAUACAAAAAAAAGUGUAUUGCAAGUGAAAUAAUAUUGAUUUCUGCCCUCAGCUUCAAAUAAAGUAAAUUGAAAUGGGAACAAUAUCAAUAUGGUGUCUUGAUAUAUUUAUAAAUAUGUGAUUAUCAUUUAUUUUUAAAAUAAUUUAUCAAAAAACAAGUCUUUAGUGUUCAAAUACUUCAAAUCAUAUCCUCAGAUAUAUUUUUAGCCCAUGGUUUUAUAUAAUCUUUAAGAACUAAUUUUACCACUGUUAUAGGUUCACCAUUAAAUAUAAUUGGCUAAUAAAAAUUUUAAGGUUGACUAAAUUAAGAAGAAAUUAUUUAACAUUUUAAUGUGCCAUAAAAGAGUAAAUGAUAAAUAAUUAAAUGCCACUAUGUGUUCUAUUCCGGAUGUUCUAGCUAGAAGUCAUUUUAAGAUUUUGAUAAACAACUUUGGUUGAAGAAAUUCCUUAAGUAUUCAACACAAACUUUCUAAUAUCUUUUGUUAGGGUUAUACCAGAAUAAAAUGCUUCUUUACUUCCAAGCUAUGCAAGCUCCCAGAGGUAAUAGAGUGACACAUGAUUUAACUUAUAUGUAAGGUUUAAAAAAGUAUUUAUCAUUAUAAACAUACAUACCAUUUGGGAGCAGGUUUAUUAACCUUGAGAGCCAAAGGUUUCCUUAGGCCCUGUAACAUUCAGAACCUUUGGUGUUUCAGGUGGUAUUAUAGCUCAAAUAGUGACAGGACAGGGAAUGCGUUCCAAAGGAAUAUUGGAGCAAUUUUAACAUUGCAGAAACCUGCUCUGGGUGUGUCUCUCUGUAGAGAUAACCUGAUGAUUAUUAAAUGUAAAAUUAAGGCAACUCAUGAAUAUUUUUAUUUACAAAGUGCUUGAAACUCAGCCAAGGAGAGAAAACUAAGUACUUUUAUAUAAUUCAUCACUUUUCUGGCUACAGCAGGACAGAAUAUGACCAUCUUCGUUUGAAGGCACCAAAUCGUCGCAGUGUCUUUGCCAUAAGUUGCAGGGUUAAAUGCGGGAAUCUCUCCUUGCGUUCCUGUCUGGCGUAUUCUGAAGAAAAGAACAGAAUUCUUGUGCCUACCUAAGAAUUUGAGUAGUGUCUAAACAAACAAAGCAGUUAGGUCAUUUUAACUGACUUGAUUAUCCAACUGGUCUUUGACAGAUUUGACUGUUCAUAUUUAGUUUAUGUUUGUCUGAUCAUCCAGUUUGCUUUAUUUUGCUGUGUUUUAUUUUGUUGUUUGUUUUGUUUUGUACCAGUGUACUAAAACUAGUCAAAAUACUUGAAUUAGUUUGUUUGUGCAAAGUGUACAAGCUUAGUAAAGUGUCCAUGAAGCAAUAGCCAUGAAUGCUAAUUAUUUCUAAAUAGGGCCACAUGGUUUUAAACUAAUGAUGGUGAAAGAAAUACGAUGACUGAGAAAGUCAUUUCGCAUGUUUACUAUUGUUAUAUUCGUGCUUUACUUCAAGAGUGCAGAAAUCAUAAUAAAUAACAAACUAUUUUUGUGUUUUCUCAAUGUGACAUUUCUGUUUCUCUCAUUUAUUCGGAUUUUCCUUGUAAAGAAAUUGACAUAUAUUUCAUAUAUAUAUACACAUAUAUAUAUAUACACAUAUAUAUACAUAUAUAUAUAUGAUGUUAAAUUUCCUGCCACUCAUGUGGAGUAAUGAUCUGAAAUUAACAGAUAAUCUGAAGCUAAUUAUAUUCAGACUAUUUCAAGUGCACUGUUUCAGUUGCCCGGGUGGUCCUUACCUCUUGUCCUUGAAAUCCAUGCCAUGCUGAAGCAAGGCAAUACUGUGAUAAAGUAUUUUUUUUAAUAUUUCAAUGGAAUGCUCCAAAUGAUUUAUAAAAAUUUCAAAAUAAAAGAUGGCUUGUAGUAAAUUGUAAAAUAUGAGUAGAACUGAAAUAACCUGUUUCAUUCUUAUUCUAGAUUAAACAAACAUAUACAUAUAACCAUAUAAAUGUUAUUUUUAUUGUCUGAGAGUACUCUUAAAUAUUAGUAUAAAGUGUCAAAAGAAUUGACUGAAUAUAAGUACUGUUAAAAUAAUUUGAACCCUAUGAUAUUUUAAACCAAGAGGCAAAGAUAUCACCUAAAACUUGGUAUUUCUUGAUAGGUUAGGUGCAAUUAGGCAGUGACAAUCUGUAUUCAACAACAUAUAAGAGGAAAGAGUAAUAUCAGAAUUUUGACACAAAUUAAUGUGUCAACAUAUUUUACAAUGAUUGUCAAAGGAAUUUAAGAAUUGUAUUUUUAAAGAUUUAUUUAUUAUUUUUGUGGGCUAAGACAUUGCCAUUCUAUUGAUACUAAUGUCUAACAUUAAUGUUUCUUGUUUUCUUUUAUUUUUAAUAUUAAUAACUAUAAAAGCAUUUUUCAAAGGCUAUUUGAUCCAGCACACUUCAUAUGGAUCUUAGUCUUUGAAUUAAAUAUUUAUAUAAAUAGAUUUUAUUAAUCAAAUUAUUUAUUUGUGUGCCAACAAUUAAUUGUAACUUUAUGAUCAUAUCUUUGUUUAUGCUUCUUAUUUUAAAUAAUUAAGAUGUAUCUGUGCCUUUUAAUUAGCAUGACAGUCUGCUUUAUUAAAAGAAAAAAACUACAAUUAACAUCAUUACUAGUAUAUUUUGCUUAGAUUUGAGAUACUCAAAUGAUGCUGUCUUAUUUACAGUCAGUAAUUAAGUUCAAUUCAAACUAUUUUACCUUGAAUAUAAAAUCUAAAUAUAAUAAACUAUACUGUAUAAUUUACUUUAAUUCAUGUCAAAACAAUUCUUUUUAUACACACACAUGAAAUAUUCUUAAUCUGUUCUGUAUUGUUUUUCUAAACAAUAAAUACAUUCUAGAUAUUGUUGAAAUUAAAUUUUGCCAGUUGUAAGACAAAGACAACAGAUAACUUUUGAAAAUCAAGCAAAUUACUAUGGUGUUUCUUGGGUCUUCAUUAUUCCAUUUAUAUAUAUUUUUUAUUUCGAAUAAUAAAUCAACCUUUAUUUUUGGCAAUAAGAUUAUCACUGACGAAAAUAUGUACAGUUCAAGAAGUAGAAAUAAUAUUUUCCAUUAGUUAAUUUAGGAAAUAUUGGAAUAGCAUAUUAUAAUUAUUUAUGAGGUUCCCAAUGUUGUUUUUCACAGAAAAUAAGGUAAACAUUCAACUUAAAUCCCCCAUGAAGUUUUUUCAUGCUCAUACUCAUAAUCAUUAUCACAUAAUGUGCUUAUUCAACAAACUUUGUAUCUGGAUAUAUUUUUAACAAUAAGUUUGUUAGCAUUAUUUAUUUAUCUUUAGAGAGAAAAUAUUUGCAUCUGUUUAUUUACCCUUUGAAGCAUUAAUACUUAGUCACUCACAUUGAAAUUGCAUAUGGAUGUAUCAACAUAGGCUAAAAUUAAAUUAUGGAUGUCGCAGAAAUGAAAUACUUCAUCUUAGAAGGUAAAAUUUUCAAGAAAGUAUUUUAUUCAUGGACUUAAUAAUGUCUUAAGAUGAAACAAUUUUAUGUCCAAAUGAGAAAUUUAUAAAAAGACCCACAUAUAGUAGUUGCUGAACAAACAUAAUUUUCUUCCAGCUCCCAUCCUUCCUUUUUGAAAAAUUGAAUUUACCCAUGUAGAUGCAGCUAUUUACAAUUAUACAAGAAUGCGAAUAGAUUAAUUAUAUCUUCUCAUAUAAAGGCAAAGAAUUUUAUAUUAUAUAUAAUGCUAAAUAUUUAUUUGAUAACACAAUAUUCUUAGAAAAAUAGUUUAUUACUUUAGGAUUUUAUCUAUAACAUAAAUAUAUUAUUUGUUAUUACCUCUUUAAAUUUUCAUUUUAUACAAUUUUUGAGAUUCUGGCCACACAACAUUCAGAAUUAUUGCUCAUGUAAAUUUAAAUAUUGCUACUUAUUUUUUUUCUUUUCUGAAAUGAAAACAUGAAUCUUUUGGCAUCUGUUUUUAGCCUCCCAUGGAAGACAGUAAGCAAAACCAUCACUGUUGGAGAAUUUCAAAUCACAACCCGACAUAGGAGAGUAGAGAAACAAAGAAAUGAGUGGAUCUAGAAAGGCAAACUGAAUUGCUAUAUUUGGAAUAGCUAAGAAGGACCUGACUUUGAGAAGUGCUAGACCAGGGACUAGGAACGUUGCUUAGAUAAAAAUUAUGGCCGAUUACACUGAUGCGAAGGAGAAAACAGUGUAACACAGAGGAGAAAGUUAACAGAGAUAGAAUCUAUGAUUUAAUUUUGCAAAUAGUUUUUUUAGAGAACAACAUGCAUACUAUAAAAGAAAUGAUACUAUUAAGAACAAACCUACUUGUUCCAACUCUUAAAGAAAUAUUCAUGGUUUAGCAUUUGCCUCUAAACCCUGUUAGAAAUAUGUGAAGUUAGAAAUAAAGGUUUUUUUAAAAAAAAAGCUUUUUUGGUAUGUGAACUGUAUGCUGUGCUCAGUAUGUACUGAAACAUACUAUCUUUUAUUUUCUUUAAUUUAUAUAUUCCAUUCAAAUUCUAUAUUCUUAAGUUAGCUACCACAACGUUUUCUUAUUGUUUCAAUAUGGUAUGUCCCAAUGAAAUGCUGUAUAUAUAUGUCUAAACUGUAAAAAUUAUACUGCAAAUGUUGAAGUUUUGUAUUUAUGAGAGACAUUGAAAGUAUGGCUUACAGUAUAUCAAACUUGUCACACUUCACCAUUUGUAUAUUAAUAGUAAAGAUACUUUUACUUUAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 4685)
neural cell adhesion molecule 2
strand +
NCAM21, MGC51008
NCBI CDS gene sequence (2514 bp)
5'-ATGAGCCTCCTCCTCTCCTTCTACCTGCTGGGGTTGCTTGTCAGTAGCGGGCAAGCTCTTCTTCAAGTGACAATTTCACTTAGCAAAGTAGAGCTTAGTGTTGGAGAATCTAAATTCTTCACATGTACAGCGATTGGTGAACCTGAAAGTATAGATTGGTATAATCCTCAAGGAGAGAAGATAATTTCAACACAGAGGGTAGTAGTGCAAAAGGAAGGTGTTAGGTCACGGTTAACCATCTACAATGCAAATATAGAAGATGCAGGGATATATCGTTGTCAAGCAACAGATGCCAAAGGACAAACACAAGAAGCTACAGTAGTTTTGGAAATTTACCAAAAACTCACTTTCAGAGAAGTGGTATCTCCACAAGAATTCAAACAAGGAGAAGATGCAGAAGTGGTTTGCCGAGTTAGCAGTTCACCTGCACCTGCTGTCAGCTGGTTGTATCATAATGAGGAAGTCACCACTATTTCCGACAATCGGTTCGCTATGTTAGCAAACAATAACCTGCAGATTCTCAACATCAATAAAAGTGATGAAGGTATATACAGATGTGAAGGAAGAGTGGAGGCCAGGGGAGAAATTGACTTCCGTGATATCATTGTTATTGTTAATGTGCCGCCAGCAATCTCAATGCCTCAGAAATCTTTTAATGCCACAGCAGAGAGAGGAGAAGAAATGACATTTTCCTGCAGGGCCTCAGGCTCTCCAGAACCCGCCATCTCCTGGTTCAGGAATGGCAAGCTCATTGAAGAAAATGAGAAGTACATATTGAAAGGGAGCAATACAGAACTCACTGTCAGGAACATAATCAATAGTGATGGTGGTCCTTATGTCTGCAGGGCCACAAATAAGGCAGGAGAAGATGAAAAGCAAGCTTTCCTCCAAGTCTTTGTACAGCCTCACATAATACAGCTTAAAAATGAAACTACATATGAGAATGGTCAAGTCACACTCGTATGTGATGCGGAAGGGGAGCCTATTCCAGAAATCACTTGGAAAAGAGCTGTGGATGGCTTCACGTTCACTGAAGGCGATAAGAGCCTGGACGGCCGTATCGAAGTCAAAGGGCAGCATGGAAGCTCATCACTGCATATTAAAGATGTGAAGTTGTCAGATTCAGGGAGATATGACTGTGAAGCTGCAAGCAGAATTGGAGGGCATCAAAAGAGCATGTACCTTGATATTGAATATGCCCCCAAGTTTATATCAAACCAAACAATTTATTACTCTTGGGAAGGAAATCCTATCAATATAAGTTGTGATGTGAAATCGAATCCACCAGCATCAATTCACTGGAGAAGAGATAAATTAGTCTTACCTGCTAAAAACACGACCAATTTAAAGACTTATAGTACAGGAAGAAAGATGATATTAGAGATTGCACCTACATCTGACAATGACTTTGGACGCTATAATTGCACAGCCACTAATCATATAGGAACAAGATTTCAAGAATATATTCTTGCTTTGGCTGACGTGCCATCCAGTCCCTATGGAGTGAAGATCATAGAGCTGTCGCAGACCACGGCCAAGGTTTCCTTCAACAAACCGGACTCCCATGGAGGTGTACCTATTCATCACTATCAGGTGGATGTCAAAGAAGTAGCGTCAGAAATCTGGAAAATTGTACGCTCCCATGGAGTTCAAACAATGGTTGTTTTGAACAACCTGGAACCAAATACAACTTATGAAATCAGGGTTGCAGCTGTAAATGGAAAGGGACAAGGAGACTACAGTAAAATAGAAATCTTCCAAACATTACCAGTTCGTGAACCAAGTCCTCCATCCATACATGGACAGCCAAGCAGTGGAAAGAGCTTTAAACTCAGCATCACCAAACAGGACGATGGAGGGGCCCCTATTTTGGAATACATTGTGAAATATAGAAGTAAAGATAAGGAAGACCAATGGCTAGAGAAAAAAGTGCAAGGAAATAAAGACCACATCATTTTGGAGCATCTCCAGTGGACCATGGGGTATGAAGTTCAGATTACAGCTGCCAATAGATTGGGATATTCTGAACCGACAGTTTATGAATTCAGCATGCCACCAAAGCCCAACATTATTAAAGACACGCTGTTTAATGGTCTTGGGCTTGGAGCAGTAATTGGCCTGGGAGTTGCTGCACTGCTGCTAATTCTTGTGGTAACAGACGTCAGCTGCTTCTTTATTCGGCAATGTGGGTTGCTGATGTGCATCACTAGGAGAATGTGTGGAAAGAAAAGTGGCTCCAGTGGCAAAAGTAAAGAACTCGAAGAAGGAAAAGCTGCATACCTGAAAGATGGATCAAAAGAACCAATAGTGGAGATGAGAACAGAGGATGAAAGAGTTACTAATCACGAAGATGGGAGCCCAGTAAATGAGCCAAATGAAACCACACCACTGACAGAACCTGAAAAATTGCCTTTAAAGGAAGAAGATGGGAAAGAAGCTCTAAATCCAGAAACTATAGAAATTAAAGTTTCTAACGACATCATTCAATCAAAAGAAGACGACAGCAAAGCATAA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.