NCBI Summary
This gene encodes both membrane-bound and secreted protein isoforms. A membrane-bound isoform exhibits sequence similarity with the mouse mahogany protein, a receptor involved in controlling obesity. A secreted isoform is involved in the initial immune cell clustering during inflammatory responses that may regulate the chemotactic activity of chemokines. [provided by RefSeq, Apr 2016].
Protein
Protein (NP_647537)
Attractin
Attractin (DPPT-L) (Mahogany homolog)
ATRN
attractin
Undefined
Very low evidence
C-type lectin
Undefined
C-type - Attractin
a/b mixed / C-type lectin-like
MVAAAAATEARLRRRTAATAALAGRSGGPHWDWDVTRAGRPGLGAGLRLPRLLSPPLRPRLLLLLLLLSPPLLLLLLPCEAEAAAAAAAVSGSAAAEAKECDRPCVNGGRCNPGTGQCVCPAGWVGEQCQHCGGRFRLTGSSGFVTDGPGNYKYKTKCTWLIEGQPNRIMRLRFNHFATECSWDHLYVYDGDSIYAPLVAAFSGLIVPERDGNETVPEVVATSGYALLHFFSDAAYNLTGFNITYSFDMCPNNCSGRGECKISNSSDTVECECSENWKGEACDIPHCTDNCGFPHRGICNSSDVRGCSCFSDWQGPGCSVPVPANQSFWTREEYSNLKLPRASHKAVVNGNIMWVVGGYMFNHSDYNMVLAYDLASREWLPLNRSVNNVVVRYGHSLALYKDKIYMYGGKIDSTGNVTNELRVFHIHNESWVLLTPKAKEQYAVVGHSAHIVTLKNGRVVMLVIFGHCPLYGYISNVQEYDLDKNTWSILHTQGALVQGGYGHSSVYDHRTRALYVHGGYKAFSANKYRLADDLYRYDVDTQMWTILKDSRFFRYLHTAVIVSGTMLVFGGNTHNDTSMSHGAKCFSSDFMAYDIACDRWSVLPRPDLHHDVNRFGHSAVLHNSTMYVFGGFNSLLLSDILVFTSEQCDAHRSEAACLAAGPGIRCVWNTGSSQCISWALATDEQEEKLKSECFSKRTLDHDRCDQHTDCYSCTANTNDCHWCNDHCVPRNHSCSEGQISIFRYENCPKDNPMYYCNKKTSCRSCALDQNCQWEPRNQECIALPENICGIGWHLVGNSCLKITTAKENYDNAKLFCRNHNALLASLTTQKKVEFVLKQLRIMQSSQSMSKLTLTPWVGLRKINVSYWCWEDMSPFTNSLLQWMPSEPSDAGFCGILSEPSTRGLKAATCINPLNGSVCERPANHSAKQCRTPCALRTACGDCTSGSSECMWCSNMKQCVDSNAYVASFPFGQCMEWYTMSTCPPENCSGYCTCSHCLEQPGCGWCTDPSNTGKGKCIEGSYKGPVKMPSQAPTGNFYPQPLLNSSMCLEDSRYNWSFIHCPACQCNGHSKCINQSICEKCENLTTGKHCETCISGFYGDPTNGGKCQPCKCNGHASLCNTNTGKCFCTTKGVKGDECQLCEVENRYQGNPLRGTCYYTLLIDYQFTFSLSQEDDRYYTAINFVATPDEQNRDLDMFINASKNFNLNITWAASFSAGTQAGEEMPVVSKTNIKEYKDSFSNEKFDFRNHPNITFFVYVSNFTWPIKIQIAFSQHSNFMDLVQFFVTFFSCFLSLLLVAAVVWKIKQSCWASRRREQLLREMQQMASRPFASVNVALETDEEPPDLIGGSIKTVPKPIALEPCFGNKAAVLSVFVRLPRGLGGIPPPGQSGLAVASALVDISQQMPIVYKEKSGAVRNRKQQPPAQPGTCI
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
The location of the lectin domain structural model is: 782-959
We infer [ err > 2 Å] as the interval of error of this structural model.
Template 1: 1G1T chain: A, P16581, NP_000441.2, sequence identity: 18.5%, coverage: 80.3%, location in sequence: 22-176, (1-155 in PDB).
Template 2: 5B1X chain: A, Q9UMR7, NP_057268.1, sequence identity: 19.1%, coverage: 70.2%, location in sequence: 105-234, (105-234 in PDB).
Template 3: 5VC1 chain: A, P14151, NP_000646.3, sequence identity: 19.1%, coverage: 79.2%, location in sequence: 39-191, (1-153 in PDB).
Show the alignment used for the construction of the structural model, Download.
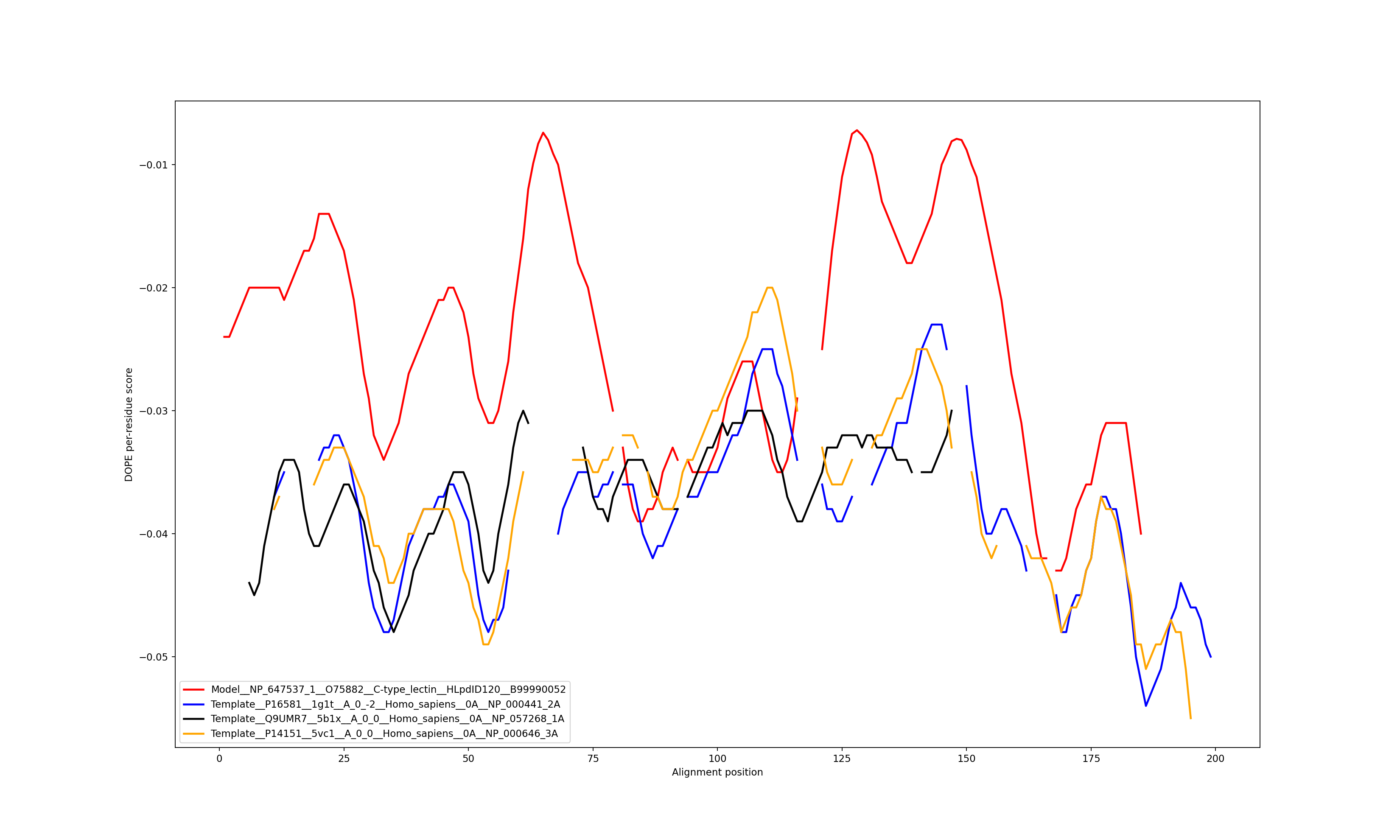
Show the plot of DOPE energy score, Download.
We infer [ err > 2 Å] as the interval of error of this structural model.
Template 1: 1G1T chain: A, P16581, NP_000441.2, sequence identity: 18.5%, coverage: 80.3%, location in sequence: 22-176, (1-155 in PDB).
Template 2: 5B1X chain: A, Q9UMR7, NP_057268.1, sequence identity: 19.1%, coverage: 70.2%, location in sequence: 105-234, (105-234 in PDB).
Template 3: 5VC1 chain: A, P14151, NP_000646.3, sequence identity: 19.1%, coverage: 79.2%, location in sequence: 39-191, (1-153 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
Monomer and homotrimer
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- Hypomyelinating leukodystrophy associated with a deleterious mutation in the ATRN gene. [28493104]
- Expression of Attractin in male reproductive tract of human and mice and its correlation with male reproduction. [25318887]
- Dipeptidyl-peptidase 4 and attractin expression is increased in circulating blood monocytes of obese human subjects. [20198559]
- Novel partners of SPAG11B isoform D in the human male reproductive tract. [19535787]
- Genetic variants in pigmentation genes, pigmentary phenotypes, and risk of skin cancer in Caucasians. [19384953]
- The DNA sequence and comparative analysis of human chromosome 20. [11780052]
- Secreted and membrane attractin result from alternative splicing of the human ATRN gene. [10811918]
- Attractin (DPPT-L), a member of the CUB family of cell adhesion and guidance proteins, is secreted by activated human T lymphocytes and modulates immune cell interactions. [9736737]
- Serum high molecular weight dipeptidyl peptidase IV (CD26) is similar to a novel antigen DPPT-L released from activated T cells. [8596018]
- [Topical timolol and blood-aqueous barrier permeability to protein in human eyes]. [1476071]
UniProt Main References (9 PubMed Identifiers)
- Complete sequencing and characterization of 21,243 full-length human cDNAs. [14702039]
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
- A novel form of dipeptidylpeptidase IV found in human serum. Isolation, characterization, and comparison with T lymphocyte membrane dipeptidylpeptidase IV (CD26). [7539799]
- Prediction of the coding sequences of unidentified human genes. IX. The complete sequences of 100 new cDNA clones from brain which can code for large proteins in vitro. [9628581]
- Does human attractin have DP4 activity? [17261078]
- Screening for N-glycosylated proteins by liquid chromatography mass spectrometry. [14760718]
- Human plasma N-glycoproteome analysis by immunoaffinity subtraction, hydrazide chemistry, and mass spectrometry. [16335952]
- Glycoproteomics analysis of human liver tissue by combination of multiple enzyme digestion and hydrazide chemistry. [19159218]
- A strategy for precise and large scale identification of core fucosylated glycoproteins. [19139490]
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_139321.3)
m7G-5')ppp(5'-ACAGCCCCGCCCCGCACGGCCAGGCGAAGCGGAGCCGGCCGUGCGGUGUGUGUGUAUGUGUUCGCGGGGCGCCGUCUCAGCCCCGGGAAGAUGGUGGCUGCAGCGGCGGCAACUGAGGCAAGGCUGAGGAGGAGGACGGCGGCGACGGCAGCGCUCGCGGGCAGGAGCGGCGGGCCGCACUGGGACUGGGACGUGACCAGGGCUGGGAGGCCGGGGCUGGGGGCCGGGCUGCGCCUCCCGCGGCUGCUGUCUCCACCGCUGCGGCCACGGCUGCUGCUGCUGCUGUUGUUGCUCUCGCCGCCGCUGCUGCUGCUGCUGCUGCCCUGUGAGGCCGAGGCCGCGGCGGCGGCGGCGGCGGUGUCGGGCUCAGCCGCAGCCGAGGCCAAGGAAUGUGACCGGCCCUGUGUCAACGGCGGUCGCUGCAACCCUGGCACCGGCCAGUGCGUCUGCCCCGCCGGCUGGGUGGGCGAGCAAUGCCAGCACUGCGGGGGCCGCUUCAGACUAACUGGAUCUUCUGGGUUUGUGACAGAUGGACCUGGAAAUUAUAAAUACAAAACGAAGUGCACGUGGCUCAUUGAAGGACAGCCAAAUAGAAUAAUGAGACUUCGUUUCAAUCAUUUUGCUACAGAGUGUAGUUGGGACCAUUUAUAUGUUUAUGAUGGGGACUCAAUUUAUGCACCGCUAGUUGCUGCAUUUAGUGGCCUCAUUGUUCCUGAGAGAGAUGGCAAUGAGACUGUCCCUGAGGUUGUUGCCACAUCAGGUUAUGCCUUGCUGCAUUUUUUUAGUGAUGCUGCUUAUAAUUUGACUGGAUUUAAUAUUACUUACAGUUUUGAUAUGUGUCCAAAUAACUGCUCAGGCCGAGGAGAGUGUAAGAUCAGUAAUAGCAGCGAUACUGUUGAAUGUGAAUGUUCUGAAAACUGGAAAGGUGAAGCAUGUGACAUUCCUCACUGUACAGACAACUGUGGUUUUCCUCAUCGAGGCAUCUGCAAUUCAAGUGAUGUCAGAGGAUGCUCCUGCUUCUCAGACUGGCAGGGUCCUGGAUGUUCAGUUCCUGUACCAGCUAACCAGUCAUUUUGGACUCGAGAGGAAUAUUCUAACUUAAAGCUCCCCAGAGCAUCUCAUAAAGCUGUGGUCAAUGGAAACAUUAUGUGGGUUGUUGGAGGAUAUAUGUUCAACCACUCAGAUUAUAACAUGGUUCUAGCGUAUGACCUUGCUUCUAGGGAGUGGCUUCCACUAAACCGUUCUGUGAACAAUGUGGUUGUUAGAUAUGGUCAUUCUUUGGCAUUAUACAAGGAUAAAAUUUACAUGUAUGGAGGAAAAAUUGAUUCAACUGGGAAUGUGACCAAUGAGUUGAGAGUUUUUCACAUUCAUAAUGAGUCAUGGGUGUUGUUGACCCCUAAGGCAAAGGAGCAGUAUGCAGUGGUUGGGCACUCUGCACACAUUGUUACACUGAAGAAUGGCCGAGUGGUCAUGCUGGUCAUCUUUGGUCACUGCCCUCUCUAUGGAUAUAUAAGCAAUGUGCAGGAAUAUGAUUUGGAUAAGAACACAUGGAGUAUAUUACACACCCAGGGUGCCCUUGUGCAAGGGGGUUACGGCCAUAGCAGUGUUUACGACCAUAGGACCAGGGCCCUAUACGUUCAUGGUGGCUACAAGGCUUUCAGUGCCAAUAAGUACCGGCUUGCAGAUGAUCUCUACCGAUAUGAUGUGGAUACCCAGAUGUGGACCAUUCUUAAGGACAGCCGAUUUUUCCGUUACUUGCACACAGCUGUGAUAGUGAGUGGAACCAUGCUGGUGUUUGGAGGAAACACACACAAUGACACAUCUAUGAGCCAUGGCGCCAAAUGCUUCUCUUCAGAUUUCAUGGCCUAUGACAUUGCCUGUGACCGCUGGUCAGUGCUUCCCAGACCUGAUCUCCACCAUGAUGUCAACAGAUUUGGCCAUUCAGCAGUCUUACACAACAGCACCAUGUAUGUGUUCGGUGGUUUCAAUAGUCUCCUCCUCAGCGACAUCCUGGUAUUCACCUCGGAACAGUGUGAUGCGCAUCGGAGUGAAGCCGCUUGUUUAGCAGCAGGACCUGGUAUUCGGUGUGUGUGGAACACAGGGUCGUCUCAGUGUAUCUCGUGGGCGCUGGCAACUGAUGAACAAGAAGAAAAGUUAAAAUCAGAAUGUUUUUCCAAAAGAACUCUUGACCAUGACAGAUGUGACCAGCACACAGAUUGUUACAGCUGCACAGCCAACACCAAUGACUGCCACUGGUGCAAUGACCAUUGUGUCCCCAGGAACCACAGCUGCUCAGAAGGCCAGAUCUCCAUUUUUAGGUAUGAGAAUUGCCCCAAGGAUAACCCCAUGUACUACUGUAACAAGAAGACCAGCUGCAGGAGCUGUGCCCUGGACCAGAACUGCCAGUGGGAGCCCCGGAAUCAGGAGUGCAUUGCCCUGCCCGAAAAUAUCUGUGGCAUUGGCUGGCAUUUGGUUGGAAACUCAUGUUUGAAAAUUACUACUGCCAAGGAGAAUUAUGACAAUGCUAAAUUGUUCUGUAGGAACCACAAUGCCCUUUUGGCUUCUCUUACAACCCAGAAGAAGGUAGAAUUUGUCCUUAAGCAGCUGCGAAUAAUGCAGUCAUCUCAGAGCAUGUCCAAGCUCACCUUAACCCCAUGGGUCGGCCUUCGGAAGAUCAAUGUGUCCUACUGGUGCUGGGAAGAUAUGUCCCCAUUUACAAAUAGUUUACUACAGUGGAUGCCGUCUGAGCCCAGUGAUGCUGGAUUCUGUGGAAUUUUAUCAGAACCCAGUACUCGGGGACUGAAGGCUGCAACCUGCAUCAACCCACUCAAUGGUAGUGUCUGUGAAAGGCCUGCAAACCACAGUGCUAAGCAGUGCCGGACACCAUGUGCCUUGAGGACAGCAUGUGGAGAUUGCACCAGCGGCAGCUCUGAGUGCAUGUGGUGCAGCAACAUGAAGCAGUGUGUGGACUCCAAUGCCUACGUGGCCUCCUUCCCUUUUGGCCAGUGUAUGGAAUGGUAUACGAUGAGCACCUGCCCCCCUGAAAAUUGUUCAGGCUACUGUACCUGUAGUCAUUGCUUGGAGCAACCAGGCUGUGGCUGGUGUACUGAUCCCAGCAAUACUGGCAAAGGGAAAUGCAUAGAGGGUUCCUAUAAAGGACCAGUGAAGAUGCCUUCGCAAGCCCCUACAGGAAAUUUCUAUCCACAGCCCCUGCUCAAUUCCAGCAUGUGUCUAGAGGACAGCAGAUACAACUGGUCUUUCAUUCACUGUCCAGCUUGCCAAUGCAACGGCCACAGUAAAUGCAUCAAUCAGAGCAUCUGUGAGAAGUGUGAGAACCUGACCACAGGCAAGCACUGCGAGACCUGCAUAUCUGGCUUCUACGGUGAUCCCACCAAUGGAGGGAAAUGUCAGCCAUGCAAGUGCAAUGGGCACGCGUCUCUGUGCAACACCAACACGGGCAAGUGCUUCUGCACCACCAAGGGCGUCAAGGGGGACGAGUGCCAGCUAUGUGAGGUAGAAAAUCGAUACCAAGGAAACCCUCUCAGAGGAACAUGUUAUUAUACUCUUCUUAUUGACUAUCAGUUCACCUUUAGUCUAUCCCAGGAAGAUGAUCGCUAUUACACAGCUAUCAAUUUUGUGGCUACUCCUGACGAACAAAACAGGGAUUUGGACAUGUUCAUCAAUGCCUCCAAGAAUUUCAACCUCAACAUCACCUGGGCUGCCAGUUUCUCAGCUGGAACCCAGGCUGGAGAAGAGAUGCCUGUUGUUUCAAAAACCAACAUUAAGGAGUACAAAGAUAGUUUCUCUAAUGAGAAGUUUGAUUUUCGCAACCACCCAAAUAUCACUUUCUUUGUUUAUGUCAGUAAUUUCACCUGGCCCAUCAAAAUUCAGAUUGCCUUCUCUCAGCACAGCAAUUUUAUGGACCUGGUACAGUUCUUCGUGACUUUCUUCAGUUGUUUCCUCUCUUUGCUCCUGGUGGCUGCUGUGGUUUGGAAGAUCAAACAAAGUUGUUGGGCCUCCAGACGUAGAGAGCAACUUCUUCGAGAGAUGCAACAGAUGGCCAGCCGUCCCUUUGCCUCUGUAAAUGUCGCCUUGGAAACAGAUGAGGAGCCUCCUGAUCUUAUUGGGGGGAGUAUAAAGACUGUUCCCAAACCCAUUGCACUGGAGCCGUGUUUUGGCAACAAAGCCGCUGUCCUCUCUGUGUUUGUGAGGCUCCCUCGAGGCCUGGGUGGCAUCCCUCCUCCUGGGCAGUCAGGUCUUGCUGUGGCCAGCGCCCUGGUGGACAUUUCUCAGCAGAUGCCGAUAGUGUACAAGGAGAAGUCAGGAGCCGUGAGAAACCGGAAGCAGCAGCCCCCUGCACAGCCUGGGACCUGCAUCUGAUGCUGGGGCCAGGGACUCUCCCACGCACGAGCUAGUGAGUGGCACACCAGAGCCAUCUGCAGGGAAGGGCGUGGCGGGGAAAUGGCUGUGCGGUGCGGGACGGAAGACUGGAAACCCUCAAAGCAUCUGACUCACCUGCAUGAUCACAAGCUUUCUUUGACGGUUUCUCCCAUCCGUGUUCCAGCAUCUAACCUUUUACUUUUGCAUAGGAAAUACUUGAUUUAAUUACAGGUCCAGGGAUGAGCUGAUGGUUGCUGGAGGAGGCCAGUGUAGAGCCAGUGAGAGAACUAGGAAUGACACUCAGGUUCACUGUGGAAAACUGUUCUUGGGACUGUCUCAACUGUGCAAAAAACAAAAGAUGGAGUGUUUACAAGUAGACAUUCGUCAUCAGUUGUUCUUGAACAUGGUCUUUUAAAAACUAGUCAGAUGAAUUGUUUUCAUCUGAAGCCUGCUAUCUUUUUUAAAAGAUGUGCUAUUUAUUCUUGCACGAUUUAGGCAAUUAUCUCUCUUCCAGGGAGUACCUUUUUUUCUAGUUGAGAAUUAAUAAUGGUCCAUCUCUUUUGAUCAUAUCAAGCUAGGAUAGAAGGGGGGCUAUUUUAAAUGUCAAGGUCAGCAGUGUUACUUUGAAUGUAAACUGGUAUAAUAGGUAGUUUUCUAUAGUAACUUGAUUAAUUUAGUCUUAAUCCAUUUGAAACUCUCUCUUCCUUUCUCUCUGCCUGUCCCUCUCCUUCUCCAUCUCACCCUCCCUCUCUCACACAUACACACACAAACACAUACACACAACACUAAGUGCCUAGACUUUAAAUAGAUCUAGCAAUUGGAAAGUUAGUAAGCCUAAGUUUUUACAUAAUUGCAUUCCUACAUUCUUGUAAAAUUUAAAUAGCUACCAUUGGCAAUCUGCUUUUUUUCUAAAAUCUGAUUUGCAGCCAGGAAAGAAUUUUCUCACCCAAGGAACAUUUGAUCUAGCAGCAGGGAUGAGAGGAAAGCAGAAAUGAAUGAACUGUGAAAGCUCCUGUUUUUAUUAUCAAAAAGGACACUGUCAAGAAGGCGCCCCCUGCCCCCACCCCCGUGUCACCCUAGGCCUGAUAAGCGAUCAGAGGAAAGGACUCAUUCAUGUCACGCUUCCUUGAGCAGAAAAGAGCACUGAGAGCACUUGGGACCCCUGGAUCAGAGAGCAUCUGUGUGUCCUGCAGCCUCCUCUGAACUUGUGGUUCAUUCUCAGGCUGGGGUGGACUCAGAUGCCAGGAAAGGGACAGCCUCCCAUUGUCAGGCAGAAGCUGCCCAAAGCCUGGAGAAGGACUUGUUUGCCCUCUUUCCCCCAGGAGGGGCUCGACCCACCCACCCUCCCUCUCAGACCAAGGUGGUGGCUGUGAGGAGGGCAGCAAAUGCUGACAAGGAUGAAAAGCACAUGGAAAAAAAUGGAUGAGGAGGGAAAACUCUGCCAAAUGGAAAAUGACCAAAUUUAAGAGGGUGGGACAGUCCCCUGCUCCUCUCCCAGAGGGCACUGCUUGGAAAUUGUGUUUUCCCCAUUUAUGGUGCUCUGUAUUCUGGCAUUAUGCAGCAGCCUCCCAGAAGCUCUCUUCUGCUUCAAAACCUGGGAUCUCUGGCAUUACCCUAUUGGGAUGGACCGCUGGACAGCAAUGCUCGAGUUUGUGAAUUUGGAGAGAUACUCAAAAGAGCUAAAACUGCAGCAUUUUACCUUUAAAUGCAGUGCCUAGAGAGAGAGUAUUGUCUCUUCCCCAACACUAACCCCACUCCCAUGAAGAAUUGCCUGGAAAGAUGUUUUCAAGGAAUUUGAACCAUAAAACACUAUCUGAUGCACAGAACACCUCUACUUUGAGACUCACCUCUCAUAAAGCUUCUUUUUCACAUUACUGUUAAAGACCAGACGUUCUAGAAAAGACCCCUCCUCUCAUGAGCUCCCCCAUCCCUGCUACAGAACACAGCACCCAUGGCGCCUGCAGUGGACUGGCCCCUUAAUUCCCACAGGCCCCCCCAGCAAGGCCAAAGGGAGGCCCCUGGGUAUUGUCCUCCUACAAGGAAGAUCCUCUUUGUUUGUUCAAAGGACCAGUUUUCCUAGGCCAAAGAAGUCUCUUCCCCAUGUUAGUCCUAUGCCUUGAAAUAUCAUGCACCAUGACCCACAGCCAUCUGGUUAUGUCUUAUUUUUUUCCUAAAAGAUAAUGUUUAUUUUUAAAAAGGAAGGAAGGAGCAAGUGAAGUUUCAUUCUGCUCCAGCGGUGGGGAAGCCGCUGAAUCCACCUGCUUCUCCUUUGCAACCGACAGCAAACAGCUUUCUCCGGCCUCAGGGCAGAAAAAGGGAAUGGCAGGGAGUAAGAGGCGCUGGGCUCGGAGCCUGUUUCCAAGAAGGAAUUGGUUGUCAUCUGGCAGUGUUGCGCGUCACAAGAGAGCCUGUAUAUAAAUUAAAAUAGUCAAGACAACACUGACCUUGCACUUGUACAUAACUAUACAGUAGUGUCCAGAAUGUUCAGACAUUCGGAGUGUACAUAAAACAGAAAAAAUCUUCAUGUAUUUUUAUUAAAUAUAACAAUGUCUGAGUUUCACCUAAGAUGUUUUUGUGCCAUAUGCUGGAUAUCCAGGUUCUCGCCAGGCCCCGAUACAUGAAUAACAAACCCAAGAAACGCAUCCCCAUUGUGUGAUGUGUUCAGAUGCAUCUGGCACCAAUUAGGUAUUUCUUAAAACAGGACUCAUCUGUCAGAGUGCACAUGAAAAAUCAGGCAGGGAAUCGAAACGACAGUGCUGGAGGAGACUCAGGAAGCAGAGGCGUCCCUGCCGCUGCCCUUGGCCCUGCAAGCACAUCAUGACCCUUUCUGGCAGCCUCUUGGUGCUCUGGGUAGUGAGGGAUGACCAGUCUUGUCCUGAGAAAUGUUUCUCUUAGUCUUUAAGUUCAAAGACUAACCUGUAGCAAUCAGACUUUCCAAAAGGGGGUUCUCCAUUUUUUGUAGUUUUGUCUAAAUUUUUAAUGACCAUUUCCUGGAAUCAGUUUAUUAUACUGAAAACUGGGGGUGGGAGUAGGGAGCUAGUUUGUUGAUAAAUAGUUCCCAUUUCCCCAUGGAGAAUUUGACAUACCCUGGACUCCUGUGUGCCUCCUGCCAUCCCUGCACACAGCCUGGGGAGAAGCCUGUGCCUCCCCGUGUGGAGAGAAGGCAACCCCAGAUCCCCUGAGCUAACCCGGAGGAAAGGCAGUCCUGGACAGAAGACUGUCAGCAGAAGGAAAGUACUGGACUACCCGUGGGUAAGUCCUGCCAUUCAAGACUGGAGACACCUGGGAAAUAAAAAGAGCAGGGCACUGCUGGUGGGAAGAGGCAUUUUACCUUCCAGUGCAAAUCCUGCUCCUUUGAUUUAAUGGGGUGUACUGGGGCCAGGGGCUGAUUCACUUCCUUGGGAGAUGGUGGUGUUUUCAUGAACAUCUUUGAUCCUUCCAUUUCAUUUAUUCAUCCAUCCAUUCAACAAGUAUUUGCUAAACACUAACUUAAGCUAAUGCUAGGGUAGUGACUGAGAUGUAAAAAUAGAUUUUAGAAUUAAAACAAAAUCCAAGUCCUCACACCCCUGUCAUCCCAGGAGAUCUUUCCUUGUGGUGGUUUCUGUGAGAAUUGGCCAUCCUGAGGACACAGCCAGGACGGCAGAGGCCUCCUGGCCUCAGGGCAUGCCCUGCCUACCUUCUGAAAUGUUUACCCCAUUGACCAAACUUGGCUCCAGCCAUUGCGGUGGUUUCUAGAUAGCCAGGCCCACCAAGAGAUAUUGCCCCUUGAUGAGAGUCAAACACCCUGCCUACAAGGAGAUGUUUUGAAAUGGAGAGGAAAAUUGGCACCUCAUCUUUUAAAGGCAGUAAUGGAAUUGAUUUUCAGUAACUGAAUUUGUGCACAAAACAUUCUAAACACUAGUGAAGCCUGUUUCGUUGAACUAAUUCUGGCUCUGGAAAUGUUUUUGUUUUAUAGUUAUUUACGAUUUCGUUUGUUUGGAUUCAAGCUUAGUUUGUUAAUAUGUAUAAUUUAGCAUCUAUUACACUCAUGUAAAUAUGGAGUAAGUAUUGUAAACUAUUUCAUCGCGGGGAUUGUGGGUGUUAUACAUACAUUUAGGACUGCAAUUUUUUGGUAUUUUUUGUAUUGUAAAAUAACAGCUAAUUUAAGCAGGAACAAGAGAACUAAGGGAGGUCUGUGCAUUUUAAACACAAAUGUGAAGAACUUGUAUAUAAACAAAAGUAAAUACUAUAAUACAAACUUCCUUCUGAAAUAAAAGUAGAUCUGGUAAAAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 8455)
attractin
strand +
DPPT-L, MGCA
NCBI CDS gene sequence (4290 bp)
5'-ATGGTGGCTGCAGCGGCGGCAACTGAGGCAAGGCTGAGGAGGAGGACGGCGGCGACGGCAGCGCTCGCGGGCAGGAGCGGCGGGCCGCACTGGGACTGGGACGTGACCAGGGCTGGGAGGCCGGGGCTGGGGGCCGGGCTGCGCCTCCCGCGGCTGCTGTCTCCACCGCTGCGGCCACGGCTGCTGCTGCTGCTGTTGTTGCTCTCGCCGCCGCTGCTGCTGCTGCTGCTGCCCTGTGAGGCCGAGGCCGCGGCGGCGGCGGCGGCGGTGTCGGGCTCAGCCGCAGCCGAGGCCAAGGAATGTGACCGGCCCTGTGTCAACGGCGGTCGCTGCAACCCTGGCACCGGCCAGTGCGTCTGCCCCGCCGGCTGGGTGGGCGAGCAATGCCAGCACTGCGGGGGCCGCTTCAGACTAACTGGATCTTCTGGGTTTGTGACAGATGGACCTGGAAATTATAAATACAAAACGAAGTGCACGTGGCTCATTGAAGGACAGCCAAATAGAATAATGAGACTTCGTTTCAATCATTTTGCTACAGAGTGTAGTTGGGACCATTTATATGTTTATGATGGGGACTCAATTTATGCACCGCTAGTTGCTGCATTTAGTGGCCTCATTGTTCCTGAGAGAGATGGCAATGAGACTGTCCCTGAGGTTGTTGCCACATCAGGTTATGCCTTGCTGCATTTTTTTAGTGATGCTGCTTATAATTTGACTGGATTTAATATTACTTACAGTTTTGATATGTGTCCAAATAACTGCTCAGGCCGAGGAGAGTGTAAGATCAGTAATAGCAGCGATACTGTTGAATGTGAATGTTCTGAAAACTGGAAAGGTGAAGCATGTGACATTCCTCACTGTACAGACAACTGTGGTTTTCCTCATCGAGGCATCTGCAATTCAAGTGATGTCAGAGGATGCTCCTGCTTCTCAGACTGGCAGGGTCCTGGATGTTCAGTTCCTGTACCAGCTAACCAGTCATTTTGGACTCGAGAGGAATATTCTAACTTAAAGCTCCCCAGAGCATCTCATAAAGCTGTGGTCAATGGAAACATTATGTGGGTTGTTGGAGGATATATGTTCAACCACTCAGATTATAACATGGTTCTAGCGTATGACCTTGCTTCTAGGGAGTGGCTTCCACTAAACCGTTCTGTGAACAATGTGGTTGTTAGATATGGTCATTCTTTGGCATTATACAAGGATAAAATTTACATGTATGGAGGAAAAATTGATTCAACTGGGAATGTGACCAATGAGTTGAGAGTTTTTCACATTCATAATGAGTCATGGGTGTTGTTGACCCCTAAGGCAAAGGAGCAGTATGCAGTGGTTGGGCACTCTGCACACATTGTTACACTGAAGAATGGCCGAGTGGTCATGCTGGTCATCTTTGGTCACTGCCCTCTCTATGGATATATAAGCAATGTGCAGGAATATGATTTGGATAAGAACACATGGAGTATATTACACACCCAGGGTGCCCTTGTGCAAGGGGGTTACGGCCATAGCAGTGTTTACGACCATAGGACCAGGGCCCTATACGTTCATGGTGGCTACAAGGCTTTCAGTGCCAATAAGTACCGGCTTGCAGATGATCTCTACCGATATGATGTGGATACCCAGATGTGGACCATTCTTAAGGACAGCCGATTTTTCCGTTACTTGCACACAGCTGTGATAGTGAGTGGAACCATGCTGGTGTTTGGAGGAAACACACACAATGACACATCTATGAGCCATGGCGCCAAATGCTTCTCTTCAGATTTCATGGCCTATGACATTGCCTGTGACCGCTGGTCAGTGCTTCCCAGACCTGATCTCCACCATGATGTCAACAGATTTGGCCATTCAGCAGTCTTACACAACAGCACCATGTATGTGTTCGGTGGTTTCAATAGTCTCCTCCTCAGCGACATCCTGGTATTCACCTCGGAACAGTGTGATGCGCATCGGAGTGAAGCCGCTTGTTTAGCAGCAGGACCTGGTATTCGGTGTGTGTGGAACACAGGGTCGTCTCAGTGTATCTCGTGGGCGCTGGCAACTGATGAACAAGAAGAAAAGTTAAAATCAGAATGTTTTTCCAAAAGAACTCTTGACCATGACAGATGTGACCAGCACACAGATTGTTACAGCTGCACAGCCAACACCAATGACTGCCACTGGTGCAATGACCATTGTGTCCCCAGGAACCACAGCTGCTCAGAAGGCCAGATCTCCATTTTTAGGTATGAGAATTGCCCCAAGGATAACCCCATGTACTACTGTAACAAGAAGACCAGCTGCAGGAGCTGTGCCCTGGACCAGAACTGCCAGTGGGAGCCCCGGAATCAGGAGTGCATTGCCCTGCCCGAAAATATCTGTGGCATTGGCTGGCATTTGGTTGGAAACTCATGTTTGAAAATTACTACTGCCAAGGAGAATTATGACAATGCTAAATTGTTCTGTAGGAACCACAATGCCCTTTTGGCTTCTCTTACAACCCAGAAGAAGGTAGAATTTGTCCTTAAGCAGCTGCGAATAATGCAGTCATCTCAGAGCATGTCCAAGCTCACCTTAACCCCATGGGTCGGCCTTCGGAAGATCAATGTGTCCTACTGGTGCTGGGAAGATATGTCCCCATTTACAAATAGTTTACTACAGTGGATGCCGTCTGAGCCCAGTGATGCTGGATTCTGTGGAATTTTATCAGAACCCAGTACTCGGGGACTGAAGGCTGCAACCTGCATCAACCCACTCAATGGTAGTGTCTGTGAAAGGCCTGCAAACCACAGTGCTAAGCAGTGCCGGACACCATGTGCCTTGAGGACAGCATGTGGAGATTGCACCAGCGGCAGCTCTGAGTGCATGTGGTGCAGCAACATGAAGCAGTGTGTGGACTCCAATGCCTACGTGGCCTCCTTCCCTTTTGGCCAGTGTATGGAATGGTATACGATGAGCACCTGCCCCCCTGAAAATTGTTCAGGCTACTGTACCTGTAGTCATTGCTTGGAGCAACCAGGCTGTGGCTGGTGTACTGATCCCAGCAATACTGGCAAAGGGAAATGCATAGAGGGTTCCTATAAAGGACCAGTGAAGATGCCTTCGCAAGCCCCTACAGGAAATTTCTATCCACAGCCCCTGCTCAATTCCAGCATGTGTCTAGAGGACAGCAGATACAACTGGTCTTTCATTCACTGTCCAGCTTGCCAATGCAACGGCCACAGTAAATGCATCAATCAGAGCATCTGTGAGAAGTGTGAGAACCTGACCACAGGCAAGCACTGCGAGACCTGCATATCTGGCTTCTACGGTGATCCCACCAATGGAGGGAAATGTCAGCCATGCAAGTGCAATGGGCACGCGTCTCTGTGCAACACCAACACGGGCAAGTGCTTCTGCACCACCAAGGGCGTCAAGGGGGACGAGTGCCAGCTATGTGAGGTAGAAAATCGATACCAAGGAAACCCTCTCAGAGGAACATGTTATTATACTCTTCTTATTGACTATCAGTTCACCTTTAGTCTATCCCAGGAAGATGATCGCTATTACACAGCTATCAATTTTGTGGCTACTCCTGACGAACAAAACAGGGATTTGGACATGTTCATCAATGCCTCCAAGAATTTCAACCTCAACATCACCTGGGCTGCCAGTTTCTCAGCTGGAACCCAGGCTGGAGAAGAGATGCCTGTTGTTTCAAAAACCAACATTAAGGAGTACAAAGATAGTTTCTCTAATGAGAAGTTTGATTTTCGCAACCACCCAAATATCACTTTCTTTGTTTATGTCAGTAATTTCACCTGGCCCATCAAAATTCAGATTGCCTTCTCTCAGCACAGCAATTTTATGGACCTGGTACAGTTCTTCGTGACTTTCTTCAGTTGTTTCCTCTCTTTGCTCCTGGTGGCTGCTGTGGTTTGGAAGATCAAACAAAGTTGTTGGGCCTCCAGACGTAGAGAGCAACTTCTTCGAGAGATGCAACAGATGGCCAGCCGTCCCTTTGCCTCTGTAAATGTCGCCTTGGAAACAGATGAGGAGCCTCCTGATCTTATTGGGGGGAGTATAAAGACTGTTCCCAAACCCATTGCACTGGAGCCGTGTTTTGGCAACAAAGCCGCTGTCCTCTCTGTGTTTGTGAGGCTCCCTCGAGGCCTGGGTGGCATCCCTCCTCCTGGGCAGTCAGGTCTTGCTGTGGCCAGCGCCCTGGTGGACATTTCTCAGCAGATGCCGATAGTGTACAAGGAGAAGTCAGGAGCCGTGAGAAACCGGAAGCAGCAGCCCCCTGCACAGCCTGGGACCTGCATCTGA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.