NCBI Summary
Calmegin is a testis-specific endoplasmic reticulum chaperone protein. CLGN may play a role in spermatogeneisis and infertility. [provided by RefSeq, Jul 2008].
Protein
Protein (NP_004353)
Calmegin
Calmegin
CLGN
calmegin
Undefined
Curated
calnexin-calreticulin like
CalnexinFamily
b-sandwich / ConA-like
Glc(a1-3)Man(a1-2)Man(a1-2)Man / glucosylated N-glycan
0.544
MHFQAFWLCLGLLFISINAEFMDDDVETEDFEENSEEIDVNESELSSEIKYKTPQPIGEVYFAETFDSGRLAGWVLSKAKKDDMDEEISIYDGRWEIEELKENQVPGDRGLVLKSRAKHHAISAVLAKPFIFADKPLIVQYEVNFQDGIDCGGAYIKLLADTDDLILENFYDKTSYIIMFGPDKCGEDYKLHFIFRHKHPKTGVFEEKHAKPPDVDLKKFFTDRKTHLYTLVMNPDDTFEVLVDQTVVNKGSLLEDVVPPIKPPKEIEDPNDKKPEEWDERAKIPDPSAVKPEDWDESEPAQIEDSSVVKPAGWLDDEPKFIPDPNAEKPDDWNEDTDGEWEAPQILNPACRIGCGEWKPPMIDNPKYKGVWRPPLVDNPNYQGIWSPRKIPNPDYFEDDHPFLLTSFSALGLELWSMTSDIYFDNFIICSEKEVADHWAADGWRWKIMIANANKPGVLKQLMAAAEGHPWLWLIYLVTAGVPIALITSFCWPRKVKKKHKDTEYKKTDICIPQTKGVLEQEEKEEKAALEKPMDLEEEKKQNDGEMLEKEEESEPEEKSEEEIEIIEGQEESNQSNKSGSEDEMKEADESTGSGDGPIKSVRKRRVRKD
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
The location of the lectin domain structural model is: 59-446
We infer [0.85, 1.12] Å as the interval of error of this structural model.
Template 1: 1JHN chain: A, P24643, NP_001003232.1, sequence identity: 70.6%, coverage: 100.0%, location in sequence: 61-458, (61-458 in PDB).
Template 2: 3O0W chain: A, P14211, NP_031617.1, sequence identity: 36.3%, coverage: 84.3%, location in sequence: 18-362, (18-362 in PDB).
Template 3: 6ENY chain: G, P27797, NP_004334.1, sequence identity: 36.3%, coverage: 84.3%, location in sequence: 18-386, (18-386 in PDB).
Show the alignment used for the construction of the structural model, Download.
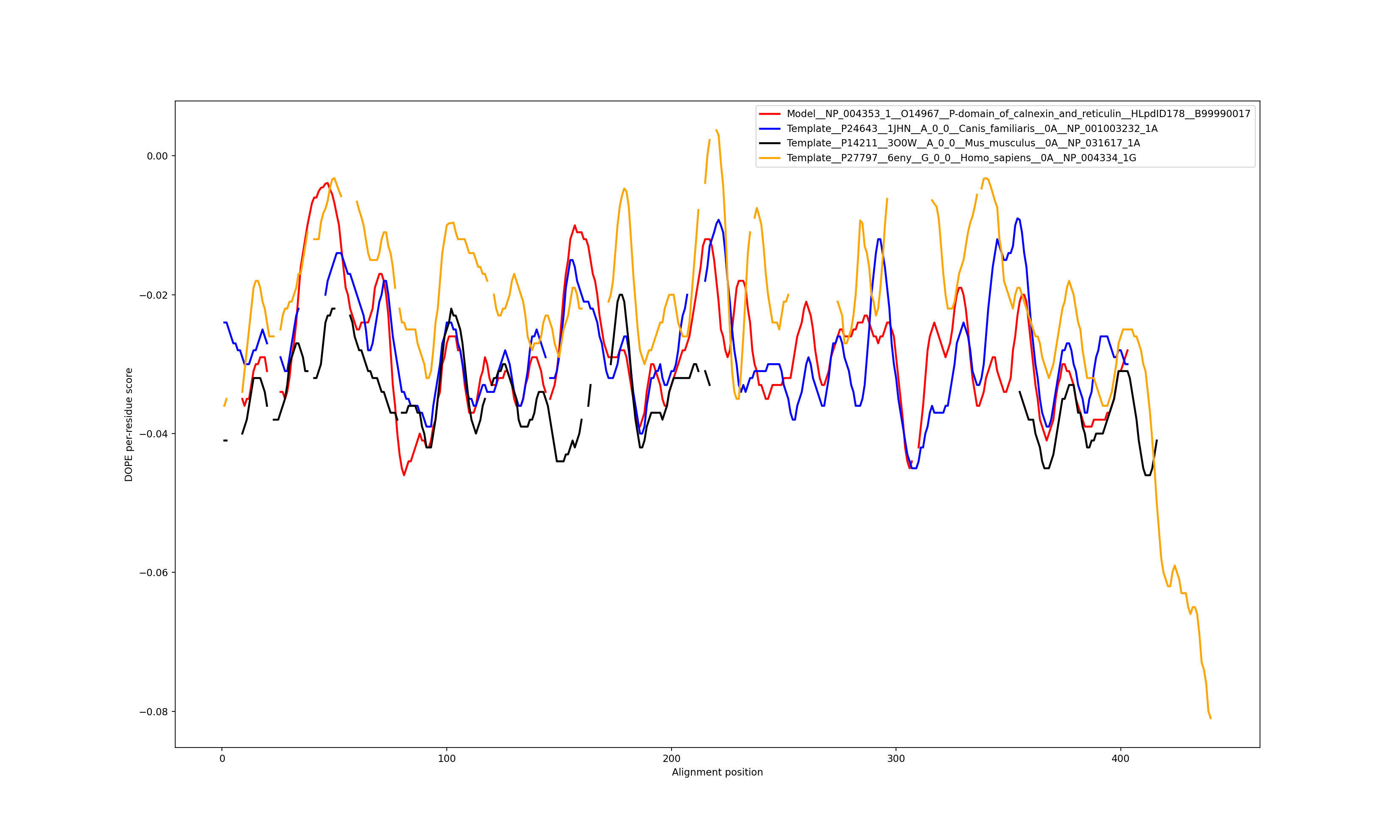
Show the plot of DOPE energy score, Download.
We infer [0.85, 1.12] Å as the interval of error of this structural model.
Template 1: 1JHN chain: A, P24643, NP_001003232.1, sequence identity: 70.6%, coverage: 100.0%, location in sequence: 61-458, (61-458 in PDB).
Template 2: 3O0W chain: A, P14211, NP_031617.1, sequence identity: 36.3%, coverage: 84.3%, location in sequence: 18-362, (18-362 in PDB).
Template 3: 6ENY chain: G, P27797, NP_004334.1, sequence identity: 36.3%, coverage: 84.3%, location in sequence: 18-386, (18-386 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
Interacts with PPIB. Interacts with ADAM2 (By similarity). Interacts with PDILT
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- Genome-Wide Gene-Sodium Interaction Analyses on Blood Pressure: The Genetic Epidemiology Network of Salt-Sensitivity Study. [27271309]
- An organelle-specific protein landscape identifies novel diseases and molecular mechanisms. [27173435]
- A Dynamic Protein Interaction Landscape of the Human Centrosome-Cilium Interface. [26638075]
- Glycan specificity of a testis-specific lectin chaperone calmegin and effects of hydrophobic interactions. [24769397]
- Genome-wide association with select biomarker traits in the Framingham Heart Study. [17903293]
- Calmegin is required for fertilin alpha/beta heterodimerization and sperm fertility. [11784061]
- Molecular chaperone calmegin localization to the endoplasmic reticulum of meiotic and post-meiotic germ cells in the mouse testis. [10495883]
- Cloning and characterization of the human Calmegin gene encoding putative testis-specific chaperone. [9434179]
- The putative chaperone calmegin is required for sperm fertility. [9177349]
- Molecular cloning of a novel Ca(2+)-binding protein (calmegin) specifically expressed during male meiotic germ cell development. [8126001]
UniProt Main References (5 PubMed Identifiers)
- Complete sequencing and characterization of 21,243 full-length human cDNAs. [14702039]
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
- Global, in vivo, and site-specific phosphorylation dynamics in signaling networks. [17081983]
- A developmentally regulated chaperone complex for the endoplasmic reticulum of male haploid germ cells. [17507649]
- Initial characterization of the human central proteome. [21269460]
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_004362.3)
m7G-5')ppp(5'-AGUAGUCGCUGCUGCGCGGCCGCCGGCGGGACUGGUCUGAAGAGACGCGGGGACCAAGUGGCAACGACUUGGACAUCUGAGCUGUCACUGCCGAAAACAGGCCGCAAGAGAGAUAAUCAAUAUGCAUUUCCAAGCCUUUUGGCUAUGUUUGGGUCUUCUGUUCAUCUCAAUUAAUGCAGAAUUUAUGGAUGAUGAUGUUGAGACGGAAGACUUUGAAGAAAAUUCAGAAGAAAUUGAUGUUAAUGAAAGUGAACUUUCCUCAGAGAUUAAAUAUAAGACACCUCAACCUAUAGGAGAAGUAUAUUUUGCAGAAACUUUUGAUAGUGGAAGGUUGGCUGGAUGGGUCUUAUCAAAAGCAAAGAAAGAUGACAUGGAUGAGGAAAUUUCAAUAUACGAUGGAAGAUGGGAAAUUGAAGAGUUGAAAGAAAACCAGGUACCUGGUGACAGAGGACUGGUAUUAAAAUCUAGAGCAAAGCAUCAUGCAAUAUCUGCUGUAUUAGCAAAACCAUUCAUUUUUGCUGAUAAACCCUUGAUAGUUCAAUAUGAAGUAAAUUUUCAAGAUGGUAUUGAUUGUGGAGGUGCAUACAUUAAACUCCUAGCAGACACUGAUGAUUUGAUUCUGGAAAACUUUUAUGAUAAAACAUCCUAUAUCAUUAUGUUUGGACCAGAUAAAUGUGGAGAAGAUUAUAAACUUCAUUUUAUCUUCAGACAUAAACAUCCCAAAACUGGAGUUUUCGAAGAGAAACAUGCCAAACCUCCAGAUGUAGACCUUAAAAAGUUCUUUACAGACAGGAAGACUCAUCUUUAUACCCUUGUGAUGAAUCCAGAUGACACAUUUGAGGUGUUAGUUGAUCAAACAGUUGUAAACAAAGGAAGCCUCCUAGAGGAUGUGGUUCCUCCUAUCAAACCUCCCAAAGAAAUUGAAGAUCCCAAUGAUAAAAAACCUGAGGAAUGGGAUGAAAGAGCAAAAAUUCCUGAUCCUUCUGCCGUCAAACCAGAAGACUGGGAUGAAAGUGAACCUGCCCAAAUAGAAGAUUCAAGUGUUGUUAAACCUGCUGGCUGGCUUGAUGAUGAACCAAAAUUUAUCCCUGAUCCUAAUGCUGAAAAACCUGAUGACUGGAAUGAAGACACGGAUGGAGAAUGGGAGGCACCUCAGAUUCUUAAUCCAGCAUGUCGGAUUGGGUGUGGUGAGUGGAAACCUCCCAUGAUAGAUAACCCAAAAUACAAAGGAGUAUGGAGACCUCCACUGGUCGAUAAUCCUAACUAUCAGGGAAUCUGGAGUCCUCGAAAAAUUCCUAAUCCAGAUUAUUUCGAAGAUGAUCAUCCAUUUCUUCUGACUUCUUUCAGUGCUCUUGGUUUAGAGCUUUGGUCUAUGACCUCUGAUAUCUACUUUGAUAAUUUUAUUAUCUGUUCGGAAAAGGAAGUAGCAGAUCACUGGGCUGCAGAUGGUUGGAGAUGGAAAAUAAUGAUAGCAAAUGCUAAUAAGCCUGGUGUAUUAAAACAGUUAAUGGCAGCUGCUGAAGGGCACCCAUGGCUUUGGUUGAUUUAUCUUGUGACAGCAGGAGUGCCAAUAGCAUUAAUUACUUCAUUUUGUUGGCCAAGAAAAGUAAAGAAAAAACAUAAAGAUACAGAGUAUAAAAAAACCGACAUAUGUAUACCACAAACAAAAGGAGUACUAGAGCAAGAAGAAAAGGAAGAGAAAGCAGCCCUGGAAAAACCAAUGGACCUGGAAGAGGAAAAAAAGCAAAAUGAUGGUGAAAUGCUUGAAAAAGAAGAGGAAAGUGAACCUGAGGAAAAGAGUGAAGAAGAAAUUGAAAUCAUAGAAGGGCAAGAAGAAAGUAAUCAAUCAAAUAAGUCUGGGUCAGAGGAUGAGAUGAAAGAAGCAGAUGAGAGCACAGGAUCUGGAGAUGGGCCGAUAAAGUCAGUACGCAAAAGAAGAGUACGAAAGGACUAAACUAGAUUGAAAUAUUUUUAAUUCCCGAGAGGGAUGUUUGGCAUUGUAAAAAUCAGCAUGCCAGACCUGAACUUUAAUCAGUCUGCACAUCCUGUUUCUAAUAUCUAGCAACAUUAUAUUCUUUCAGACAUUUAUUUUAGUCCUUCAUUUCAGAGGAAAAAGAAGCAACUUUGAAGUUACCUCAUCUUUGAAUUUAGAAUAAAAGUGGCACAUUACAUAUCGGAUCUAAGAGAUUAAUACCAUUAGAAGUUACACAGUUUUAGUUGUUUGGAGAUAGUUUUGGUUUGUACAGAACAAAAUAAUAUGUAGCAGCUUCAUUGCUAUUGGAAAAAUCAGUUAUUGGAAUUUCCACUUAAAUGGCUAUACAACAAUAUAACUGGUAGUUCUAUAAUAAAAAUGAGCAUAUGUUCUGUUGUGAAGAGCUAAAUGCAAUAAAGUUUCUGUAUGGUUGUUUGAUUCUAUCAACAAUUGAAAGUGUUGUAUAUGACCCACAUUUACCUAGUUUGUGUCAAAUUAUAGUUACAGUGAGUUGUUUGCUUAAAUUAUAGAUUCCUUUAAGGACAUGCCUUGUUCAUAAAAUCACUGGAUUAUAUUGCAGCAUAUUUUACAUUUGAAUACAAGGAUAAUGGGUUUUAUCAAAACAAAAUGAUGUACAGAUUUUUUUUCAAGUUUUUAUAGUUGCUUUAUGCCAGAGUGGUUUACCCCAUUCACAAAAUUUCUUAUGCAUACAUUGCUAUUGAAAAUAAAAUUUAAAUAUUUUUUCAUCCUGAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 1047)
calmegin
strand -
NCBI CDS gene sequence (1833 bp)
5'-ATGCATTTCCAAGCCTTTTGGCTATGTTTGGGTCTTCTGTTCATCTCAATTAATGCAGAATTTATGGATGATGATGTTGAGACGGAAGACTTTGAAGAAAATTCAGAAGAAATTGATGTTAATGAAAGTGAACTTTCCTCAGAGATTAAATATAAGACACCTCAACCTATAGGAGAAGTATATTTTGCAGAAACTTTTGATAGTGGAAGGTTGGCTGGATGGGTCTTATCAAAAGCAAAGAAAGATGACATGGATGAGGAAATTTCAATATACGATGGAAGATGGGAAATTGAAGAGTTGAAAGAAAACCAGGTACCTGGTGACAGAGGACTGGTATTAAAATCTAGAGCAAAGCATCATGCAATATCTGCTGTATTAGCAAAACCATTCATTTTTGCTGATAAACCCTTGATAGTTCAATATGAAGTAAATTTTCAAGATGGTATTGATTGTGGAGGTGCATACATTAAACTCCTAGCAGACACTGATGATTTGATTCTGGAAAACTTTTATGATAAAACATCCTATATCATTATGTTTGGACCAGATAAATGTGGAGAAGATTATAAACTTCATTTTATCTTCAGACATAAACATCCCAAAACTGGAGTTTTCGAAGAGAAACATGCCAAACCTCCAGATGTAGACCTTAAAAAGTTCTTTACAGACAGGAAGACTCATCTTTATACCCTTGTGATGAATCCAGATGACACATTTGAGGTGTTAGTTGATCAAACAGTTGTAAACAAAGGAAGCCTCCTAGAGGATGTGGTTCCTCCTATCAAACCTCCCAAAGAAATTGAAGATCCCAATGATAAAAAACCTGAGGAATGGGATGAAAGAGCAAAAATTCCTGATCCTTCTGCCGTCAAACCAGAAGACTGGGATGAAAGTGAACCTGCCCAAATAGAAGATTCAAGTGTTGTTAAACCTGCTGGCTGGCTTGATGATGAACCAAAATTTATCCCTGATCCTAATGCTGAAAAACCTGATGACTGGAATGAAGACACGGATGGAGAATGGGAGGCACCTCAGATTCTTAATCCAGCATGTCGGATTGGGTGTGGTGAGTGGAAACCTCCCATGATAGATAACCCAAAATACAAAGGAGTATGGAGACCTCCACTGGTCGATAATCCTAACTATCAGGGAATCTGGAGTCCTCGAAAAATTCCTAATCCAGATTATTTCGAAGATGATCATCCATTTCTTCTGACTTCTTTCAGTGCTCTTGGTTTAGAGCTTTGGTCTATGACCTCTGATATCTACTTTGATAATTTTATTATCTGTTCGGAAAAGGAAGTAGCAGATCACTGGGCTGCAGATGGTTGGAGATGGAAAATAATGATAGCAAATGCTAATAAGCCTGGTGTATTAAAACAGTTAATGGCAGCTGCTGAAGGGCACCCATGGCTTTGGTTGATTTATCTTGTGACAGCAGGAGTGCCAATAGCATTAATTACTTCATTTTGTTGGCCAAGAAAAGTAAAGAAAAAACATAAAGATACAGAGTATAAAAAAACCGACATATGTATACCACAAACAAAAGGAGTACTAGAGCAAGAAGAAAAGGAAGAGAAAGCAGCCCTGGAAAAACCAATGGACCTGGAAGAGGAAAAAAAGCAAAATGATGGTGAAATGCTTGAAAAAGAAGAGGAAAGTGAACCTGAGGAAAAGAGTGAAGAAGAAATTGAAATCATAGAAGGGCAAGAAGAAAGTAATCAATCAAATAAGTCTGGGTCAGAGGATGAGATGAAAGAAGCAGATGAGAGCACAGGATCTGGAGATGGGCCGATAAAGTCAGTACGCAAAAGAAGAGTACGAAAGGACTAA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.