NCBI Summary
This RefSeq record was created from transcript and genomic sequence data to make the sequence consistent with the reference genome assembly. The genomic coordinates used for the transcript record were based on transcript alignments.
Protein
Protein (NP_997186)
Attractin-like 1
Attractin-like protein 1
ATRNL1
attractin like 1
Undefined
Very low evidence
C-type lectin
Undefined
C-type - Attractin
a/b mixed / C-type lectin-like
METGGRARTGTPQPAAPGVWRARPAGGGGGGASSWLLDGNSWLLCYGFLYLALYAQVSQSKPCERTGSCFSGRCVNSTCLCDPGWVGDQCQHCQGRFKLTEPSGYLTDGPINYKYKTKCTWLIEGYPNAVLRLRFNHFATECSWDHMYVYDGDSIYAPLIAVLSGLIVPEIRGNETVPEVVTTSGYALLHFFSDAAYNLTGFNIFYSINSCPNNCSGHGKCTTSVSVPSQVYCECDKYWKGEACDIPYCKANCGSPDHGYCDLTGEKLCVCNDSWQGPDCSLNVPSTESYWILPNVKPFSPSVGRASHKAVLHGKFMWVIGGYTFNYSSFQMVLNYNLESSIWNVGTPSRGPLQRYGHSLALYQENIFMYGGRIETNDGNVTDELWVFNIHSQSWSTKTPTVLGHGQQYAVEGHSAHIMELDSRDVVMIIIFGYSAIYGYTSSIQEYHISSNTWLVPETKGAIVQGGYGHTSVYDEITKSIYVHGGYKALPGNKYGLVDDLYKYEVNTKTWTILKESGFARYLHSAVLINGAMLIFGGNTHNDTSLSNGAKCFSADFLAYDIACDEWKILPKPNLHRDVNRFGHSAVVINGSMYIFGGFSSVLLNDILVYKPPNCKAFRDEELCKNAGPGIKCVWNKNHCESWESGNTNNILRAKCPPKTAASDDRCYRYADCASCTANTNGCQWCDDKKCISANSNCSMSVKNYTKCHVRNEQICNKLTSCKSCSLNLNCQWDQRQQECQALPAHLCGEGWSHIGDACLRVNSSRENYDNAKLYCYNLSGNLASLTTSKEVEFVLDEIQKYTQQKVSPWVGLRKINISYWGWEDMSPFTNTTLQWLPGEPNDSGFCAYLERAAVAGLKANPCTSMANGLVCEKPVVSPNQNARPCKKPCSLRTSCSNCTSNGMECMWCSSTKRCVDSNAYIISFPYGQCLEWQTATCSPQNCSGLRTCGQCLEQPGCGWCNDPSNTGRGHCIEGSSRGPMKLIGMHHSEMVLDTNLCPKEKNYEWSFIQCPACQCNGHSTCINNNVCEQCKNLTTGKQCQDCMPGYYGDPTNGGQCTACTCSGHANICHLHTGKCFCTTKGIKGDQCQLCDSENRYVGNPLRGTCYYSLLIDYQFTFSLLQEDDRHHTAINFIANPEQSNKNLDISINASNNFNLNITWSVGSTAGTISGEETSIVSKNNIKEYRDSFSYEKFNFRSNPNITFYVYVSNFSWPIKIQIAFSQHNTIMDLVQFFVTFFSCFLSLLLVAAVVWKIKQTCWASRRREQLLRERQQMASRPFASVDVALEVGAEQTEFLRGPLEGAPKPIAIEPCAGNRAAVLTVFLCLPRGSSGAPPPGQSGLAIASALIDISQQKASDSKDKTSGVRNRKHLSTRQGTCV
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
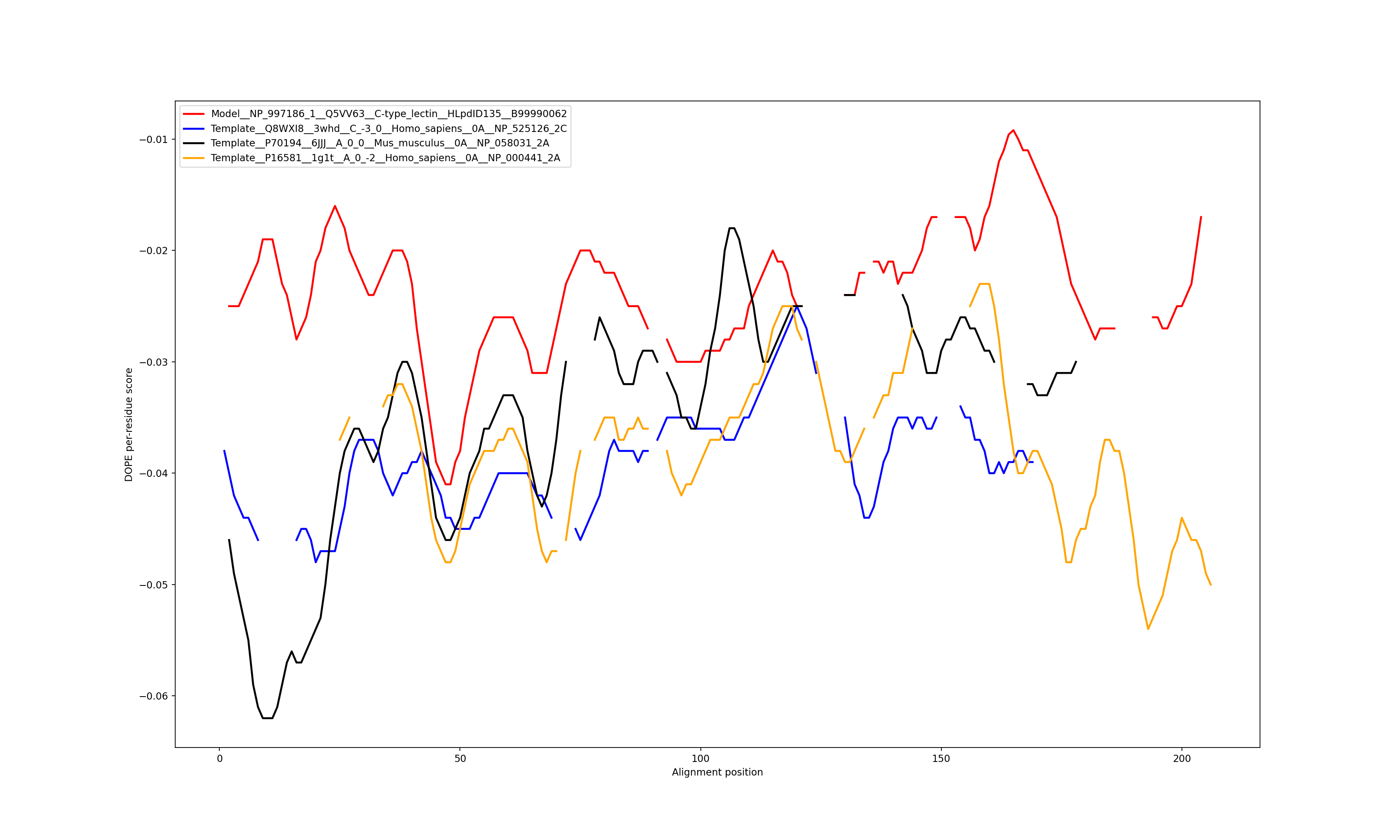
The location of the lectin domain structural model is: 729-911
We infer [1.67, 2.21] Å as the interval of error of this structural model.
Template 1: 3WHD chain: C, Q8WXI8, NP_525126.2, sequence identity: 16.9%, coverage: 80.3%, location in sequence: 63-215, (63-215 in PDB).
Template 2: 6JJJ chain: A, P70194, NP_058031.2, sequence identity: 15.8%, coverage: 80.3%, location in sequence: 393-543, (393-543 in PDB).
Template 3: 1G1T chain: A, P16581, NP_000441.2, sequence identity: 19.7%, coverage: 78.1%, location in sequence: 22-176, (1-155 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
We infer [1.67, 2.21] Å as the interval of error of this structural model.
Template 1: 3WHD chain: C, Q8WXI8, NP_525126.2, sequence identity: 16.9%, coverage: 80.3%, location in sequence: 63-215, (63-215 in PDB).
Template 2: 6JJJ chain: A, P70194, NP_058031.2, sequence identity: 15.8%, coverage: 80.3%, location in sequence: 393-543, (393-543 in PDB).
Template 3: 1G1T chain: A, P16581, NP_000441.2, sequence identity: 19.7%, coverage: 78.1%, location in sequence: 22-176, (1-155 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
Interacts with MC4R
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (4 PubMed Identifiers)
- Whole genome association scan for genetic polymorphisms influencing information processing speed. [21130836]
- Genetic and phenotypic studies of the dark-like mutant mouse. [18821597]
- A scan of chromosome 10 identifies a novel locus showing strong association with late-onset Alzheimer disease. [16385451]
- Characterization of a novel binding partner of the melanocortin-4 receptor: attractin-like protein. [14531729]
UniProt Main References (5 PubMed Identifiers)
- The DNA sequence and comparative analysis of human chromosome 10. [15164054]
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
- Complete sequencing and characterization of 21,243 full-length human cDNAs. [14702039]
- Prediction of the coding sequences of unidentified human genes. IX. The complete sequences of 100 new cDNA clones from brain which can code for large proteins in vitro. [9628581]
- Construction of expression-ready cDNA clones for KIAA genes: manual curation of 330 KIAA cDNA clones. [12168954]
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_207303.4)
attractin like 1, transcript variant 1
m7G-5')ppp(5'-AGUUGGCGCGGGCCGCGGGCGAGGCGGGGCCGCGCGCGGGGUCCCCUCCUCCUGCCGGUCAGGUCCCCUCAGGAGCGCCGGGCGCAGUCUGCGCCUCCCGCUCCCCGCCUCCGGCCGGGUCCGGGACGCCGCGGCUGUGGGGUCGGCCCGCUAAGGACAAGGUCGGGAGACUGGGUGGCGAUGCCCGAGUGCGACUGGAGGCAGCCGAGCGGAGGCGACGGCGGUUGGGAUCUGUCCCUCCUGACCGGGGAGCGGGACUCGGACGGGCGCCGGUGAGGAGGAGGAGAAGCGGCGGCGGAGAGGUUUUCUGCGGCCGGAAUUCCCUUCAACAGCAUCCCUGUCGGCGCCCGCGAGCGCAGUCUCGCCGGGCAGGGGCGCCGGGGAAGAUGGAGACUGGGGGCCGGGCCCGCACUGGUACCCCGCAGCCAGCGGCCCCGGGGGUGUGGAGGGCUCGGCCGGCGGGCGGCGGCGGCGGGGGCGCCUCCUCCUGGCUGCUGGACGGGAACAGCUGGCUGCUGUGCUAUGGCUUCCUCUACCUGGCGCUCUACGCGCAGGUGUCCCAGUCCAAGCCGUGCGAGAGGACCGGCUCCUGCUUCUCGGGCCGCUGUGUCAACUCCACCUGCCUCUGCGACCCGGGCUGGGUGGGGGACCAGUGCCAGCACUGCCAGGGCAGGUUCAAGUUAACAGAACCUUCUGGAUAUUUAACAGAUGGCCCAAUUAACUAUAAAUAUAAAACUAAAUGUACUUGGCUCAUUGAAGGCUAUCCAAAUGCAGUGUUAAGAUUAAGAUUCAAUCAUUUUGCUACAGAAUGUAGCUGGGAUCAUAUGUAUGUUUAUGAUGGAGAUUCAAUAUAUGCACCUUUAAUAGCUGUACUUAGUGGUUUGAUAGUCCCUGAAAUAAGGGGCAAUGAAACUGUGCCUGAAGUUGUUACUACAUCUGGCUAUGCACUGUUACAUUUUUUUAGUGAUGCUGCGUAUAAUCUAACUGGUUUCAACAUUUUCUAUUCAAUCAAUUCUUGUCCUAACAAUUGCUCUGGUCAUGGGAAGUGUACAACUAGUGUCUCUGUUCCAAGUCAAGUAUAUUGUGAAUGUGAUAAAUACUGGAAGGGUGAAGCUUGUGAUAUUCCUUACUGUAAAGCCAAUUGCGGCAGUCCAGAUCACGGUUACUGUGACCUGACUGGAGAAAAAUUAUGUGUCUGCAAUGAUAGUUGGCAAGGUCCUGAUUGUUCUUUGAAUGUUCCCUCUACUGAGUCUUACUGGAUUCUGCCAAACGUUAAACCCUUCAGUCCUUCUGUAGGUCGGGCUUCACAUAAAGCAGUUUUACACGGGAAAUUUAUGUGGGUGAUUGGUGGAUAUACUUUUAACUACAGUUCUUUUCAAAUGGUCCUAAAUUACAAUUUAGAAAGCAGUAUAUGGAAUGUAGGAACUCCAUCAAGGGGACCUCUCCAGAGAUAUGGACACUCUCUUGCUUUAUAUCAGGAAAACAUCUUUAUGUAUGGAGGCAGAAUUGAAACAAAUGAUGGCAAUGUCACAGAUGAAUUAUGGGUUUUUAACAUACAUAGUCAGUCAUGGAGUACAAAAACUCCUACUGUUCUUGGACAUGGUCAGCAGUAUGCUGUGGAGGGACAUUCAGCACAUAUUAUGGAGUUGGAUAGUAGAGAUGUUGUCAUGAUCAUAAUAUUUGGAUAUUCUGCAAUAUAUGGUUAUACAAGCAGCAUACAGGAAUACCAUAUCUCAUCAAACACUUGGCUUGUUCCAGAAACUAAAGGAGCUAUUGUACAAGGUGGAUAUGGCCAUACUAGUGUGUAUGAUGAAAUAACAAAGUCCAUUUAUGUUCAUGGAGGGUAUAAAGCAUUGCCAGGGAACAAAUAUGGAUUGGUUGAUGAUCUUUAUAAAUAUGAAGUUAACACUAAGACUUGGACUAUUUUGAAAGAAAGUGGGUUUGCCAGAUACCUUCAUUCAGCUGUUCUUAUCAAUGGAGCUAUGCUUAUUUUUGGAGGAAAUACCCAUAAUGACACUUCCUUGAGUAACGGUGCAAAAUGUUUUUCUGCCGAUUUCCUGGCAUAUGACAUAGCUUGUGAUGAAUGGAAAAUACUACCAAAACCAAAUCUUCAUAGAGAUGUCAACAGAUUUGGACACUCUGCAGUAGUCAUUAACGGGUCCAUGUAUAUAUUUGGGGGAUUUUCUAGUGUACUCCUUAAUGAUAUCCUUGUAUACAAGCCUCCAAAUUGCAAGGCUUUCAGAGAUGAAGAACUUUGUAAAAAUGCUGGUCCAGGGAUAAAAUGUGUUUGGAAUAAAAAUCACUGUGAAUCUUGGGAAUCUGGGAAUACUAAUAAUAUUCUUAGAGCAAAGUGCCCUCCUAAAACAGCUGCUUCUGAUGACAGAUGUUACAGAUAUGCAGAUUGUGCCAGCUGUACUGCCAAUACAAAUGGGUGCCAAUGGUGUGAUGACAAGAAAUGCAUUUCGGCAAAUAGUAACUGCAGUAUGUCUGUCAAGAACUACACCAAAUGUCAUGUGAGAAAUGAGCAGAUUUGUAACAAACUUACCAGCUGUAAAAGCUGUUCACUAAACUUGAAUUGCCAGUGGGAUCAGAGACAGCAAGAAUGCCAGGCUUUACCAGCUCAUCUUUGUGGAGAAGGAUGGAGUCAUAUUGGGGAUGCUUGUCUUAGAGUCAAUUCCAGUAGAGAAAACUAUGACAAUGCAAAACUUUAUUGCUAUAAUCUUAGUGGAAAUCUUGCUUCAUUAACAACCUCAAAAGAAGUAGAAUUUGUUCUGGAUGAAAUACAGAAGUAUACACAACAGAAAGUAUCACCUUGGGUAGGCUUGCGCAAGAUCAAUAUAUCCUAUUGGGGAUGGGAAGACAUGUCUCCUUUUACAAACACAACACUACAGUGGCUUCCUGGCGAACCCAAUGAUUCUGGGUUUUGUGCAUAUCUGGAAAGGGCUGCAGUGGCAGGCUUAAAAGCUAAUCCUUGUACAUCUAUGGCAAAUGGCCUUGUCUGUGAAAAACCUGUUGUUAGUCCAAAUCAAAAUGCGAGGCCGUGCAAAAAGCCAUGCUCUCUGAGGACAUCAUGUUCCAACUGUACAAGCAAUGGCAUGGAGUGUAUGUGGUGCAGCAGUACGAAACGAUGUGUUGACUCUAAUGCCUAUAUCAUCUCUUUUCCAUAUGGACAAUGUCUAGAGUGGCAAACUGCCACCUGCUCCCCUCAAAAUUGUUCUGGAUUGAGAACCUGUGGACAGUGUUUGGAACAGCCUGGAUGUGGCUGGUGCAAUGAUCCUAGUAAUACAGGAAGAGGACAUUGCAUUGAAGGUUCUUCACGGGGACCAAUGAAGCUUAUUGGAAUGCACCACAGUGAGAUGGUUCUUGACACCAAUCUUUGCCCCAAAGAAAAGAACUAUGAGUGGUCCUUUAUCCAGUGUCCAGCUUGCCAGUGUAAUGGACAUAGCACUUGCAUCAAUAAUAAUGUGUGCGAACAGUGUAAAAAUCUCACCACAGGAAAGCAGUGUCAAGAUUGUAUGCCAGGUUAUUAUGGAGAUCCAACCAAUGGUGGACAGUGCACAGCUUGUACAUGCAGUGGCCAUGCAAAUAUCUGUCAUCUGCACACAGGAAAAUGUUUCUGCACAACUAAAGGAAUAAAAGGUGACCAAUGCCAAUUAUGUGACUCUGAAAAUCGCUAUGUUGGUAAUCCACUUAGAGGAACAUGUUAUUACAGCCUUUUGAUUGAUUAUCAAUUUACCUUCAGCUUAUUACAGGAAGAUGAUCGCCACCAUACUGCCAUAAACUUUAUAGCAAACCCAGAACAGUCGAACAAAAAUCUGGAUAUAUCAAUUAAUGCAUCAAACAACUUUAAUCUCAACAUUACGUGGUCUGUCGGUUCAACAGCUGGAACAAUAUCUGGGGAAGAGACUUCUAUAGUUUCCAAGAAUAAUAUAAAGGAAUACAGAGAUAGUUUUUCCUAUGAAAAAUUUAACUUUAGAAGCAAUCCUAACAUUACAUUCUAUGUGUACGUCAGCAACUUUUCCUGGCCUAUUAAAAUACAGAUUGCAUUCUCACAACACAAUACAAUCAUGGACCUUGUGCAGUUUUUUGUCACCUUCUUCAGUUGUUUCCUAUCCUUAUUGCUGGUGGCUGCUGUGGUAUGGAAGAUCAAACAAACUUGUUGGGCUUCUCGACGGAGAGAGCAACUGCUUCGAGAACGACAGCAGAUGGCCAGCCGUCCCUUUGCUUCUGUUGAUGUAGCUCUGGAAGUGGGAGCUGAACAAACAGAGUUUCUGCGAGGGCCAUUAGAGGGGGCACCCAAGCCAAUUGCCAUUGAACCAUGUGCUGGGAACAGAGCUGCUGUUCUGACUGUGUUUCUUUGUCUACCACGAGGAUCAUCAGGUGCCCCUCCCCCUGGGCAGUCAGGCCUUGCAAUUGCCAGUGCCCUAAUAGAUAUUUCACAACAGAAAGCUUCAGAUAGUAAAGAUAAGACUUCUGGAGUCCGGAAUCGAAAACACCUUUCAACACGUCAAGGAACUUGUGUCUGAGAAAUGGAAACCGCUCCUGUAUAUUCUGUACUGUUUUACUUCGGGCUUCUGUUAAAGCUGUUCUAUGGCCUUGGAUUUUAUGGAGGCAGAUCUCUGUAUCAUCCAGAGCCUGAGUACAGUUUCCUUCCAAAUGGACAAUGACCCAGGUGGCCAAAGAAUGUUCAUGAGUUUUAUAAAAGUAUUGAUGGUCACAGGUGAUAAAGUCAGUUUUUACCACUAUCUUAGGCUUAUUAUAGCUAACAUUAAAUUACUCUGGAAAAAGAUGUAUAUUGUUUCUUAAUGAAGAUGAAAAAUAUGUAAUUCAUAUAAAUCAACUGUUUAUAUCCCAAGACUUGAAAGAAAGACAUUUUUUAAUGCCUGAAUGAUGAGAAUUGUACAGUUUUUGCCUCAUAAGCAAACUUGAAUCACCUGUGUAUGAACAGGGAAUGAACACAUUGCAAUGGCUUUAAAUGCUCUUUUAUCUCGUUGUAAAGGUAAGGCAAGAUUUUGAUGUAGUAGGAUGUAGGUAAUGUAUUUAAAUAUUUCAUAUGACCAUAUCGUGUCCAAACUCAGUCUGAGAAUGUGACAGCUUUCCGCCUAACUAGAAUGCAGACCAGAAUGAGUUCAACUCAUUCUGUGCAACUUCACAGGGGGUUUAUUAGAAUGCUCAGUGUAGAGGACAUUCCUGUCAUCCAUGCCAACUACCUAACUCGUUAUCAGAGCUGAUAGAGCAUGGAAAAGUCUGUCCAGCGAUCAGUUGUUCCCCUCCUUCCAAAAACAGCCUCCAAUACCACAACCUGAAAAGAGCCGAAAUGGUUAUUUUACAGCAUACAAGCUUCUGCUCCAGUAUGAUAAUUUUUAAUUGCCUAAGAAUCAUUGGAUCAGACCUAAAUGAUCCAUCUGCAUUUUUAUAAGAAUGGAUCUUUCUUUGCCCUUCCUCUCCUAGCUGCUAGAUUUUAACUACCUUUUACAAAUGUUACAAAAUGUAUUUUAGAGGCGACAUCUCUCAAGAUGACCUGAGUUCCUUCCUGCCAACUGUUCCACCUAGAAUACAAGUAGAGAAGAGCACUGGCUGGCAAGCAUCAACAGGAGUCUUCUUCCCAACACGAGCGCAUCCAUGUCCUGAGAAAAAGUCUGUGGUUUAGAAAAUAUGUCCAUGGUUGCCCACAGUCAGCACACUCUUAGUGACUCAAAAUUCUGAAUUAUGGCAGAAAGGAAAAAUAAAACAUACUUCACAUUAGAACACAGAAUCAUUUACAUCCUAAUACUGACCACAGUUCACUAAAGCUCAGUAGCAUUAACAGAUAUAGUUUGGAAUUGCAGUUUCCUCACUUCAGGGUGACAAGAUAUGUAUAACAGUGACAGAAAUCUCCAAAGCUGCUGUAUAUGAUAUAGCUUUGUUAAAUAUGAAGGUCCUUUAAAUACAAUUGAUGUUUAGUACUAUAUAUGUACUUUUCACAUUCUUUGGAUUUCUGGAAGGUUAUGACACUUUACUGUUUACAGCUAAUGCAUAGUUACUUGCAUGCCAUGGUUGUACAGUAGCAGACUAUGACCCUAUUGUGAUAUUAAGUGUUUAUUUCAUAAUGCCAUUUAUACAUAGCUGAAUUUGAUGAGGAUUGAAUGUCAUAUAUAAGAGGAAUGAUCAUACAAUAUGUAGUUGCAUCUUAUAUAAGAUUUCUAGGUUGCAUCUAACCAUGACUAUGUCAUUAUUUUGAUAAUUAGGCAUUUAUGAAUUAUAGUAUAUAUUCCUCAUGUUGGCAUGAUAAUUUUGCUAUUUUCCAUGCAUUAAAAAUAAGACAAAUUCUUAGAGUAAUUUUAGUAAUUUUAUCUAUAAUCUGUGGGGUUUUUUUGGAGGGGGAGGCCACUGGUUGUUUCUACUUCCCUGUGAUAUUUUCUCUCUCAUUAAAGGAAUGAGCUAAGUUUGUAAAUAUCUCCUAAAAACAAUCAAGUAAUUUUAUUAGCUUCUUUUGGACCCUCUAAAUAUUGACUUCUCUCAUGAAAAAAUAAAUUGAUGAAACUAAUGAUUACAAAGAUAUAAUCAUUUUUUAAAAAGUGAUUGCCCAAUGUAUUUCUCUAACAAUUGUCACAAGAGAAAGCAUAACAAUAAAAAUACAAAAACAUACAGAUUUAGAUGUAAAAUCUAUAUAAGCUAUAUUUUUAGGGAGGCUAAGCAGAUAGUAUUACUGUGGAAGAAUUAUCAAGUUUUAUUCACCUCAAAUCCCACUGGGUUCUUAAAACUUGAAAAUUCAAAUUGUAGAGAAUUAUGAGACACAAUGUGAUGUUUAGUUAAAGUCAUGCUAUACCUUUCUGGGCCACAUAUUGCUAACUCUGUGGCUAAUUAUGCAAUUAAUUCUCAACGUAUCAAAGCUUUUCACUGGCAGUAAAUUCUUUGCCCUCAGGUGAAGUGGAUUGAAAAGACAUCAAGGAUCAAGGAUAAUCACUUUGAAUCUGUUGGUUUUUCCCCCUACAUUCCAGACACUUUAAAUUUGGAUGCUUUCAUUUUUUUUAAAUCAAACCACACAAAUAUGCAGAUACUUUCCCAGAAUUUCGCAGUUAAAUGGCUGAUCCUCUUGAAAACUAACCUUAAUGGAAUUCUAAACAUUUCAGUUUAGAAUGACUUUGAAAAAUUCCUUAGAUUUUUAGGAUGUUUUAUUCUGCCAAGUAUGAAAAAAAAAUGGUUAAAUACAAUGGAGUUUUAAAAAUUAACCUGGGGAUUCUAUUUGAACUAGAAAAUUCCUAUUGGAAAAGAAUUUGCACAUACUUACAGAUUCAGCUAAUAAAUUUUAAGAGGAUUAGGAUUCUCAUAAUUCUUUAAAUGAAAAUUUGUUUUAGUGAUACACAGAGAUGCCGUAUACUAUAGUGUUAUGUUCAGUAGGAAAACUUCAAAUAGUUCGUAUUUAAAAAGGUAAUUGAUCCUUGCUGUACUUCCCAACAUCUCAUCUUCUUUUAGCUGCAGUAAGAUAGAGGUGACUGUAUGGCUACAGUUCAUGGUAUAAGGUCAUUUAGGGUGCACACUGGCACACAGGCUGGAAAACGGGCACUGGACCCAGCUUUCAGGUGUGUGGUGCUGGGUAAGUUUCACCUUUGAAGCCUCAGCCUUCCAUCUGUAAAGGGCGGUAAUGGUGCCCACCUUUCGAGGCAUUGCGAGGCUAGAUGGUAACACACAGAAAGCUCCCACAGUGGGACCUUGAUGCAGCGUAGCUGGUAUUAACAACCGUGGGGACACCAGGCCACUCUUUUUCUACCAGUUGUUUUAUGAAUCCACCUAUUAAUUUUCAUCCAUCUUUUGGUCGUAGGUAAAGGUCAAUCAGGUUUUUCAAAAAGACUCCCUGAAUAACUUAAGUUCCUGUAUUUCUAAGAUAUAGGGAUUUCUACAAAACGACUUUGACAUUUAGUCAAUAAAGACUUAAACUCUUCUUAAAUCUAUAGUUUUAGGAGAGUUUUUCUUAAAAUUACUGACUGAUGACAUUGAGACAAGAGCAUCAAUGAUCACCUUUCACGUACAAACUAGGCAAGACAGGGUCAGUGCUUACAUUUUGUGGUUAUACAUGAUACAUCUUUUCUCAGUGAACAUAAAACUAUGAUUUGAAAGGUGUCUUAUAUUUAAAAAAGAUUGUAAAAUGAAAACUGACCAAAUGAACUAAUUCUACCCACCUAUGGUCUUUUUAAAUGUCGAGUUUCAAAACCCAUUUGCCGUAUACUAGAGUGAGCUUGGAAACUUACCUGAUUACAGGAAUUGCUUGGGUUCAGGCAGAUUCCCACUUUCACCUCUAGAGAUUUAGAUUCAGAAACACUGGGGUAGGCCCUGGAGAGCAGUACUCUUAACAAGCUCCUCAGUGCUUCUUACCAUUAGGCAAAUUAGGGAAACACUGCAUUGGGUCAAAGUGCUGCCUUUAAUCGACCAUUAGAGGGAGUUCUCUAAAUAACAAAGUUAUUACUCUAAUUCAAAAUGCUUUAAAGAAUUUUCCAAGGAAUACAAGCCAUCUGGUUGGUGUUAGUUAUAGCAGUGAUUUCAUUAGAGUGUACAUUUAACAUUUUAGUUUUAUCAAAAUUUUUUGAAAUUAAGAAUUAGAACCAGAGCUCCUAUCAGUAUAUAUGUACACAGGUGUGCAUGCCAGUGUUCAAAAGAUUGUGUAAAAGUUCAAGCCCGUUUUAGAAAGCCAACAUUUUAUGUUAUAAUAUGCUGUUAAUCAGGACUUUAUUAAAUAAAAACAUUGGCUCUUCCAACCCCCACUGCCAAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 26033)
attractin like 1
strand +
KIAA0534, FLJ45344, ALP
NCBI CDS gene sequence (4140 bp)
5'-ATGGAGACTGGGGGCCGGGCCCGCACTGGTACCCCGCAGCCAGCGGCCCCGGGGGTGTGGAGGGCTCGGCCGGCGGGCGGCGGCGGCGGGGGCGCCTCCTCCTGGCTGCTGGACGGGAACAGCTGGCTGCTGTGCTATGGCTTCCTCTACCTGGCGCTCTACGCGCAGGTGTCCCAGTCCAAGCCGTGCGAGAGGACCGGCTCCTGCTTCTCGGGCCGCTGTGTCAACTCCACCTGCCTCTGCGACCCGGGCTGGGTGGGGGACCAGTGCCAGCACTGCCAGGGCAGGTTCAAGTTAACAGAACCTTCTGGATATTTAACAGATGGCCCAATTAACTATAAATATAAAACTAAATGTACTTGGCTCATTGAAGGCTATCCAAATGCAGTGTTAAGATTAAGATTCAATCATTTTGCTACAGAATGTAGCTGGGATCATATGTATGTTTATGATGGAGATTCAATATATGCACCTTTAATAGCTGTACTTAGTGGTTTGATAGTCCCTGAAATAAGGGGCAATGAAACTGTGCCTGAAGTTGTTACTACATCTGGCTATGCACTGTTACATTTTTTTAGTGATGCTGCGTATAATCTAACTGGTTTCAACATTTTCTATTCAATCAATTCTTGTCCTAACAATTGCTCTGGTCATGGGAAGTGTACAACTAGTGTCTCTGTTCCAAGTCAAGTATATTGTGAATGTGATAAATACTGGAAGGGTGAAGCTTGTGATATTCCTTACTGTAAAGCCAATTGCGGCAGTCCAGATCACGGTTACTGTGACCTGACTGGAGAAAAATTATGTGTCTGCAATGATAGTTGGCAAGGTCCTGATTGTTCTTTGAATGTTCCCTCTACTGAGTCTTACTGGATTCTGCCAAACGTTAAACCCTTCAGTCCTTCTGTAGGTCGGGCTTCACATAAAGCAGTTTTACACGGGAAATTTATGTGGGTGATTGGTGGATATACTTTTAACTACAGTTCTTTTCAAATGGTCCTAAATTACAATTTAGAAAGCAGTATATGGAATGTAGGAACTCCATCAAGGGGACCTCTCCAGAGATATGGACACTCTCTTGCTTTATATCAGGAAAACATCTTTATGTATGGAGGCAGAATTGAAACAAATGATGGCAATGTCACAGATGAATTATGGGTTTTTAACATACATAGTCAGTCATGGAGTACAAAAACTCCTACTGTTCTTGGACATGGTCAGCAGTATGCTGTGGAGGGACATTCAGCACATATTATGGAGTTGGATAGTAGAGATGTTGTCATGATCATAATATTTGGATATTCTGCAATATATGGTTATACAAGCAGCATACAGGAATACCATATCTCATCAAACACTTGGCTTGTTCCAGAAACTAAAGGAGCTATTGTACAAGGTGGATATGGCCATACTAGTGTGTATGATGAAATAACAAAGTCCATTTATGTTCATGGAGGGTATAAAGCATTGCCAGGGAACAAATATGGATTGGTTGATGATCTTTATAAATATGAAGTTAACACTAAGACTTGGACTATTTTGAAAGAAAGTGGGTTTGCCAGATACCTTCATTCAGCTGTTCTTATCAATGGAGCTATGCTTATTTTTGGAGGAAATACCCATAATGACACTTCCTTGAGTAACGGTGCAAAATGTTTTTCTGCCGATTTCCTGGCATATGACATAGCTTGTGATGAATGGAAAATACTACCAAAACCAAATCTTCATAGAGATGTCAACAGATTTGGACACTCTGCAGTAGTCATTAACGGGTCCATGTATATATTTGGGGGATTTTCTAGTGTACTCCTTAATGATATCCTTGTATACAAGCCTCCAAATTGCAAGGCTTTCAGAGATGAAGAACTTTGTAAAAATGCTGGTCCAGGGATAAAATGTGTTTGGAATAAAAATCACTGTGAATCTTGGGAATCTGGGAATACTAATAATATTCTTAGAGCAAAGTGCCCTCCTAAAACAGCTGCTTCTGATGACAGATGTTACAGATATGCAGATTGTGCCAGCTGTACTGCCAATACAAATGGGTGCCAATGGTGTGATGACAAGAAATGCATTTCGGCAAATAGTAACTGCAGTATGTCTGTCAAGAACTACACCAAATGTCATGTGAGAAATGAGCAGATTTGTAACAAACTTACCAGCTGTAAAAGCTGTTCACTAAACTTGAATTGCCAGTGGGATCAGAGACAGCAAGAATGCCAGGCTTTACCAGCTCATCTTTGTGGAGAAGGATGGAGTCATATTGGGGATGCTTGTCTTAGAGTCAATTCCAGTAGAGAAAACTATGACAATGCAAAACTTTATTGCTATAATCTTAGTGGAAATCTTGCTTCATTAACAACCTCAAAAGAAGTAGAATTTGTTCTGGATGAAATACAGAAGTATACACAACAGAAAGTATCACCTTGGGTAGGCTTGCGCAAGATCAATATATCCTATTGGGGATGGGAAGACATGTCTCCTTTTACAAACACAACACTACAGTGGCTTCCTGGCGAACCCAATGATTCTGGGTTTTGTGCATATCTGGAAAGGGCTGCAGTGGCAGGCTTAAAAGCTAATCCTTGTACATCTATGGCAAATGGCCTTGTCTGTGAAAAACCTGTTGTTAGTCCAAATCAAAATGCGAGGCCGTGCAAAAAGCCATGCTCTCTGAGGACATCATGTTCCAACTGTACAAGCAATGGCATGGAGTGTATGTGGTGCAGCAGTACGAAACGATGTGTTGACTCTAATGCCTATATCATCTCTTTTCCATATGGACAATGTCTAGAGTGGCAAACTGCCACCTGCTCCCCTCAAAATTGTTCTGGATTGAGAACCTGTGGACAGTGTTTGGAACAGCCTGGATGTGGCTGGTGCAATGATCCTAGTAATACAGGAAGAGGACATTGCATTGAAGGTTCTTCACGGGGACCAATGAAGCTTATTGGAATGCACCACAGTGAGATGGTTCTTGACACCAATCTTTGCCCCAAAGAAAAGAACTATGAGTGGTCCTTTATCCAGTGTCCAGCTTGCCAGTGTAATGGACATAGCACTTGCATCAATAATAATGTGTGCGAACAGTGTAAAAATCTCACCACAGGAAAGCAGTGTCAAGATTGTATGCCAGGTTATTATGGAGATCCAACCAATGGTGGACAGTGCACAGCTTGTACATGCAGTGGCCATGCAAATATCTGTCATCTGCACACAGGAAAATGTTTCTGCACAACTAAAGGAATAAAAGGTGACCAATGCCAATTATGTGACTCTGAAAATCGCTATGTTGGTAATCCACTTAGAGGAACATGTTATTACAGCCTTTTGATTGATTATCAATTTACCTTCAGCTTATTACAGGAAGATGATCGCCACCATACTGCCATAAACTTTATAGCAAACCCAGAACAGTCGAACAAAAATCTGGATATATCAATTAATGCATCAAACAACTTTAATCTCAACATTACGTGGTCTGTCGGTTCAACAGCTGGAACAATATCTGGGGAAGAGACTTCTATAGTTTCCAAGAATAATATAAAGGAATACAGAGATAGTTTTTCCTATGAAAAATTTAACTTTAGAAGCAATCCTAACATTACATTCTATGTGTACGTCAGCAACTTTTCCTGGCCTATTAAAATACAGATTGCATTCTCACAACACAATACAATCATGGACCTTGTGCAGTTTTTTGTCACCTTCTTCAGTTGTTTCCTATCCTTATTGCTGGTGGCTGCTGTGGTATGGAAGATCAAACAAACTTGTTGGGCTTCTCGACGGAGAGAGCAACTGCTTCGAGAACGACAGCAGATGGCCAGCCGTCCCTTTGCTTCTGTTGATGTAGCTCTGGAAGTGGGAGCTGAACAAACAGAGTTTCTGCGAGGGCCATTAGAGGGGGCACCCAAGCCAATTGCCATTGAACCATGTGCTGGGAACAGAGCTGCTGTTCTGACTGTGTTTCTTTGTCTACCACGAGGATCATCAGGTGCCCCTCCCCCTGGGCAGTCAGGCCTTGCAATTGCCAGTGCCCTAATAGATATTTCACAACAGAAAGCTTCAGATAGTAAAGATAAGACTTCTGGAGTCCGGAATCGAAAACACCTTTCAACACGTCAAGGAACTTGTGTCTGA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.