NCBI Summary
This gene encodes a member of the polycystin protein family. The encoded protein contains 11 transmembrane domains, a latrophilin/CL-1-like GPCR proteolytic site (GPS) domain, and a polycystin-1, lipoxygenase, alpha-toxin (PLAT) domain. This protein may function as a component of cation channel pores. This gene appears to be a polymorphic pseudogene in humans, and the reference genome encodes a non-functional allele. Alternative splicing results in multiple transcript variants. [provided by RefSeq, Mar 2019].
Protein
Protein (NP_001070248)
Polycystin-1L2
Polycystic kidney disease protein 1-like 2 (PC1-like 2 protein) (Polycystin-1L2)
PKD1L2
polycystin 1 like 2 (gene/pseudogene)
Undefined
Very low evidence
C-type lectin
Undefined
C-type - Polycysti
a/b mixed / C-type lectin-like
Uncharacterised
Undefined
0.336
MSAVGLVLLVLALRLRATTVKPEEGSFCSNSQVAFRDACYEFVPLGRTFRDAQSWCEGQGGHLVFIQDEGTQWFLQKHISQDREWWIGLTWNLARNGTTEGPGTWLDTSNVTYSNWHGGQAAAAPDTCGHIGRGPSSEWVTSDCAQTFAFMCEFRVGQSLACEGLNATVHCGLGQVIQVQDAVYGRQNPHFCTQDAGRPSDLEQGCSWANVKEEVAGQCQELQSCQVAADETYFGNLCPTQGSYLWVQYQCREALQLMVSSESFIFDNVTISLTWLLSPYIGNLSCIISTGDSHTFDPYNPPSVSSNVTHQFTSPGEFTVFAECTTSEWHVTAQRQVTVRDKMETLSVTACSGLSQSGAGPLCQAVFGDPLWIQVELDGGTGVTYTVLLGDITLAESTTQKGSLPYNLILDRETQKLMGPGRHRLEIQATGNTTTSTISRNITVHLVELLSGLQASWASDHLELGQDLLITISLAQGTPEELTFEVAGLNATFSHEQVSFGEPFGICRLAVPVEGTFLVTMLVRNAFSNLSLEIGNITITAPSGLQEPSGMNAEGKSKDKGDMEVYIQPGPYVDPFTTVTLGWPDNDKELRFQWSCGSCWALWSSCVERQLLRTDQRELVVPASCLPPPDSAVTLRLAVLRGQELENRAEQCLYVSAPWELRPRVSCERNCRPVNASKDILLRVTMGEDSPVAMFSWYLDNTPTEQAEPLLDACRLRGFWPRSLTLLQSNTSTLLLNSSFLQSRGEVIRIRATALTRHAYGEDTYVISTVPPREVPACTIAPEEGTVLTSFAIFCNASTALGPLEFCFCLESGSCLHCGPEPALPSVYLPLGEENNDFVLTVVISATNRAGDTQQTQAMAKVALGDTCVEDVAFQAAVSEKIPTALQGEGGPEQLLQLAKAVSSMLNQEHESQGSGQSLSIDVRQKVREHVLGSLSAVTTGLEDVQRVQELAEVLREVTCRSKELTPSAQGSCMGDSWEGAPPAAHVSHAR
No structure currently available in the PDB RCSB Databank.
Structural models
AlphaFold v2: AF-Q7Z442-F1DownloadSee the associated sequence to the AlphaFold v2 model, which is different to this entry(NCBI sequence).
SWISS-MODEL structural models
The location of the lectin domain structural model is: 23-159
We infer [1.52, 1.94] Å as the interval of error of this structural model.
Template 1: 2OX9 chain: A, Q8K4Q8, NP_569716.2, sequence identity: 30.7%, coverage: 92.0%, location in sequence: 606-735, (606-735 in PDB).
Template 2: 2OX8 chain: A, Q5KU26, NP_569057.2, sequence identity: 28.5%, coverage: 91.2%, location in sequence: 606-734, (606-734 in PDB).
Template 3: 4KZV chain: A, E1BHM0, XP_010803863.1, sequence identity: 27.0%, coverage: 91.2%, location in sequence: 78-208, (78-208 in PDB).
Show the alignment used for the construction of the structural model, Download.
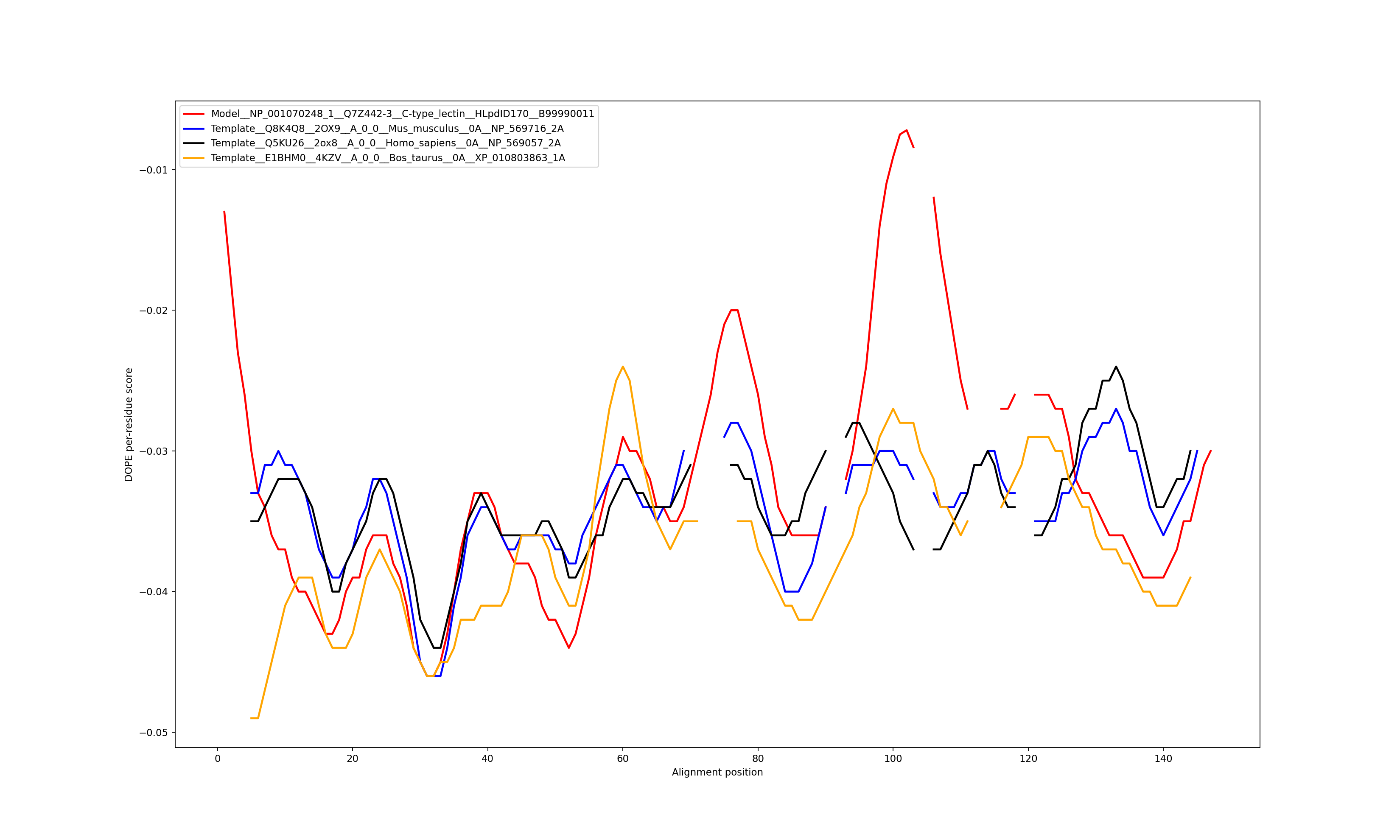
Show the plot of DOPE energy score, Download.
We infer [1.52, 1.94] Å as the interval of error of this structural model.
Template 1: 2OX9 chain: A, Q8K4Q8, NP_569716.2, sequence identity: 30.7%, coverage: 92.0%, location in sequence: 606-735, (606-735 in PDB).
Template 2: 2OX8 chain: A, Q5KU26, NP_569057.2, sequence identity: 28.5%, coverage: 91.2%, location in sequence: 606-734, (606-734 in PDB).
Template 3: 4KZV chain: A, E1BHM0, XP_010803863.1, sequence identity: 27.0%, coverage: 91.2%, location in sequence: 78-208, (78-208 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
May interact via its C-terminus with GNAS and GNAI1
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (7 PubMed Identifiers)
- A copy number variation in PKD1L2 is associated with colorectal cancer predisposition in korean population. [27605020]
- The TRPP subfamily and polycystin-1 proteins. [24756726]
- Direct recording and molecular identification of the calcium channel of primary cilia. [24336289]
- Fine mapping and association studies of a high-density lipoprotein cholesterol linkage region on chromosome 16 in French-Canadian subjects. [19844255]
- Upregulation of PKD1L2 provokes a complex neuromuscular disease in the mouse. [19578180]
- Polycystin-1L2 is a novel G-protein-binding protein. [15203210]
- Identification of two novel polycystic kidney disease-1-like genes in human and mouse genomes. [12782129]
UniProt Main References (4 PubMed Identifiers)
- Complete sequencing and characterization of 21,243 full-length human cDNAs. [14702039]
- Prediction of the coding sequences of unidentified human genes. XXI. The complete sequences of 60 new cDNA clones from brain which code for large proteins. [11572484]
- The sequence and analysis of duplication-rich human chromosome 16. [15616553]
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
RNA
RNA (Transcript ID: NM_001076780.2)
polycystin 1 like 2 (gene/pseudogene), transcript variant 3
m7G-5')ppp(5'-AGAGGCCCCAGCAGUGGUUCAAGCAUGAGUGCAGUGGGCUUGGUACUCCUGGUGCUUGCUCUGAGGCUUAGGGCCACCACUGUUAAGCCAGAGGAAGGCAGCUUUUGCUCUAACAGCCAGGUGGCCUUCAGAGAUGCUUGCUAUGAAUUUGUGCCACUCGGACGCACCUUCCGUGAUGCCCAGAGCUGGUGCGAGGGGCAAGGAGGCCAUUUGGUCUUCAUUCAGGACGAAGGCACCCAGUGGUUUCUGCAGAAGCACAUCUCCCAGGACAGGGAAUGGUGGAUUGGACUCACGUGGAACUUGGCACGGAAUGGAACCACGGAGGGGCCGGGGACUUGGUUGGACACCUCCAAUGUGACCUACAGCAACUGGCAUGGAGGGCAGGCCGCCGCUGCCCCUGACACCUGCGGCCACAUCGGGAGAGGCCCUUCCUCUGAGUGGGUGACCUCGGACUGCGCCCAGACCUUCGCCUUCAUGUGCGAGUUCCGGGUUGGCCAGAGCCUGGCCUGCGAGGGACUCAAUGCCACCGUGCACUGUGGCUUGGGGCAGGUCAUCCAGGUCCAGGAUGCCGUCUACGGGCGCCAGAAUCCCCAUUUCUGCACCCAGGAUGCCGGGCGUCCUUCAGAUCUGGAGCAGGGAUGCAGCUGGGCCAACGUCAAGGAGGAGGUGGCAGGCCAGUGCCAGGAGCUACAGUCAUGCCAGGUGGCAGCAGAUGAGACCUACUUUGGAAACCUGUGUCCGACUCAGGGCAGUUACCUGUGGGUGCAGUACCAGUGCCGGGAAGCCCUGCAGCUGAUGGUGUCCAGUGAGAGUUUCAUCUUUGACAAUGUCACCAUCUCCCUGACGUGGCUCCUCUCACCCUACAUAGGAAACCUGUCCUGUAUAAUUAGUACAGGAGACAGCCACACUUUUGAUCCCUACAACCCGCCGAGUGUGUCCAGCAAUGUGACCCACCAGUUCACAUCUCCUGGGGAAUUCACCGUGUUUGCUGAAUGCACAACCAGUGAGUGGCAUGUGACAGCUCAGAGGCAGGUGACCGUGCGAGACAAGAUGGAGACGCUCAGUGUGACUGCAUGCUCCGGCCUGUCCCAGUCAGGAGCCGGCCCUCUCUGCCAGGCUGUCUUUGGGGAUCCUCUGUGGAUUCAGGUGGAGCUUGAUGGAGGAACAGGAGUGACUUACACUGUGCUUUUGGGUGACAUAACCCUGGCCGAGUCCACCACCCAAAAGGGCUCGCUACCGUACAAUCUGAUCCUGGACAGAGAAACCCAGAAACUGAUGGGCCCUGGGAGGCACCGCCUGGAGAUCCAAGCCACCGGCAACACCACCACCUCUACAAUCUCCAGAAACAUUACAGUCCACUUGGUGGAGCUGCUGUCAGGGCUGCAGGCCUCCUGGGCUUCUGACCAUUUGGAGCUUGGACAGGACCUAUUGAUCACCAUCUCAUUGGCUCAGGGCACCCCGGAAGAGCUGACCUUUGAGGUGGCUGGACUCAAUGCAACCUUCUCCCACGAGCAAGUGAGCUUUGGAGAGCCAUUUGGGAUUUGCCGCCUGGCUGUUCCGGUUGAAGGCACCUUUCUGGUCACCAUGCUGGUGAGGAAUGCCUUCUCCAACCUGAGUUUGGAAAUCGGGAACAUCACUAUCACAGCCCCUUCCGGUCUCCAAGAACCAUCUGGGAUGAAUGCUGAAGGAAAGAGUAAAGAUAAAGGCGAUAUGGAGGUGUACAUCCAACCUGGUCCAUAUGUGGAUCCUUUCACGACAGUGACCCUGGGCUGGCCAGACAAUGACAAGGAGUUACGCUUCCAAUGGUCAUGUGGGUCUUGCUGGGCUCUGUGGAGCAGCUGUGUUGAGAGGCAGCUGCUUCGCACAGACCAGAGGGAGCUGGUGGUUCCAGCAUCCUGCCUGCCGCCGCCUGACUCUGCUGUCACCCUGCGCCUGGCUGUUCUGAGAGGCCAAGAGCUGGAGAACAGGGCAGAGCAGUGCCUCUACGUGUCUGCGCCCUGGGAACUCAGGCCUCGAGUCAGCUGUGAGAGGAACUGCAGGCCAGUUAAUGCCAGCAAAGACAUUCUGCUCAGGGUCACCAUGGGGGAGGACUCUCCAGUGGCUAUGUUCAGCUGGUAUUUGGACAACACCCCAACAGAGCAGGCUGAGCCCCUCCUGGAUGCCUGCAGACUCAGAGGAUUUUGGCCAAGGUCCUUAACCCUCCUCCAGAGCAACACCUCCACGUUGCUGUUGAACAGCUCGUUUCUGCAGUCCCGGGGAGAGGUCAUCCGAAUCAGAGCCACAGCACUGACCAGGCAUGCCUAUGGGGAGGACACCUAUGUGAUCAGCACUGUGCCUCCCCGUGAGGUGCCUGCCUGCACUAUUGCCCCAGAGGAGGGCACCGUUCUGACGAGCUUUGCCAUCUUCUGCAACGCCUCCACAGCCCUGGGACCCCUGGAGUUCUGCUUCUGUCUGGAAUCAGGUUCCUGCCUACACUGUGGCCCUGAACCUGCCCUCCCAUCAGUGUAUCUGCCACUUGGAGAGGAGAACAAUGACUUUGUGCUGACAGUAGUUAUUUCUGCCACCAAUCGUGCAGGGGACACGCAGCAGACCCAGGCCAUGGCUAAGGUGGCACUCGGAGACACAUGUGUUGAGGAUGUAGCAUUCCAGGCUGCCGUGUCAGAGAAAAUCCCCACAGCUCUGCAAGGCGAGGGUGGCCCCGAGCAGCUCCUCCAGCUGGCCAAGGCUGUGUCCUCCAUGCUGAACCAAGAGCAUGAAAGCCAGGGCUCAGGACAGUCACUGAGCAUAGACGUCAGACAGAAGGUCAGAGAGCAUGUGCUGGGAUCACUGUCUGCAGUCACCACCGGCUUGGAGGACGUGCAGAGGGUGCAGGAGCUGGCCGAGGUGCUGAGAGAGGUGACCUGCCGGAGUAAGGAACUCACACCCUCGGCCCAGGGGUCCUGCAUGGGCGAUUCAUGGGAAGGUGCCCCUCCUGCUGCCCAUGUAUCUCACGCUAGGUGAGAGGGCCUGUUUGCCCAGACUCUCACUCCUGCAUCUGCUGGUGAGCAAGUUGAGGGAGUAACUGAAUCUCAUUAAUAUUUGGGUGGCCAAAUGUGAGUCCAGACACUGCUACUGACUGCCCAUGUUCUCAACUUCAGUACAUGCCAGCCUGACAUCUGGCUGCCAGCUCCUGUGCUUCCUUAUCCUUCUGGGGGUCUUCUCUGACCCUCAGAGCCUACUGUACCUGCCCAUAUGGCUGUGAAUUCAUGCAGUGUUCAGUGACUAAUGAAGCUGGCUUAUAAACACCCCAGCUACCUCACCCCUCUUGAUGGAUAAUCCCAAGCAGGAGUGAAUCCCAGGUAAUGGGCUUGAUCACACUCCUGUACUGGCUUCCACCCUUCCCUGUCUCACACCCCCUACUCCCCACAAGUGUUUCUUGGGAUCAUGUCCAAAUAAAUGACUUGCUCUCAAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 114780)
polycystin 1 like 2 (gene/pseudogene)
strand -
NCBI CDS gene sequence (2976 bp)
5'-ATGAGTGCAGTGGGCTTGGTACTCCTGGTGCTTGCTCTGAGGCTTAGGGCCACCACTGTTAAGCCAGAGGAAGGCAGCTTTTGCTCTAACAGCCAGGTGGCCTTCAGAGATGCTTGCTATGAATTTGTGCCACTCGGACGCACCTTCCGTGATGCCCAGAGCTGGTGCGAGGGGCAAGGAGGCCATTTGGTCTTCATTCAGGACGAAGGCACCCAGTGGTTTCTGCAGAAGCACATCTCCCAGGACAGGGAATGGTGGATTGGACTCACGTGGAACTTGGCACGGAATGGAACCACGGAGGGGCCGGGGACTTGGTTGGACACCTCCAATGTGACCTACAGCAACTGGCATGGAGGGCAGGCCGCCGCTGCCCCTGACACCTGCGGCCACATCGGGAGAGGCCCTTCCTCTGAGTGGGTGACCTCGGACTGCGCCCAGACCTTCGCCTTCATGTGCGAGTTCCGGGTTGGCCAGAGCCTGGCCTGCGAGGGACTCAATGCCACCGTGCACTGTGGCTTGGGGCAGGTCATCCAGGTCCAGGATGCCGTCTACGGGCGCCAGAATCCCCATTTCTGCACCCAGGATGCCGGGCGTCCTTCAGATCTGGAGCAGGGATGCAGCTGGGCCAACGTCAAGGAGGAGGTGGCAGGCCAGTGCCAGGAGCTACAGTCATGCCAGGTGGCAGCAGATGAGACCTACTTTGGAAACCTGTGTCCGACTCAGGGCAGTTACCTGTGGGTGCAGTACCAGTGCCGGGAAGCCCTGCAGCTGATGGTGTCCAGTGAGAGTTTCATCTTTGACAATGTCACCATCTCCCTGACGTGGCTCCTCTCACCCTACATAGGAAACCTGTCCTGTATAATTAGTACAGGAGACAGCCACACTTTTGATCCCTACAACCCGCCGAGTGTGTCCAGCAATGTGACCCACCAGTTCACATCTCCTGGGGAATTCACCGTGTTTGCTGAATGCACAACCAGTGAGTGGCATGTGACAGCTCAGAGGCAGGTGACCGTGCGAGACAAGATGGAGACGCTCAGTGTGACTGCATGCTCCGGCCTGTCCCAGTCAGGAGCCGGCCCTCTCTGCCAGGCTGTCTTTGGGGATCCTCTGTGGATTCAGGTGGAGCTTGATGGAGGAACAGGAGTGACTTACACTGTGCTTTTGGGTGACATAACCCTGGCCGAGTCCACCACCCAAAAGGGCTCGCTACCGTACAATCTGATCCTGGACAGAGAAACCCAGAAACTGATGGGCCCTGGGAGGCACCGCCTGGAGATCCAAGCCACCGGCAACACCACCACCTCTACAATCTCCAGAAACATTACAGTCCACTTGGTGGAGCTGCTGTCAGGGCTGCAGGCCTCCTGGGCTTCTGACCATTTGGAGCTTGGACAGGACCTATTGATCACCATCTCATTGGCTCAGGGCACCCCGGAAGAGCTGACCTTTGAGGTGGCTGGACTCAATGCAACCTTCTCCCACGAGCAAGTGAGCTTTGGAGAGCCATTTGGGATTTGCCGCCTGGCTGTTCCGGTTGAAGGCACCTTTCTGGTCACCATGCTGGTGAGGAATGCCTTCTCCAACCTGAGTTTGGAAATCGGGAACATCACTATCACAGCCCCTTCCGGTCTCCAAGAACCATCTGGGATGAATGCTGAAGGAAAGAGTAAAGATAAAGGCGATATGGAGGTGTACATCCAACCTGGTCCATATGTGGATCCTTTCACGACAGTGACCCTGGGCTGGCCAGACAATGACAAGGAGTTACGCTTCCAATGGTCATGTGGGTCTTGCTGGGCTCTGTGGAGCAGCTGTGTTGAGAGGCAGCTGCTTCGCACAGACCAGAGGGAGCTGGTGGTTCCAGCATCCTGCCTGCCGCCGCCTGACTCTGCTGTCACCCTGCGCCTGGCTGTTCTGAGAGGCCAAGAGCTGGAGAACAGGGCAGAGCAGTGCCTCTACGTGTCTGCGCCCTGGGAACTCAGGCCTCGAGTCAGCTGTGAGAGGAACTGCAGGCCAGTTAATGCCAGCAAAGACATTCTGCTCAGGGTCACCATGGGGGAGGACTCTCCAGTGGCTATGTTCAGCTGGTATTTGGACAACACCCCAACAGAGCAGGCTGAGCCCCTCCTGGATGCCTGCAGACTCAGAGGATTTTGGCCAAGGTCCTTAACCCTCCTCCAGAGCAACACCTCCACGTTGCTGTTGAACAGCTCGTTTCTGCAGTCCCGGGGAGAGGTCATCCGAATCAGAGCCACAGCACTGACCAGGCATGCCTATGGGGAGGACACCTATGTGATCAGCACTGTGCCTCCCCGTGAGGTGCCTGCCTGCACTATTGCCCCAGAGGAGGGCACCGTTCTGACGAGCTTTGCCATCTTCTGCAACGCCTCCACAGCCCTGGGACCCCTGGAGTTCTGCTTCTGTCTGGAATCAGGTTCCTGCCTACACTGTGGCCCTGAACCTGCCCTCCCATCAGTGTATCTGCCACTTGGAGAGGAGAACAATGACTTTGTGCTGACAGTAGTTATTTCTGCCACCAATCGTGCAGGGGACACGCAGCAGACCCAGGCCATGGCTAAGGTGGCACTCGGAGACACATGTGTTGAGGATGTAGCATTCCAGGCTGCCGTGTCAGAGAAAATCCCCACAGCTCTGCAAGGCGAGGGTGGCCCCGAGCAGCTCCTCCAGCTGGCCAAGGCTGTGTCCTCCATGCTGAACCAAGAGCATGAAAGCCAGGGCTCAGGACAGTCACTGAGCATAGACGTCAGACAGAAGGTCAGAGAGCATGTGCTGGGATCACTGTCTGCAGTCACCACCGGCTTGGAGGACGTGCAGAGGGTGCAGGAGCTGGCCGAGGTGCTGAGAGAGGTGACCTGCCGGAGTAAGGAACTCACACCCTCGGCCCAGGGGTCCTGCATGGGCGATTCATGGGAAGGTGCCCCTCCTGCTGCCCATGTATCTCACGCTAGGTGA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.