NCBI Summary
The protein encoded by this gene is an axonal glycoprotein belonging to the immunoglobulin supergene family. The ectodomain, consisting of several immunoglobulin-like domains and fibronectin-like repeats (type III), is linked via a single transmembrane sequence to a conserved cytoplasmic domain. This cell adhesion molecule plays an important role in nervous system development, including neuronal migration and differentiation. Mutations in the gene cause X-linked neurological syndromes known as CRASH (corpus callosum hypoplasia, retardation, aphasia, spastic paraplegia and hydrocephalus). Alternative splicing of this gene results in multiple transcript variants, some of which include an alternate exon that is considered to be specific to neurons. [provided by RefSeq, May 2013].
Protein
Protein (NP_000416)
L1 cell adhesion molecule
Neural cell adhesion molecule L1 (N-CAM-L1) (NCAM-L1) (CD antigen CD171)
L1CAM
L1 cell adhesion molecule
Curated
I-type lectin
I-Type Lectins
b-sandwich / Ig-like
MVVALRYVWPLLLCSPCLLIQIPEEYEGHHVMEPPVITEQSPRRLVVFPTDDISLKCEASGKPEVQFRWTRDGVHFKPKEELGVTVYQSPHSGSFTITGNNSNFAQRFQGIYRCFASNKLGTAMSHEIRLMAEGAPKWPKETVKPVEVEEGESVVLPCNPPPSAEPLRIYWMNSKILHIKQDERVTMGQNGNLYFANVLTSDNHSDYICHAHFPGTRTIIQKEPIDLRVKATNSMIDRKPRLLFPTNSSSHLVALQGQPLVLECIAEGFPTPTIKWLRPSGPMPADRVTYQNHNKTLQLLKVGEEDDGEYRCLAENSLGSARHAYYVTVEAAPYWLHKPQSHLYGPGETARLDCQVQGRPQPEVTWRINGIPVEELAKDQKYRIQRGALILSNVQPSDTMVTQCEARNRHGLLLANAYIYVVQLPAKILTADNQTYMAVQGSTAYLLCKAFGAPVPSVQWLDEDGTTVLQDERFFPYANGTLGIRDLQANDTGRYFCLAANDQNNVTIMANLKVKDATQITQGPRSTIEKKGSRVTFTCQASFDPSLQPSITWRGDGRDLQELGDSDKYFIEDGRLVIHSLDYSDQGNYSCVASTELDVVESRAQLLVVGSPGPVPRLVLSDLHLLTQSQVRVSWSPAEDHNAPIEKYDIEFEDKEMAPEKWYSLGKVPGNQTSTTLKLSPYVHYTFRVTAINKYGPGEPSPVSETVVTPEAAPEKNPVDVKGEGNETTNMVITWKPLRWMDWNAPQVQYRVQWRPQGTRGPWQEQIVSDPFLVVSNTSTFVPYEIKVQAVNSQGKGPEPQVTIGYSGEDYPQAIPELEGIEILNSSAVLVKWRPVDLAQVKGHLRGYNVTYWREGSQRKHSKRHIHKDHVVVPANTTSVILSGLRPYSSYHLEVQAFNGRGSGPASEFTFSTPEGVPGHPEALHLECQSNTSLLLRWQPPLSHNGVLTGYVLSYHPLDEGGKGQLSFNLRDPELRTHNLTDLSPHLRYRFQLQATTKEGPGEAIVREGGTMALSGISDFGNISATAGENYSVVSWVPKEGQCNFRFHILFKALGEEKGGASLSPQYVSYNQSSYTQWDLQPDTDYEIHLFKERMFRHQMAVKTNGTGRVRLPPAGFATEGWFIGFVSAIILLLLVLLILCFIKRSKGGKYSVKDKEDTQVDSEARPMKDETFGEYRSLESDNEEKAFGSSQPSLNGDIKPLGSDDSLADYGGSVDVQFNEDGSFIGQYSGKKEKEAAGGNDSSGATSPINPAVALE
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
The location of the lectin domain structural model is: 144-328
We infer [1.61, 2.1] Å as the interval of error of this structural model.
Template 1: 5LFR chain: A, P20917, NP_001333015.1, sequence identity: 24.3%, coverage: 91.4%, location in sequence: 19-331, (19-331 in PDB).
Template 2: 2ZG1 chain: A, O15389, NP_003821.1, sequence identity: 15.1%, coverage: 54.1%, location in sequence: 20-141, (25-146 in PDB).
Template 3: 5VKM chain: A, P20273, NP_001762.2, sequence identity: 12.4%, coverage: 57.8%, location in sequence: 23-139, (23-139 in PDB).
Show the alignment used for the construction of the structural model, Download.
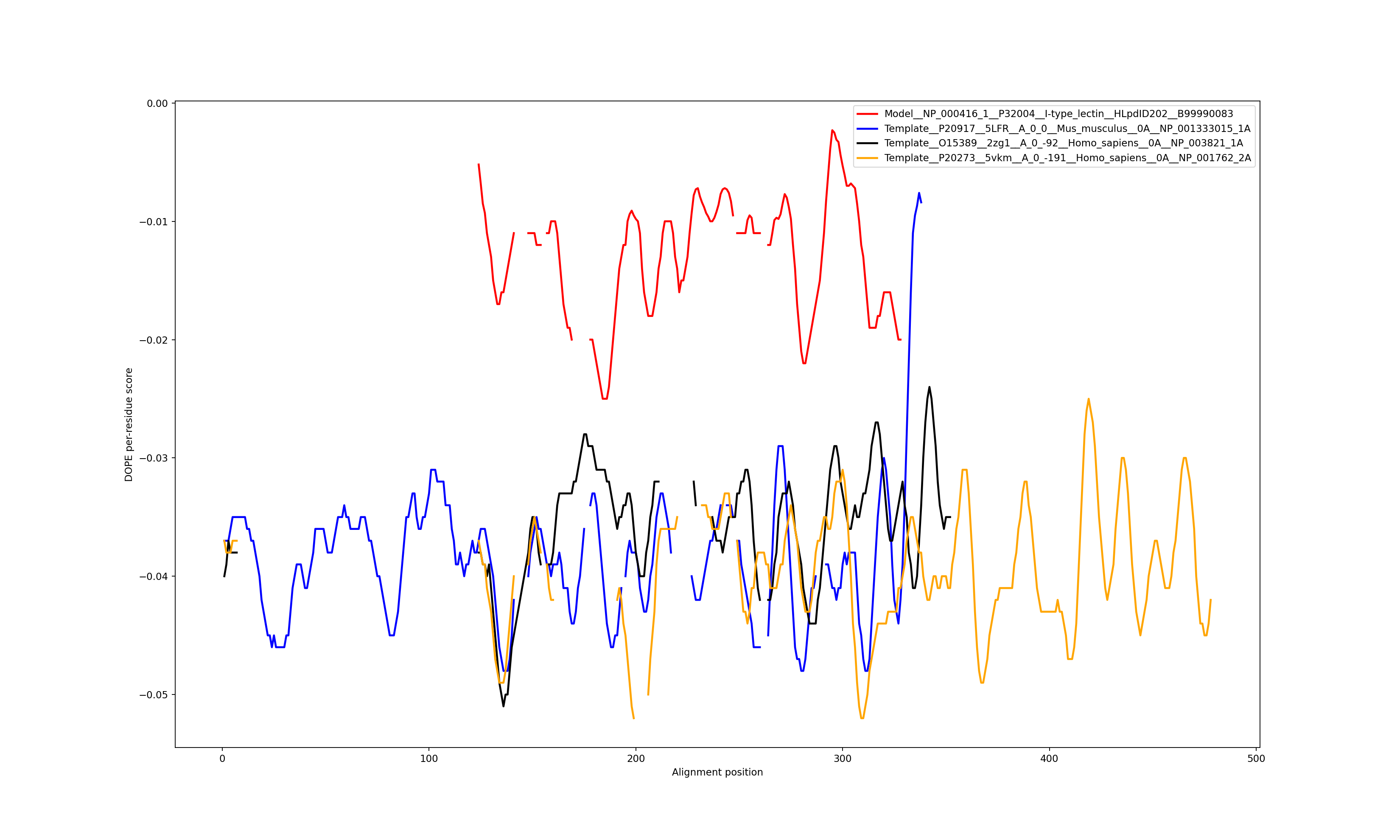
Show the plot of DOPE energy score, Download.
We infer [1.61, 2.1] Å as the interval of error of this structural model.
Template 1: 5LFR chain: A, P20917, NP_001333015.1, sequence identity: 24.3%, coverage: 91.4%, location in sequence: 19-331, (19-331 in PDB).
Template 2: 2ZG1 chain: A, O15389, NP_003821.1, sequence identity: 15.1%, coverage: 54.1%, location in sequence: 20-141, (25-146 in PDB).
Template 3: 5VKM chain: A, P20273, NP_001762.2, sequence identity: 12.4%, coverage: 57.8%, location in sequence: 23-139, (23-139 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
Interacts with SHTN1; the interaction occurs in axonal growth cones (By similarity). Interacts with isoform 2 of BSG (By similarity)
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- L1CAM is not associated with extracellular vesicles in human cerebrospinal fluid or plasma. [34092791]
- Full-length L1CAM and not its Delta2Delta27 splice variant promotes metastasis through induction of gelatinase expression. [21541352]
- L1CAM expression in endometrial carcinomas is regulated by usage of two different promoter regions. [20799950]
- Hereditary Spastic Paraplegia Overview [20301682]
- L1 Syndrome [20301657]
- Hirschsprung Disease Overview [20301612]
- Aberrant splicing of neural cell adhesion molecule L1 mRNA in a family with X-linked hydrocephalus. [1303258]
- Molecular cloning of cell adhesion molecule L1 from human nervous tissue: a comparison of the primary sequences of L1 molecules of different origin. [1932117]
- Molecular structure and functional testing of human L1CAM: an interspecies comparison. [1769655]
- The gene encoding L1, a neural adhesion molecule of the immunoglobulin family, is located on the X chromosome in mouse and man. [2387585]
UniProt Main References (47 PubMed Identifiers)
- Variants of human L1 cell adhesion molecule arise through alternate splicing of RNA. [1627459]
- Genomic organization of two novel genes on human Xq28: compact head to head arrangement of IDH gamma and TRAP delta is conserved in rat and mouse. [9286695]
- The neural cell adhesion molecule L1: genomic organisation and differential splicing is conserved between man and the pufferfish Fugu. [9479034]
- The DNA sequence of the human X chromosome. [15772651]
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
- A human brain glycoprotein related to the mouse cell adhesion molecule L1. [3136168]
- PCR walking from microdissection clone M54 identifies three exons from the human gene for the neural cell adhesion molecule L1 (CAM-L1). [1923824]
- Isolation and sequence of partial cDNA clones of human L1: homology of human and rodent L1 in the cytoplasmic region. [1993895]
- Casein kinase II phosphorylates the neural cell adhesion molecule L1. [8592152]
- Human plasma N-glycoproteome analysis by immunoaffinity subtraction, hydrazide chemistry, and mass spectrometry. [16335952] Show more
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_000425.5)
L1 cell adhesion molecule, transcript variant 1
m7G-5')ppp(5'-AGUCACUAACGUCCUUCCGUUCUCUCGUCUCUCUUCCCCCACCCUUCCCUUCCCUUCUCCCCUCUCCCAGUGCCCCCACUCCCAACUCCCGCCCCAAGCCGCCCACCAGCCCCCUUCCCCUCCGGCCGGAGCCUGAACCGAGCCCGGCUGGCUGUGCUGCGCGGUGCCGCCGGGAAAGAUGGUCGUGGCGCUGCGGUACGUGUGGCCUCUCCUCCUCUGCAGCCCCUGCCUGCUUAUCCAGAUCCCCGAGGAAUAUGAAGGACACCAUGUGAUGGAGCCACCUGUCAUCACGGAACAGUCUCCACGGCGCCUGGUUGUCUUCCCCACAGAUGACAUCAGCCUCAAGUGUGAGGCCAGUGGCAAGCCCGAAGUGCAGUUCCGCUGGACGAGGGAUGGUGUCCACUUCAAACCCAAGGAAGAGCUGGGUGUGACCGUGUACCAGUCGCCCCACUCUGGCUCCUUCACCAUCACGGGCAACAACAGCAACUUUGCUCAGAGGUUCCAGGGCAUCUACCGCUGCUUUGCCAGCAAUAAGCUGGGCACCGCCAUGUCCCAUGAGAUCCGGCUCAUGGCCGAGGGUGCCCCCAAGUGGCCAAAGGAGACAGUGAAGCCCGUGGAGGUGGAGGAAGGGGAGUCAGUGGUUCUGCCUUGCAACCCUCCCCCAAGUGCAGAGCCUCUCCGGAUCUACUGGAUGAACAGCAAGAUCUUGCACAUCAAGCAGGACGAGCGGGUGACGAUGGGCCAGAACGGCAACCUCUACUUUGCCAAUGUGCUCACCUCCGACAACCACUCAGACUACAUCUGCCACGCCCACUUCCCAGGCACCAGGACCAUCAUUCAGAAGGAACCCAUUGACCUCCGGGUCAAGGCCACCAACAGCAUGAUUGACAGGAAGCCGCGCCUGCUCUUCCCCACCAACUCCAGCAGCCACCUGGUGGCCUUGCAGGGGCAGCCAUUGGUCCUGGAGUGCAUCGCCGAGGGCUUUCCCACGCCCACCAUCAAAUGGCUGCGCCCCAGUGGCCCCAUGCCAGCCGACCGUGUCACCUACCAGAACCACAACAAGACCCUGCAGCUGCUGAAAGUGGGCGAGGAGGAUGAUGGCGAGUACCGCUGCCUGGCCGAGAACUCACUGGGCAGUGCCCGGCAUGCGUACUAUGUCACCGUGGAGGCUGCCCCGUACUGGCUGCACAAGCCCCAGAGCCAUCUAUAUGGGCCAGGAGAGACUGCCCGCCUGGACUGCCAAGUCCAGGGCAGGCCCCAACCAGAGGUCACCUGGAGAAUCAACGGGAUCCCUGUGGAGGAGCUGGCCAAAGACCAGAAGUACCGGAUUCAGCGUGGCGCCCUGAUCCUGAGCAACGUGCAGCCCAGUGACACAAUGGUGACCCAAUGUGAGGCCCGCAACCGGCACGGGCUCUUGCUGGCCAAUGCCUACAUCUACGUUGUCCAGCUGCCAGCCAAGAUCCUGACUGCGGACAAUCAGACGUACAUGGCUGUCCAGGGCAGCACUGCCUACCUUCUGUGCAAGGCCUUCGGAGCGCCUGUGCCCAGUGUUCAGUGGCUGGACGAGGAUGGGACAACAGUGCUUCAGGACGAACGCUUCUUCCCCUAUGCCAAUGGGACCCUGGGCAUUCGAGACCUCCAGGCCAAUGACACCGGACGCUACUUCUGCCUGGCUGCCAAUGACCAAAACAAUGUUACCAUCAUGGCUAACCUGAAGGUUAAAGAUGCAACUCAGAUCACUCAGGGGCCCCGCAGCACAAUCGAGAAGAAAGGUUCCAGGGUGACCUUCACGUGCCAGGCCUCCUUUGACCCCUCCUUGCAGCCCAGCAUCACCUGGCGUGGGGACGGUCGAGACCUCCAGGAGCUUGGGGACAGUGACAAGUACUUCAUAGAGGAUGGGCGCCUGGUCAUCCACAGCCUGGACUACAGCGACCAGGGCAACUACAGCUGCGUGGCCAGUACCGAACUGGAUGUGGUGGAGAGUAGGGCACAGCUCUUGGUGGUGGGGAGCCCUGGGCCGGUGCCACGGCUGGUGCUGUCCGACCUGCACCUGCUGACGCAGAGCCAGGUGCGCGUGUCCUGGAGUCCUGCAGAAGACCACAAUGCCCCCAUUGAGAAAUAUGACAUUGAAUUUGAGGACAAGGAAAUGGCGCCUGAAAAAUGGUACAGUCUGGGCAAGGUUCCAGGGAACCAGACCUCUACCACCCUCAAGCUGUCGCCCUAUGUCCACUACACCUUUAGGGUUACUGCCAUAAACAAAUAUGGCCCCGGGGAGCCCAGCCCGGUCUCUGAGACUGUGGUCACACCUGAGGCAGCCCCAGAGAAGAACCCUGUGGAUGUGAAGGGGGAAGGAAAUGAGACCACCAAUAUGGUCAUCACGUGGAAGCCGCUCCGGUGGAUGGACUGGAACGCCCCCCAGGUUCAGUACCGCGUGCAGUGGCGCCCUCAGGGGACACGAGGGCCCUGGCAGGAGCAGAUUGUCAGCGACCCCUUCCUGGUGGUGUCCAACACGUCCACCUUCGUGCCCUAUGAGAUCAAAGUCCAGGCCGUCAACAGCCAGGGCAAGGGACCAGAGCCCCAGGUCACUAUCGGCUACUCUGGAGAGGACUACCCCCAGGCAAUCCCUGAGCUGGAAGGCAUUGAAAUCCUCAACUCAAGUGCCGUGCUGGUCAAGUGGCGGCCGGUGGACCUGGCCCAGGUCAAGGGCCACCUCCGCGGAUACAAUGUGACGUACUGGAGGGAGGGCAGUCAGAGGAAGCACAGCAAGAGACAUAUCCACAAAGACCAUGUGGUGGUGCCCGCCAACACCACCAGUGUCAUCCUCAGUGGCUUGCGGCCCUAUAGCUCCUACCACCUGGAGGUGCAGGCCUUUAACGGGCGAGGAUCGGGGCCCGCCAGCGAGUUCACCUUCAGCACCCCAGAGGGAGUGCCUGGCCACCCCGAGGCGUUGCACCUGGAGUGCCAGUCGAACACCAGCCUGCUGCUGCGCUGGCAGCCCCCACUCAGCCACAACGGCGUGCUCACCGGCUACGUGCUCUCCUACCACCCCCUGGAUGAGGGGGGCAAGGGGCAACUGUCCUUCAACCUUCGGGACCCCGAACUUCGGACACACAACCUGACCGAUCUCAGCCCCCACCUGCGGUACCGCUUCCAGCUUCAGGCCACCACCAAAGAGGGCCCUGGUGAAGCCAUCGUACGGGAAGGAGGCACUAUGGCCUUGUCUGGGAUCUCAGAUUUUGGCAACAUCUCAGCCACAGCGGGUGAAAACUACAGUGUCGUCUCCUGGGUCCCCAAGGAGGGCCAGUGCAACUUCAGGUUCCAUAUCUUGUUCAAAGCCUUGGGAGAAGAGAAGGGUGGGGCUUCCCUUUCGCCACAGUAUGUCAGCUACAACCAGAGCUCCUACACGCAGUGGGACCUGCAGCCUGACACUGACUACGAGAUCCACUUGUUUAAGGAGAGGAUGUUCCGGCACCAAAUGGCUGUGAAGACCAAUGGCACAGGCCGCGUGAGGCUCCCUCCUGCUGGCUUCGCCACUGAGGGCUGGUUCAUCGGCUUUGUGAGUGCCAUCAUCCUCCUGCUCCUCGUCCUGCUCAUCCUCUGCUUCAUCAAGCGCAGCAAGGGCGGCAAAUACUCAGUGAAGGAUAAGGAGGACACCCAGGUGGACUCUGAGGCCCGACCGAUGAAAGAUGAGACCUUCGGCGAGUACAGGUCCCUGGAGAGUGACAACGAGGAGAAGGCCUUUGGCAGCAGCCAGCCAUCGCUCAACGGGGACAUCAAGCCCCUGGGCAGUGACGACAGCCUGGCCGAUUAUGGGGGCAGCGUGGAUGUUCAGUUCAACGAGGAUGGUUCGUUCAUUGGCCAGUACAGUGGCAAGAAGGAGAAGGAGGCGGCAGGGGGCAAUGACAGCUCAGGGGCCACUUCCCCCAUCAACCCUGCCGUGGCCCUAGAAUAGUGGAGUCCAGGACAGGAGAUGCUGUGCCCCUGGCCUUGGGAUCCAGGCCCCUCCCUCUCCAGCAGGCCCAUGGGAGGCUGGAGUUGGGGCAGAGGAGAACUUGCUGCCUCGGAUCCCCUUCCUACCACCCGGUCCCCACUUUAUUGCCAAAACCCAGCUGCACCCCUUCCUGGGCACACGCUGCUCUGCCCCAGCUUGGGCAGAUCUCCCACAUGCCAGGGGCCUUUGGGUGCUGUUUUGCCAGCCCAUUUGGGCAGAGAGGCUGUGGUUUGGGGGAGAAGAAGUAGGGGUGGCCCGAAAGGGUCUCCGAAAUGCUGUCUUUCUUGCUCCCUGACUGGGGGCAGACAUGGUGGGGUCUCCUCAGGACCAGGGUUGGCACCUUCCCCCUCCCCCAGCCACUCCCCAGCCAGCCUGGCUGGGACUGGGAACAGAACUCGGUGUCCCCACCAUCUGCUGUCUUUUCUUUGCCAUCUCUGCUCCAACCGGGAUGGGAGCCGGGCAAACUGGCCGCGGGGGCAGGGGAGGCCAUCUGGAGAGCCCAGAGUCCCCCCACUCCCAGCAUCGCACUCUGGCAGCACCGCCUCUUCCCGCCGCCCAGCCCACCCCAUGGCCGGCUUUCAGGAGCUCCAUACACACGCUGCCUUCGGUACCCACCACACAACAUCCAAGUGGCCUCCGUCACUACCUGGCUGCGGGGCGGGCACACCUCCUCCCACUGCCCACUGGCCGGCCUCUUCCAGCCGCCCCCACCCCCCAGGACCCCUUAGCAGCCCUGCCCUCCCUAUCGUCUGAACAGUUGUCUUCCUCAGCCUCCUCCCGCCCCCACCUUGGGAAUGUAAAUACACCGUGACUUUGAAAGUUUGUACCCCUGUCCUUCCCUUUACGCCACUAGUGUGUAGGCAGAUGUCUGAGUCCCUAGGUGGUUUCUAGGAUUGAUAGCAAUUAGCUUUGAUGAACCCAUCCCAGGAAAAAUAAAAACAGACAAAAAAAAAGGAAAGAUUGGUUCUCCCAGCACUGCUCAGCAGCCACAGCCUCCCUGUAUGCCUGUGCUUGGUCUACUGAUAAGCCCUCUACAAAAAAACAAAAGUAUAUAUAUAUAUGUACAUAAUAUCAGAAUUAUAACAGGCAAAUAAAACCUGAAAAUCAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 3897)
L1 cell adhesion molecule
strand -
CD171, NCAM-L1, CAML1
NCBI CDS gene sequence (3774 bp)
5'-ATGGTCGTGGCGCTGCGGTACGTGTGGCCTCTCCTCCTCTGCAGCCCCTGCCTGCTTATCCAGATCCCCGAGGAATATGAAGGACACCATGTGATGGAGCCACCTGTCATCACGGAACAGTCTCCACGGCGCCTGGTTGTCTTCCCCACAGATGACATCAGCCTCAAGTGTGAGGCCAGTGGCAAGCCCGAAGTGCAGTTCCGCTGGACGAGGGATGGTGTCCACTTCAAACCCAAGGAAGAGCTGGGTGTGACCGTGTACCAGTCGCCCCACTCTGGCTCCTTCACCATCACGGGCAACAACAGCAACTTTGCTCAGAGGTTCCAGGGCATCTACCGCTGCTTTGCCAGCAATAAGCTGGGCACCGCCATGTCCCATGAGATCCGGCTCATGGCCGAGGGTGCCCCCAAGTGGCCAAAGGAGACAGTGAAGCCCGTGGAGGTGGAGGAAGGGGAGTCAGTGGTTCTGCCTTGCAACCCTCCCCCAAGTGCAGAGCCTCTCCGGATCTACTGGATGAACAGCAAGATCTTGCACATCAAGCAGGACGAGCGGGTGACGATGGGCCAGAACGGCAACCTCTACTTTGCCAATGTGCTCACCTCCGACAACCACTCAGACTACATCTGCCACGCCCACTTCCCAGGCACCAGGACCATCATTCAGAAGGAACCCATTGACCTCCGGGTCAAGGCCACCAACAGCATGATTGACAGGAAGCCGCGCCTGCTCTTCCCCACCAACTCCAGCAGCCACCTGGTGGCCTTGCAGGGGCAGCCATTGGTCCTGGAGTGCATCGCCGAGGGCTTTCCCACGCCCACCATCAAATGGCTGCGCCCCAGTGGCCCCATGCCAGCCGACCGTGTCACCTACCAGAACCACAACAAGACCCTGCAGCTGCTGAAAGTGGGCGAGGAGGATGATGGCGAGTACCGCTGCCTGGCCGAGAACTCACTGGGCAGTGCCCGGCATGCGTACTATGTCACCGTGGAGGCTGCCCCGTACTGGCTGCACAAGCCCCAGAGCCATCTATATGGGCCAGGAGAGACTGCCCGCCTGGACTGCCAAGTCCAGGGCAGGCCCCAACCAGAGGTCACCTGGAGAATCAACGGGATCCCTGTGGAGGAGCTGGCCAAAGACCAGAAGTACCGGATTCAGCGTGGCGCCCTGATCCTGAGCAACGTGCAGCCCAGTGACACAATGGTGACCCAATGTGAGGCCCGCAACCGGCACGGGCTCTTGCTGGCCAATGCCTACATCTACGTTGTCCAGCTGCCAGCCAAGATCCTGACTGCGGACAATCAGACGTACATGGCTGTCCAGGGCAGCACTGCCTACCTTCTGTGCAAGGCCTTCGGAGCGCCTGTGCCCAGTGTTCAGTGGCTGGACGAGGATGGGACAACAGTGCTTCAGGACGAACGCTTCTTCCCCTATGCCAATGGGACCCTGGGCATTCGAGACCTCCAGGCCAATGACACCGGACGCTACTTCTGCCTGGCTGCCAATGACCAAAACAATGTTACCATCATGGCTAACCTGAAGGTTAAAGATGCAACTCAGATCACTCAGGGGCCCCGCAGCACAATCGAGAAGAAAGGTTCCAGGGTGACCTTCACGTGCCAGGCCTCCTTTGACCCCTCCTTGCAGCCCAGCATCACCTGGCGTGGGGACGGTCGAGACCTCCAGGAGCTTGGGGACAGTGACAAGTACTTCATAGAGGATGGGCGCCTGGTCATCCACAGCCTGGACTACAGCGACCAGGGCAACTACAGCTGCGTGGCCAGTACCGAACTGGATGTGGTGGAGAGTAGGGCACAGCTCTTGGTGGTGGGGAGCCCTGGGCCGGTGCCACGGCTGGTGCTGTCCGACCTGCACCTGCTGACGCAGAGCCAGGTGCGCGTGTCCTGGAGTCCTGCAGAAGACCACAATGCCCCCATTGAGAAATATGACATTGAATTTGAGGACAAGGAAATGGCGCCTGAAAAATGGTACAGTCTGGGCAAGGTTCCAGGGAACCAGACCTCTACCACCCTCAAGCTGTCGCCCTATGTCCACTACACCTTTAGGGTTACTGCCATAAACAAATATGGCCCCGGGGAGCCCAGCCCGGTCTCTGAGACTGTGGTCACACCTGAGGCAGCCCCAGAGAAGAACCCTGTGGATGTGAAGGGGGAAGGAAATGAGACCACCAATATGGTCATCACGTGGAAGCCGCTCCGGTGGATGGACTGGAACGCCCCCCAGGTTCAGTACCGCGTGCAGTGGCGCCCTCAGGGGACACGAGGGCCCTGGCAGGAGCAGATTGTCAGCGACCCCTTCCTGGTGGTGTCCAACACGTCCACCTTCGTGCCCTATGAGATCAAAGTCCAGGCCGTCAACAGCCAGGGCAAGGGACCAGAGCCCCAGGTCACTATCGGCTACTCTGGAGAGGACTACCCCCAGGCAATCCCTGAGCTGGAAGGCATTGAAATCCTCAACTCAAGTGCCGTGCTGGTCAAGTGGCGGCCGGTGGACCTGGCCCAGGTCAAGGGCCACCTCCGCGGATACAATGTGACGTACTGGAGGGAGGGCAGTCAGAGGAAGCACAGCAAGAGACATATCCACAAAGACCATGTGGTGGTGCCCGCCAACACCACCAGTGTCATCCTCAGTGGCTTGCGGCCCTATAGCTCCTACCACCTGGAGGTGCAGGCCTTTAACGGGCGAGGATCGGGGCCCGCCAGCGAGTTCACCTTCAGCACCCCAGAGGGAGTGCCTGGCCACCCCGAGGCGTTGCACCTGGAGTGCCAGTCGAACACCAGCCTGCTGCTGCGCTGGCAGCCCCCACTCAGCCACAACGGCGTGCTCACCGGCTACGTGCTCTCCTACCACCCCCTGGATGAGGGGGGCAAGGGGCAACTGTCCTTCAACCTTCGGGACCCCGAACTTCGGACACACAACCTGACCGATCTCAGCCCCCACCTGCGGTACCGCTTCCAGCTTCAGGCCACCACCAAAGAGGGCCCTGGTGAAGCCATCGTACGGGAAGGAGGCACTATGGCCTTGTCTGGGATCTCAGATTTTGGCAACATCTCAGCCACAGCGGGTGAAAACTACAGTGTCGTCTCCTGGGTCCCCAAGGAGGGCCAGTGCAACTTCAGGTTCCATATCTTGTTCAAAGCCTTGGGAGAAGAGAAGGGTGGGGCTTCCCTTTCGCCACAGTATGTCAGCTACAACCAGAGCTCCTACACGCAGTGGGACCTGCAGCCTGACACTGACTACGAGATCCACTTGTTTAAGGAGAGGATGTTCCGGCACCAAATGGCTGTGAAGACCAATGGCACAGGCCGCGTGAGGCTCCCTCCTGCTGGCTTCGCCACTGAGGGCTGGTTCATCGGCTTTGTGAGTGCCATCATCCTCCTGCTCCTCGTCCTGCTCATCCTCTGCTTCATCAAGCGCAGCAAGGGCGGCAAATACTCAGTGAAGGATAAGGAGGACACCCAGGTGGACTCTGAGGCCCGACCGATGAAAGATGAGACCTTCGGCGAGTACAGGTCCCTGGAGAGTGACAACGAGGAGAAGGCCTTTGGCAGCAGCCAGCCATCGCTCAACGGGGACATCAAGCCCCTGGGCAGTGACGACAGCCTGGCCGATTATGGGGGCAGCGTGGATGTTCAGTTCAACGAGGATGGTTCGTTCATTGGCCAGTACAGTGGCAAGAAGGAGAAGGAGGCGGCAGGGGGCAATGACAGCTCAGGGGCCACTTCCCCCATCAACCCTGCCGTGGCCCTAGAATAG-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.