Protein
Protein (XP_005270723)
Adhesion G protein-coupled receptor L2
Adhesion G protein-coupled receptor L2 (Calcium-independent alpha-latrotoxin receptor 2) (CIRL-2) (Latrophilin homolog 1) (Latrophilin-2) (Lectomedin-1)
ADGRL2
adhesion G protein-coupled receptor L2
Undefined
Very low evidence
L-rhamnose binding lectin
Undefined
b-sandwich / CUB-like
MVSSGCRMRSLWFIIVISFLPNTEGFSRAALPFGLVRRELSCEGYSIDLRCPGSDVIMIESANYGRTDDKICDADPFQMENTDCYLPDAFKIMTQRCNNRTQCIVVTGSDVFPDPCPGTYKYLEVQYECVPYIFVCPGTLKAIVDSPCIYEAEQKAGAWCKDPLQAADKIYFMPWTPYRTDTLIEYASLEDFQNSRQTTTYKLPNRVDGTGFVVYDGAVFFNKERTRNIVKFDLRTRIKSGEAIINYANYHDTSPYRWGGKTDIDLAVDENGLWVIYATEQNNGMIVISQLNPYTLRFEATWETVYDKRAASNAFMICGVLYVVRSVYQDNESETGKNSIDYIYNTRLNRGEYVDVPFPNQYQYIAAVDYNPRDNQLYVWNNNFILRYSLEFGPPDPAQVPTTAVTITSSAELFKTIISTTSTTSQKGPMSTTVAGSQEGSKGTKPPPAVSTTKIPPITNIFPLPERFCEALDSKGIKWPQTQRGMMVERPCPKGTRGTASYLCMISTGTWNPKGPDLSNCTSHWVNQLAQKIRSGENAASLANELAKHTKGPVFAGDVSSSVRLMEQLVDILDAQLQELKPSEKDSAGRSYNKLQKREKTCRAYLKAIVDTVDNLLRPEALESWKHMNSSEQAHTATMLLDTLEEGAFVLADNLLEPTRVSMPTENIVLEVAVLSTEGQIQDFKFPLGIKGAGSSIQLSANTVKQNSRNGLAKLVFIIYRSLGQFLSTENATIKLGADFIGRNSTIAVNSHVISVSINKESSRVYLTDPVLFTLPHIDPDNYFNANCSFWNYSERTMMGYWSTQGCKLVDTNKTRTTCACSHLTNFAILMAHREIAYKDGVHELLLTVITWVGIVISLVCLAICIFTFCFFRGLQSDRNTIHKNLCINLFIAEFIFLIGIDKTKYAIACPIFAGLLHFFFLAAFAWMCLEGVQLYLMLVEVFESEYSRKKYYYVAGYLFPATVVGVSAAIDYKSYGTEKACWLHVDNYFIWSFIGPVTFIILLNIIFLVITLCKMVKHSNTLKPDSSRLENIKSWVLGAFALLCLLGLTWSFGLLFINEETIVMAYLFTIFNAFQGVFIFIFHCALQKKVRKEYGKCFRHSYCCGGLPTESPHSSVKASTTRTSARYSSGTQSRIRRMWNDTVRKQSESSFISGDINSTSTLNQGMTGNYLLTNPLLRPHGTNNPYNTLLAETVVCNAPSAPVFNSPGHSLNNARDTSAMDTLPLNGNFNNSYSLHKGDYNDSVQVVDCGLSLNDTAFEKMIISELVHNNLRGSSKTHNLELTLPVKPVIGGSSSEDDAIVADASSLMHSDNPGLELHHKELEAPLIPQRTHSLLYQPQKKVKSEGTDSYVSQLTAEAEDHLQSPNRDSLYTSMPNLRDSPYPESSPDMEEDLSPSRRSENEDIYYKSMPNLGAGHQLQMCYQISRGNSDGYIIPINKEGCIPEGDVREGQMQLVTSL
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
The location of the lectin domain structural model is: 40-132
We infer [0.47, 0.87] Å as the interval of error of this structural model.
Template: 2JX9 chain: A, Q80TR1, NP_851382.2, sequence identity: 87.1%, coverage: 100.0%, location in sequence: 29-134, (29-134 in PDB).
Show the alignment used for the construction of the structural model, Download.
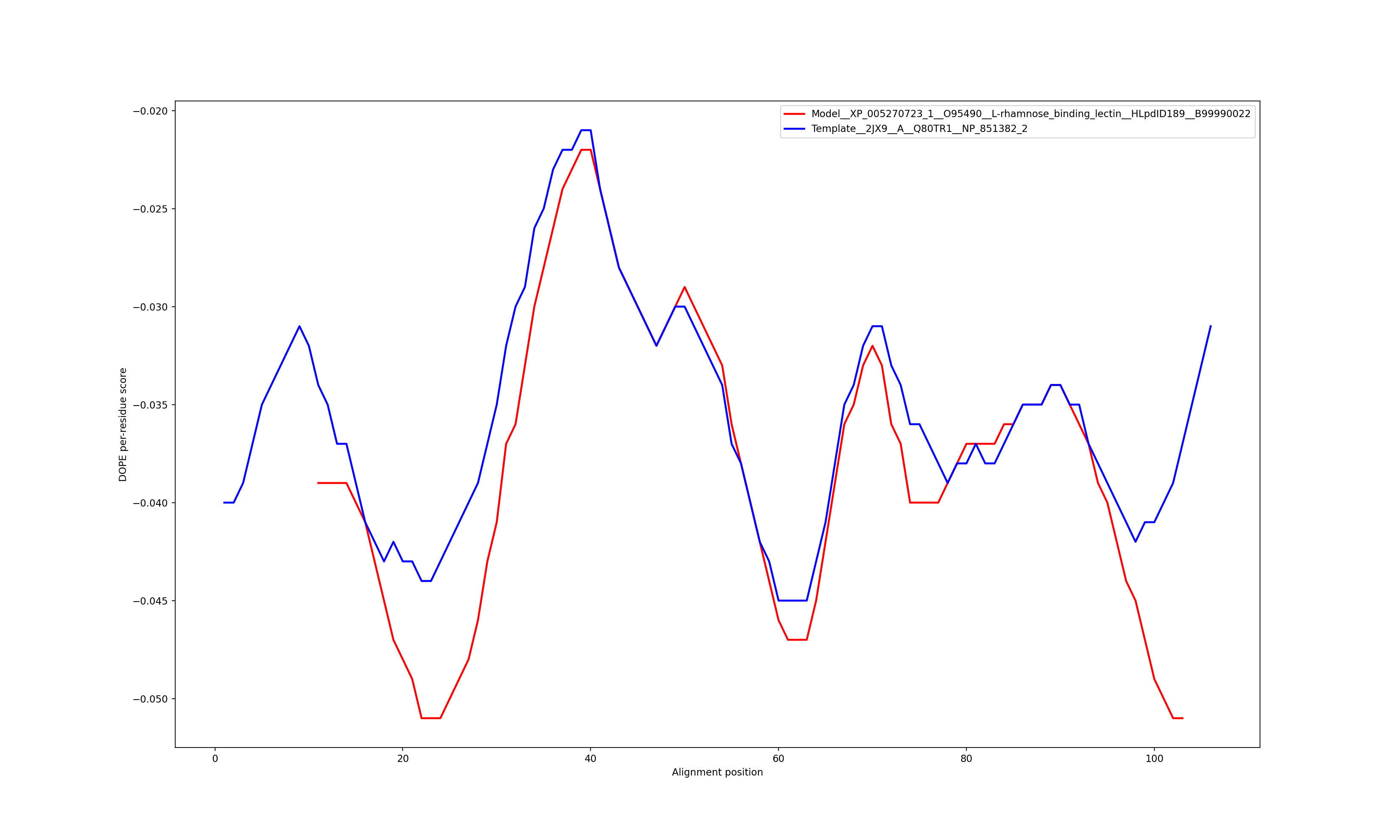
Show the plot of DOPE energy score, Download.
We infer [0.47, 0.87] Å as the interval of error of this structural model.
Template: 2JX9 chain: A, Q80TR1, NP_851382.2, sequence identity: 87.1%, coverage: 100.0%, location in sequence: 29-134, (29-134 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
Heterodimer of 2 chains generated by proteolytic processing; the large extracellular N-terminal fragment and the membrane-bound C-terminal fragment predominantly remain associated and non-covalently linked
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
UniProt Main References (11 PubMed Identifiers)
- Isolation and characterization of a human homologue of the latrophilin gene from a region of 1p31.1 implicated in breast cancer. [10030676]
- Genomic structure and expression profile of LPHH1, a 7TM gene variably expressed in breast cancer cell lines. [10760572]
- The DNA sequence and biological annotation of human chromosome 1. [16710414]
- Prediction of the coding sequences of unidentified human genes. XI. The complete sequences of 100 new cDNA clones from brain which code for large proteins in vitro. [9872452]
- Discovery of tissue-specific exons using comprehensive human exon microarrays. [17456239]
- Glycoproteomics analysis of human liver tissue by combination of multiple enzyme digestion and hydrazide chemistry. [19159218]
- Initial characterization of the human central proteome. [21269460]
- System-wide temporal characterization of the proteome and phosphoproteome of human embryonic stem cell differentiation. [21406692]
- An enzyme assisted RP-RPLC approach for in-depth analysis of human liver phosphoproteome. [24275569]
- Exome sequencing reveals new causal mutations in children with epileptic encephalopathies. [23647072] Show more
All isoforms of this gene containing a lectin domain
XP_006710548.1, XP_006710551.1, XP_006710552.1, XP_016856273.1, NP_001284635.1, NP_001337628.1, NP_001380283.1, XP_024310127.1, NP_001380282.1, XP_016856286.1, NP_001352938.1, NP_001284634.1, NP_001352937.1, XP_024310125.1, XP_024310126.1, NP_001352936.1, NP_001284633.1, NP_001352931.1, NP_001380280.1, NP_001380281.1, NP_036434.1, NP_001317574.1, NP_001380279.1, XP_024310123.1, XP_005270725.1, XP_016856278.1, XP_005270723.1, NP_001337627.1, NP_001352932.1, NP_001352933.1, NP_001380278.1, XP_016856275.1, XP_024310118.1, NP_001352934.1, NP_001352935.1
RNA
RNA (Transcript ID: XM_005270666.4)
adhesion G protein-coupled receptor L2, transcript variant X7
m7G-5')ppp(5'-AGGACUUCGCAUUCCCCCGUCUCUCUCUCUCUCCCUCUCGCUCCCUCUCACUCUCUCUCCGCUCACACACACGCAGAGGUGCUGGGGCGAAAUCGGGAGCUUACCAGAGAAUUCCUUGGGAUUGUUGGGGGGCAUCUCCCCUCCGCUGCUGUGUGUGGCGUGGCUCUUCCCGGCUACUCCUUGCUUCCCCGAGCCCGAGUCUGCGCCGCCAGCCUUCCUUGGGGCAGCGGCCACCGCUCAGCCCCGGCCGGGAGAUCCGAAAUGUGAGGAGGGGUCGCCGCCGCCUCCCGCCCCAGGCCGCAGGGUCGGCGCGAGGGAUGCUAUUCCGGCCGGGCGCUCGGGGGGCUGAGGGGCUUCGCCUGACAAACUGAGUUGGCCUCGCGCCCCCGGCGCCCUCCCGCCCGUCGCUUCGAAGGGACUCCCAAGUCUGCGCACCUCUGUCAGGCUUUUGCUUCCACCACCCCUUUCGCUCUGAUUCCCGAUUUUUUUUUCCUAAGGGAGCGUGCGGUCUGGGGGUGUGUGCGUGUGUGUGAAAGACCUCUCUCGAAGAGCGGCGUGUGGGAAACUGCGGGAAAAUGUUGACUUAACCCCAGGAGCCGCCCGGCGCUGGCUGCUCGGCUGGAGGCGGCGGCGGCCGAGCAGGAGGACGCGCCGAGCUGCGGCGCCGUGUCCGGCCGGGGAGCUGCGGCGCUGCCUCCCGCGCGGACUCGGCGGCCGAGGACCCGCUCGCGGCCGGCCUCGGCCCUCUCCGGCCGGGGUAGCCGCUGCCCUCCGCGCCUGUCCCCGCGCGGCCCCCACGCCAGACGGCCCUCCCUCGGGGCGCGCUCGCAGACGGAGAUAUGAAGAUCAAUGAUGCAGACUGAUGGUUUUGAUGAAGCUGGGCAUUUAUAACUAGAUUCAUUAAGGAAUACAAAGAAAAUACUUAAAGGGAUCAAUAAUGGUGUCUUCUGGUUGCAGAAUGCGAAGUCUGUGGUUUAUCAUUGUAAUCAGCUUCUUACCAAAUACAGAAGGUUUCAGCAGAGCAGCUUUACCAUUUGGGCUGGUGAGGCGAGAAUUAUCCUGUGAAGGUUAUUCUAUAGAUCUGCGAUGCCCGGGCAGUGAUGUCAUCAUGAUUGAGAGCGCUAACUAUGGUCGGACGGAUGACAAGAUUUGUGAUGCUGACCCAUUUCAGAUGGAGAAUACAGACUGCUACCUCCCCGAUGCCUUCAAAAUUAUGACUCAAAGGUGCAACAAUCGAACACAGUGUAUAGUAGUUACUGGGUCAGAUGUGUUUCCUGAUCCAUGUCCUGGAACAUACAAAUACCUUGAAGUCCAAUAUGAAUGUGUCCCUUACAUUUUUGUGUGUCCUGGGACCUUGAAAGCAAUUGUGGACUCACCAUGUAUAUAUGAAGCUGAACAAAAGGCGGGUGCUUGGUGCAAGGACCCUCUUCAGGCUGCAGAUAAAAUUUAUUUCAUGCCCUGGACUCCCUAUCGUACCGAUACUUUAAUAGAAUAUGCUUCUUUAGAAGAUUUCCAAAAUAGUCGCCAAACAACAACAUAUAAACUUCCAAAUCGAGUAGAUGGUACUGGAUUUGUGGUGUAUGAUGGUGCUGUCUUCUUUAACAAAGAAAGAACGAGGAAUAUUGUGAAAUUUGACUUGAGGACUAGAAUUAAGAGUGGCGAGGCCAUAAUUAACUAUGCCAACUACCAUGAUACCUCACCAUACAGAUGGGGAGGAAAGACUGAUAUCGACCUAGCAGUUGAUGAAAAUGGUUUAUGGGUCAUUUACGCCACUGAACAGAACAAUGGAAUGAUAGUUAUUAGCCAGCUGAAUCCAUACACUCUUCGAUUUGAAGCAACGUGGGAGACUGUAUACGACAAACGUGCCGCAUCAAAUGCUUUUAUGAUAUGCGGAGUCCUCUAUGUGGUUAGGUCAGUUUAUCAAGACAAUGAAAGUGAAACAGGCAAGAACUCAAUUGAUUACAUUUAUAAUACCCGAUUAAACCGAGGAGAAUAUGUAGAUGUUCCCUUCCCCAACCAGUAUCAGUAUAUUGCUGCAGUGGAUUACAAUCCAAGAGAUAACCAACUUUACGUGUGGAACAAUAACUUCAUUUUACGAUAUUCUCUGGAGUUUGGUCCACCUGAUCCUGCCCAAGUGCCUACCACAGCUGUGACAAUAACUUCUUCAGCUGAGCUGUUCAAAACCAUAAUAUCAACCACAAGCACUACUUCACAGAAAGGCCCCAUGAGCACAACUGUAGCUGGAUCACAGGAAGGAAGCAAAGGGACAAAACCACCUCCAGCAGUUUCUACAACCAAAAUUCCACCUAUAACAAAUAUUUUUCCCCUGCCAGAGAGAUUCUGUGAAGCAUUAGACUCCAAGGGGAUAAAGUGGCCUCAGACACAAAGGGGAAUGAUGGUUGAACGACCAUGCCCUAAGGGAACAAGAGGAACUGCCUCAUAUCUCUGCAUGAUUUCCACUGGAACAUGGAACCCUAAGGGCCCCGAUCUUAGCAACUGUACCUCACACUGGGUGAAUCAGCUGGCUCAGAAGAUCAGAAGCGGAGAAAAUGCUGCUAGUCUUGCCAAUGAACUGGCUAAACAUACCAAAGGGCCAGUGUUUGCUGGGGAUGUAAGUUCUUCAGUGAGAUUGAUGGAGCAGUUGGUGGACAUCCUUGAUGCACAGCUGCAGGAACUGAAACCUAGUGAAAAAGAUUCAGCUGGACGGAGUUAUAACAAGCUCCAAAAACGAGAGAAGACAUGCAGGGCUUACCUUAAGGCAAUUGUUGACACAGUGGACAACCUUCUGAGACCCGAAGCUUUGGAAUCAUGGAAACAUAUGAAUUCUUCUGAACAAGCACAUACUGCAACAAUGUUACUCGAUACAUUGGAAGAAGGAGCUUUUGUCCUAGCUGACAAUCUUUUAGAACCAACAAGGGUCUCAAUGCCCACAGAAAAUAUUGUCCUGGAAGUUGCCGUACUCAGUACAGAAGGACAGAUCCAAGACUUUAAAUUUCCUCUGGGCAUCAAAGGAGCAGGCAGCUCAAUCCAACUGUCCGCAAAUACCGUCAAACAGAACAGCAGGAAUGGGCUUGCAAAGUUGGUGUUCAUCAUUUACCGGAGCCUGGGACAGUUCCUUAGUACAGAAAAUGCAACCAUUAAACUGGGUGCUGAUUUUAUUGGUCGUAAUAGCACCAUUGCAGUGAACUCUCACGUCAUUUCAGUUUCAAUCAAUAAAGAGUCCAGCCGAGUAUACCUGACUGAUCCUGUGCUUUUUACCCUGCCACACAUUGAUCCUGACAAUUAUUUCAAUGCAAACUGCUCCUUCUGGAACUACUCAGAGAGAACUAUGAUGGGAUAUUGGUCUACCCAGGGCUGCAAGCUGGUUGACACUAAUAAAACUCGAACAACGUGUGCAUGCAGCCACCUAACCAAUUUUGCAAUUCUCAUGGCCCACAGGGAAAUUGCAUAUAAAGAUGGCGUUCAUGAAUUACUUCUUACAGUCAUCACCUGGGUGGGAAUUGUCAUUUCCCUUGUUUGCCUGGCUAUCUGCAUCUUCACCUUCUGCUUUUUCCGUGGCCUACAGAGUGACCGAAAUACUAUUCACAAGAACCUUUGUAUCAACCUUUUCAUUGCUGAAUUUAUUUUCCUAAUAGGCAUUGAUAAGACAAAAUAUGCGAUUGCAUGCCCAAUAUUUGCAGGACUUCUACACUUUUUCUUUUUGGCAGCUUUUGCUUGGAUGUGCCUAGAAGGUGUGCAGCUCUACCUAAUGUUAGUUGAAGUUUUUGAAAGUGAAUAUUCAAGGAAAAAAUAUUACUAUGUUGCUGGUUACUUGUUUCCUGCCACAGUGGUUGGAGUUUCAGCUGCUAUUGACUAUAAGAGCUAUGGAACAGAAAAAGCUUGCUGGCUUCAUGUUGAUAACUACUUUAUAUGGAGCUUCAUUGGACCUGUUACCUUCAUUAUUCUGCUAAAUAUUAUCUUCUUGGUGAUCACAUUGUGCAAAAUGGUGAAGCAUUCAAACACUUUGAAACCAGAUUCUAGCAGGUUGGAAAACAUUAAGUCUUGGGUGCUUGGCGCUUUCGCUCUUCUGUGUCUUCUUGGCCUCACCUGGUCCUUUGGGUUGCUUUUUAUUAAUGAGGAGACUAUUGUGAUGGCAUAUCUCUUCACUAUAUUUAAUGCUUUCCAGGGAGUGUUCAUUUUCAUCUUUCACUGUGCUCUCCAAAAGAAAGUACGAAAAGAAUAUGGCAAGUGCUUCAGACACUCAUACUGCUGUGGAGGCCUCCCAACUGAGAGUCCCCACAGUUCAGUGAAGGCAUCAACCACCAGAACCAGUGCUCGCUAUUCCUCUGGCACACAGAGUCGUAUAAGAAGAAUGUGGAAUGAUACUGUGAGAAAACAAUCAGAAUCUUCUUUUAUCUCAGGUGACAUCAAUAGCACUUCAACACUUAAUCAAGGAAUGACUGGCAAUUACCUACUAACAAACCCUCUUCUUCGACCCCACGGCACUAACAACCCCUAUAACACAUUGCUCGCUGAAACAGUUGUAUGUAAUGCCCCUUCAGCUCCUGUAUUUAACUCACCAGGACAUUCACUGAACAAUGCCAGGGAUACAAGUGCCAUGGAUACUCUACCGCUAAAUGGUAAUUUUAACAACAGCUACUCGCUGCACAAGGGUGACUAUAAUGACAGCGUGCAAGUUGUGGACUGUGGACUAAGUCUGAAUGAUACUGCUUUUGAGAAAAUGAUCAUUUCAGAAUUAGUGCACAACAACUUACGGGGCAGCAGCAAGACUCACAACCUCGAGCUCACGCUACCAGUCAAACCUGUGAUUGGAGGUAGCAGCAGUGAAGAUGAUGCUAUUGUGGCAGAUGCUUCAUCUUUAAUGCACAGCGACAACCCAGGGCUGGAGCUCCAUCACAAAGAACUCGAGGCACCACUUAUUCCUCAGCGGACUCACUCCCUUCUGUACCAACCCCAGAAGAAAGUGAAGUCCGAGGGAACUGACAGCUAUGUCUCCCAACUGACAGCAGAGGCUGAAGAUCACCUACAGUCCCCCAACAGAGACUCUCUUUAUACAAGCAUGCCCAAUCUUAGAGACUCUCCCUAUCCGGAGAGCAGCCCUGACAUGGAAGAAGACCUCUCUCCCUCCAGGAGGAGUGAGAAUGAGGACAUUUACUAUAAAAGCAUGCCAAAUCUUGGAGCUGGCCAUCAGCUUCAGAUGUGCUACCAGAUCAGCAGGGGCAAUAGUGAUGGUUAUAUAAUCCCCAUUAACAAAGAAGGGUGUAUUCCAGAAGGAGAUGUUAGAGAAGGACAAAUGCAGCUGGUUACAAGUCUUUAAUCAUACAGCUAAGGAAUUCCAAGGGCCACAUGCGAGUAUUAAUAAAUAAAGACACCAUUGGCCUGACGCAGCUCCCUCAAACUCUGCUUGAAGAGAUGACUCUUGACCUGUGGUUCUCUGGUGUAAAAAAGAUGACUGAACCUUGCAGUUCUGUGAAUUUUUAUAAAACAUACAAAAACUUUGUAUAUACACAGAGUAUACUAAAGUGAAUUAUUUGUUACAAAGAAAAGAGAUGCCAGCCAGGUAUUUUAAGAUUCUGCUGCUGUUUAGAGAAAUUGUGAAACAAGCAAAACAAAACUUUCCAGCCAUUUUACUGCAGCAGUCUGUGAACUAAAUUUGUAAAUAUGGCUGCACCAUUUUUGUAGGCCUGCAUUGUAUUAUAUACAAGACGUAGGCUUUAAAAUCCUGUGGGACAAAUUUACUGUACCUUACUAUUCCUGACAAGACUUGGAAAAGCAGGAGAGAUAUUCUGCAUCAGUUUGCAGUUCACUGCAAAUCUUUUACAUUAAGGCAAAGAUUGAAAACAUGCUUAACCACUAGCAAUCAAGCCACAGGCCUUAUUUCAUAUGUUUCCUCAACUGUACAAUGAACUAUUCUCAUGAAAAAUGGCUAAAGAAAUUAUAUUUUGUUCUAUUGCUAGGGUAAAAUAAAUACAUUUGUGUCCAACUGAAAUAUAAUUGUCAUUAAAAUAAUUUUAAAGAGUGAAGAAAAUAUUGUGAAAAGCUCUUGGUUGCACAUGUUAUGAAAUGUUUUUUCUUACACUUUGUCAUGGUAAGUUCUACUCAUUUUCACUUCUUUUCCACUGUAUACAGUGUUCUGCUUUGACAAAGUUGGUCUUUAUUACUUACAUUUAAAUUUCUUAUUGCCAAAAGAACGUGUUUUAUGGGGAGAAACAAACUCUUUGAAGCCAGUUAUGUCAUGCCUUGCACAAAAGUGAUGAAAUCUAGAAAAGAUUGUGUGUCACCCCUGUUUAUUCUUGAACAGAGGGCAAAGAGGGCACUGGGCACUUCUCACAAACUUUCUAGUGAACAAAAGGUGCCUAUUCUUUUUUAAAAAAAUAAAAUAAAACAUAAAUAUUACUCUUCCAUAUUCCUUCUGCCUAUAUU-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 23266)
adhesion G protein-coupled receptor L2
strand +
KIAA0786, LEC1, CIRL2
NCBI CDS gene sequence (4380 bp)
5'-ATGGTGTCTTCTGGTTGCAGAATGCGAAGTCTGTGGTTTATCATTGTAATCAGCTTCTTACCAAATACAGAAGGTTTCAGCAGAGCAGCTTTACCATTTGGGCTGGTGAGGCGAGAATTATCCTGTGAAGGTTATTCTATAGATCTGCGATGCCCGGGCAGTGATGTCATCATGATTGAGAGCGCTAACTATGGTCGGACGGATGACAAGATTTGTGATGCTGACCCATTTCAGATGGAGAATACAGACTGCTACCTCCCCGATGCCTTCAAAATTATGACTCAAAGGTGCAACAATCGAACACAGTGTATAGTAGTTACTGGGTCAGATGTGTTTCCTGATCCATGTCCTGGAACATACAAATACCTTGAAGTCCAATATGAATGTGTCCCTTACATTTTTGTGTGTCCTGGGACCTTGAAAGCAATTGTGGACTCACCATGTATATATGAAGCTGAACAAAAGGCGGGTGCTTGGTGCAAGGACCCTCTTCAGGCTGCAGATAAAATTTATTTCATGCCCTGGACTCCCTATCGTACCGATACTTTAATAGAATATGCTTCTTTAGAAGATTTCCAAAATAGTCGCCAAACAACAACATATAAACTTCCAAATCGAGTAGATGGTACTGGATTTGTGGTGTATGATGGTGCTGTCTTCTTTAACAAAGAAAGAACGAGGAATATTGTGAAATTTGACTTGAGGACTAGAATTAAGAGTGGCGAGGCCATAATTAACTATGCCAACTACCATGATACCTCACCATACAGATGGGGAGGAAAGACTGATATCGACCTAGCAGTTGATGAAAATGGTTTATGGGTCATTTACGCCACTGAACAGAACAATGGAATGATAGTTATTAGCCAGCTGAATCCATACACTCTTCGATTTGAAGCAACGTGGGAGACTGTATACGACAAACGTGCCGCATCAAATGCTTTTATGATATGCGGAGTCCTCTATGTGGTTAGGTCAGTTTATCAAGACAATGAAAGTGAAACAGGCAAGAACTCAATTGATTACATTTATAATACCCGATTAAACCGAGGAGAATATGTAGATGTTCCCTTCCCCAACCAGTATCAGTATATTGCTGCAGTGGATTACAATCCAAGAGATAACCAACTTTACGTGTGGAACAATAACTTCATTTTACGATATTCTCTGGAGTTTGGTCCACCTGATCCTGCCCAAGTGCCTACCACAGCTGTGACAATAACTTCTTCAGCTGAGCTGTTCAAAACCATAATATCAACCACAAGCACTACTTCACAGAAAGGCCCCATGAGCACAACTGTAGCTGGATCACAGGAAGGAAGCAAAGGGACAAAACCACCTCCAGCAGTTTCTACAACCAAAATTCCACCTATAACAAATATTTTTCCCCTGCCAGAGAGATTCTGTGAAGCATTAGACTCCAAGGGGATAAAGTGGCCTCAGACACAAAGGGGAATGATGGTTGAACGACCATGCCCTAAGGGAACAAGAGGAACTGCCTCATATCTCTGCATGATTTCCACTGGAACATGGAACCCTAAGGGCCCCGATCTTAGCAACTGTACCTCACACTGGGTGAATCAGCTGGCTCAGAAGATCAGAAGCGGAGAAAATGCTGCTAGTCTTGCCAATGAACTGGCTAAACATACCAAAGGGCCAGTGTTTGCTGGGGATGTAAGTTCTTCAGTGAGATTGATGGAGCAGTTGGTGGACATCCTTGATGCACAGCTGCAGGAACTGAAACCTAGTGAAAAAGATTCAGCTGGACGGAGTTATAACAAGCTCCAAAAACGAGAGAAGACATGCAGGGCTTACCTTAAGGCAATTGTTGACACAGTGGACAACCTTCTGAGACCCGAAGCTTTGGAATCATGGAAACATATGAATTCTTCTGAACAAGCACATACTGCAACAATGTTACTCGATACATTGGAAGAAGGAGCTTTTGTCCTAGCTGACAATCTTTTAGAACCAACAAGGGTCTCAATGCCCACAGAAAATATTGTCCTGGAAGTTGCCGTACTCAGTACAGAAGGACAGATCCAAGACTTTAAATTTCCTCTGGGCATCAAAGGAGCAGGCAGCTCAATCCAACTGTCCGCAAATACCGTCAAACAGAACAGCAGGAATGGGCTTGCAAAGTTGGTGTTCATCATTTACCGGAGCCTGGGACAGTTCCTTAGTACAGAAAATGCAACCATTAAACTGGGTGCTGATTTTATTGGTCGTAATAGCACCATTGCAGTGAACTCTCACGTCATTTCAGTTTCAATCAATAAAGAGTCCAGCCGAGTATACCTGACTGATCCTGTGCTTTTTACCCTGCCACACATTGATCCTGACAATTATTTCAATGCAAACTGCTCCTTCTGGAACTACTCAGAGAGAACTATGATGGGATATTGGTCTACCCAGGGCTGCAAGCTGGTTGACACTAATAAAACTCGAACAACGTGTGCATGCAGCCACCTAACCAATTTTGCAATTCTCATGGCCCACAGGGAAATTGCATATAAAGATGGCGTTCATGAATTACTTCTTACAGTCATCACCTGGGTGGGAATTGTCATTTCCCTTGTTTGCCTGGCTATCTGCATCTTCACCTTCTGCTTTTTCCGTGGCCTACAGAGTGACCGAAATACTATTCACAAGAACCTTTGTATCAACCTTTTCATTGCTGAATTTATTTTCCTAATAGGCATTGATAAGACAAAATATGCGATTGCATGCCCAATATTTGCAGGACTTCTACACTTTTTCTTTTTGGCAGCTTTTGCTTGGATGTGCCTAGAAGGTGTGCAGCTCTACCTAATGTTAGTTGAAGTTTTTGAAAGTGAATATTCAAGGAAAAAATATTACTATGTTGCTGGTTACTTGTTTCCTGCCACAGTGGTTGGAGTTTCAGCTGCTATTGACTATAAGAGCTATGGAACAGAAAAAGCTTGCTGGCTTCATGTTGATAACTACTTTATATGGAGCTTCATTGGACCTGTTACCTTCATTATTCTGCTAAATATTATCTTCTTGGTGATCACATTGTGCAAAATGGTGAAGCATTCAAACACTTTGAAACCAGATTCTAGCAGGTTGGAAAACATTAAGTCTTGGGTGCTTGGCGCTTTCGCTCTTCTGTGTCTTCTTGGCCTCACCTGGTCCTTTGGGTTGCTTTTTATTAATGAGGAGACTATTGTGATGGCATATCTCTTCACTATATTTAATGCTTTCCAGGGAGTGTTCATTTTCATCTTTCACTGTGCTCTCCAAAAGAAAGTACGAAAAGAATATGGCAAGTGCTTCAGACACTCATACTGCTGTGGAGGCCTCCCAACTGAGAGTCCCCACAGTTCAGTGAAGGCATCAACCACCAGAACCAGTGCTCGCTATTCCTCTGGCACACAGAGTCGTATAAGAAGAATGTGGAATGATACTGTGAGAAAACAATCAGAATCTTCTTTTATCTCAGGTGACATCAATAGCACTTCAACACTTAATCAAGGAATGACTGGCAATTACCTACTAACAAACCCTCTTCTTCGACCCCACGGCACTAACAACCCCTATAACACATTGCTCGCTGAAACAGTTGTATGTAATGCCCCTTCAGCTCCTGTATTTAACTCACCAGGACATTCACTGAACAATGCCAGGGATACAAGTGCCATGGATACTCTACCGCTAAATGGTAATTTTAACAACAGCTACTCGCTGCACAAGGGTGACTATAATGACAGCGTGCAAGTTGTGGACTGTGGACTAAGTCTGAATGATACTGCTTTTGAGAAAATGATCATTTCAGAATTAGTGCACAACAACTTACGGGGCAGCAGCAAGACTCACAACCTCGAGCTCACGCTACCAGTCAAACCTGTGATTGGAGGTAGCAGCAGTGAAGATGATGCTATTGTGGCAGATGCTTCATCTTTAATGCACAGCGACAACCCAGGGCTGGAGCTCCATCACAAAGAACTCGAGGCACCACTTATTCCTCAGCGGACTCACTCCCTTCTGTACCAACCCCAGAAGAAAGTGAAGTCCGAGGGAACTGACAGCTATGTCTCCCAACTGACAGCAGAGGCTGAAGATCACCTACAGTCCCCCAACAGAGACTCTCTTTATACAAGCATGCCCAATCTTAGAGACTCTCCCTATCCGGAGAGCAGCCCTGACATGGAAGAAGACCTCTCTCCCTCCAGGAGGAGTGAGAATGAGGACATTTACTATAAAAGCATGCCAAATCTTGGAGCTGGCCATCAGCTTCAGATGTGCTACCAGATCAGCAGGGGCAATAGTGATGGTTATATAATCCCCATTAACAAAGAAGGGTGTATTCCAGAAGGAGATGTTAGAGAAGGACAAATGCAGCTGGTTACAAGTCTTTAA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.