NCBI Summary
The GALNT13 protein is a member of the UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase (GalNAcT; EC 2.4.1.41) family, which initiate O-linked glycosylation of mucins (see MUC3A, MIM 158371) by the initial transfer of N-acetylgalactosamine (GalNAc) with an alpha-linkage to a serine or threonine residue.[supplied by OMIM, Apr 2004].
Protein
Protein (NP_443149)
CBM13-ppGalNAc-T13
Polypeptide N-acetylgalactosaminyltransferase 13 (EC 2.4.1.41) (Polypeptide GalNAc transferase 13) (GalNAc-T13) (pp-GaNTase 13) (Protein-UDP acetylgalactosaminyltransferase 13) (UDP-GalNAc:polypeptide N-acetylgalactosaminyltransferase 13)
GALNT13
polypeptide N-acetylgalactosaminyltransferase 13
Undefined
Curated
Ricin-like
R-Type Lectins
b-trefoil
GalNAc / Mucin-type glycopeptide
0.182
MRRFVYCKVVLATSLMWVLVDVFLLLYFSECNKCDDKKERSLLPALRAVISRNQEGPGEMGKAVLIPKDDQEKMKELFKINQFNLMASDLIALNRSLPDVRLEGCKTKVYPDELPNTSVVIVFHNEAWSTLLRTVYSVINRSPHYLLSEVILVDDASERDFLKLTLENYVKNLEVPVKIIRMEERSGLIRARLRGAAASKGQVITFLDAHCECTLGWLEPLLARIKEDRKTVVCPIIDVISDDTFEYMAGSDMTYGGFNWKLNFRWYPVPQREMDRRKGDRTLPVRTPTMAGGLFSIDRNYFEEIGTYDAGMDIWGGENLEMSFRIWQCGGSLEIVTCSHVGHVFRKATPYTFPGGTGHVINKNNRRLAEVWMDEFKDFFYIISPGVVKVDYGDVSVRKTLRENLKCKPFSWYLENIYPDSQIPRRYYSLGEIRNVETNQCLDNMGRKENEKVGIFNCHGMGGNQVFSYTADKEIRTDDLCLDVSRLNGPVIMLKCHHMRGNQLWEYDAERLTLRHVNSNQCLDEPSEEDKMVPTMQDCSGSRSQQWLLRNMTLGT
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
The location of the lectin domain structural model is: 428-551
We infer [0.54, 0.92] Å as the interval of error of this structural model.
Template: 1XHB chain: A, O08912, NP_001153876.1, sequence identity: 83.9%, coverage: 100.0%, location in sequence: 95-553, (95-553 in PDB).
Show the alignment used for the construction of the structural model, Download.
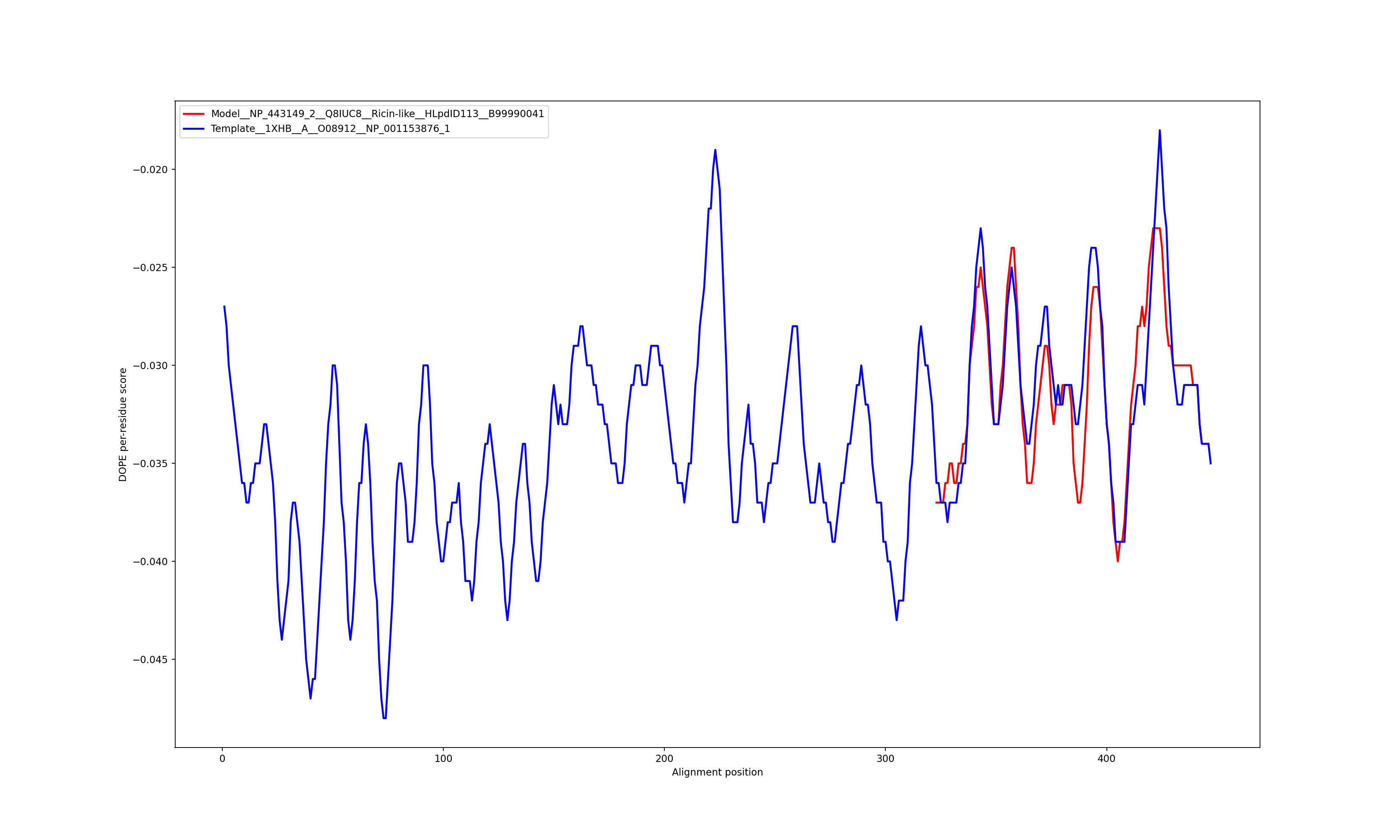
Show the plot of DOPE energy score, Download.
We infer [0.54, 0.92] Å as the interval of error of this structural model.
Template: 1XHB chain: A, O08912, NP_001153876.1, sequence identity: 83.9%, coverage: 100.0%, location in sequence: 95-553, (95-553 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- Revisiting the human polypeptide GalNAc-T1 and T13 paralogs. [27913570]
- Increased expression levels of ppGalNAc-T13 in lung cancers: Significance in the prognostic diagnosis. [27499036]
- MicroRNA-424 Predicts a Role for beta-1,4 Branched Glycosylation in Cell Cycle Progression. [26589799]
- Protein interaction network of alternatively spliced isoforms from brain links genetic risk factors for autism. [24722188]
- EMR-linked GWAS study: investigation of variation landscape of loci for body mass index in children. [24348519]
- GWAS for discovery and replication of genetic loci associated with sudden cardiac arrest in patients with coronary artery disease. [21658281]
- Replication of a genome-wide case-control study of esophageal squamous cell carcinoma. [18649358]
- Genetic correlates of longevity and selected age-related phenotypes: a genome-wide association study in the Framingham Study. [17903295]
- A protein interaction framework for human mRNA degradation. [15231747]
- Cloning and characterization of a new human UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase, designated pp-GalNAc-T13, that is specifically expressed in neurons and synthesizes GalNAc alpha-serine/threonine antigen. [12407114]
UniProt Main References (4 PubMed Identifiers)
- Generation and annotation of the DNA sequences of human chromosomes 2 and 4. [15815621]
- The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC). [15489334]
- Prediction of the coding sequences of unidentified human genes. XXI. The complete sequences of 60 new cDNA clones from brain which code for large proteins. [11572484]
- Complete sequencing and characterization of 21,243 full-length human cDNAs. [14702039]
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_052917.4)
polypeptide N-acetylgalactosaminyltransferase 13, transcript variant 1
m7G-5')ppp(5'-GACCAGGCGGCGGCGGCUCUGCUGAGGUGACAACGUGCUAGCAGCCCUCGCUCGCUCUGGGCGCCUCCUCGGCCUCAGCGUCCGCUCUGGCCGCGCUCGAGGAGCCCUUCAGCCCGCCGCUGCGCUAUGAAGGCCCCUCUCUGGGGCUGGCCGAGGCUGGAGCCGGCUCCCUCUGCUCGCGGGCAAGUGUGAAGAGAGAGGCGCGGGCGGGAGCCGGGGCUGCGCGCGGCGCUCGCGGGCCGGCGCGGGUUCCAGGUGAGCGCGGACUCGGCGAGCCCCGCACUCGGCGCGGCCGGCCGGCGCCUGCUGGGCUUGAUCUGAGGCUGAAUCCCGUGUGUGGACCGCCGUUCCCUCUUCGCGGGAUCGUUGGCCAGGAUAGCAGAUGCAUUUUUGUAGAAGCAUUUUGAGGAUGAAUGUUUGCAAAUCAUUUUGAAAUUGCCAAGUGCCACAUACAUGGAAUGUAUCCUGCUUUCAUCUUGGAGUUCACCUGUGUGGCUUGGAUUUAUCACAGUAGCAUUUGUCUUCAAUCUGUGUGUUAACUAGAAAUCAAGGAAAGACAUGAGGAGAUUUGUCUACUGCAAGGUGGUUCUAGCCACUUCGCUGAUGUGGGUUCUUGUUGAUGUCUUCUUACUGCUGUACUUCAGUGAAUGUAACAAAUGUGAUGACAAGAAGGAGAGAUCUCUGCUGCCUGCAUUGAGGGCUGUUAUUUCAAGAAACCAAGAAGGGCCAGGAGAAAUGGGAAAAGCUGUGUUGAUUCCUAAAGAUGACCAGGAGAAAAUGAAAGAGCUGUUUAAAAUCAAUCAGUUUAACCUUAUGGCCAGUGAUUUGAUUGCCCUUAAUAGAAGUCUGCCAGAUGUAAGAUUAGAAGGAUGUAAGACAAAAGUCUACCCUGAUGAACUUCCAAACACAAGUGUAGUCAUUGUGUUUCAUAAUGAAGCUUGGAGCACUCUCCUUAGAACUGUUUACAGUGUGAUAAAUCGUUCCCCACACUAUCUACUCUCAGAGGUCAUCUUGGUAGAUGAUGCCAGUGAAAGAGAUUUUCUCAAGUUGACAUUAGAGAAUUACGUGAAAAAUUUAGAAGUGCCAGUAAAAAUUAUUAGGAUGGAAGAACGCUCUGGGUUAAUACGUGCCCGUCUUCGAGGAGCAGCUGCUUCAAAAGGGCAGGUCAUAACUUUUCUUGAUGCACACUGUGAAUGCACGUUAGGAUGGCUGGAGCCUUUGCUGGCAAGAAUAAAGGAAGACAGGAAAACGGUUGUCUGCCCUAUCAUUGAUGUGAUUAGUGAUGAUACUUUUGAAUAUAUGGCUGGGUCAGACAUGACUUAUGGGGGUUUUAACUGGAAACUGAAUUUCCGCUGGUAUCCUGUUCCCCAAAGAGAAAUGGACAGGAGGAAAGGAGACAGAACAUUACCUGUCAGGACCCCUACUAUGGCUGGUGGCCUAUUUUCUAUUGACAGAAACUACUUUGAAGAGAUAGGAACUUACGAUGCAGGAAUGGAUAUCUGGGGUGGAGAGAAUCUUGAAAUGUCUUUUAGGAUUUGGCAAUGUGGAGGCUCCUUGGAGAUUGUUACUUGCUCCCAUGUUGGUCAUGUUUUUCGGAAGGCAACUCCAUACACUUUUCCUGGUGGCACUGGUCAUGUCAUCAACAAGAACAACAGGAGACUGGCAGAAGUUUGGAUGGAUGAAUUUAAAGAUUUCUUCUACAUCAUAUCCCCAGGUGUUGUCAAAGUGGAUUAUGGAGAUGUGUCAGUCAGAAAAACACUAAGAGAAAAUCUGAAGUGUAAGCCCUUUUCUUGGUACCUAGAAAACAUCUAUCCGGACUCCCAGAUCCCAAGACGUUAUUACUCACUUGGUGAGAUAAGAAAUGUUGAAACCAAUCAGUGUUUAGACAACAUGGGCCGCAAGGAAAAUGAAAAAGUGGGUAUAUUCAACUGUCAUGGUAUGGGAGGAAAUCAGGUAUUUUCUUACACUGCUGACAAAGAAAUCCGAACCGAUGACUUGUGCUUGGAUGUUUCUAGACUCAAUGGACCUGUAAUCAUGUUAAAAUGCCACCAUAUGAGAGGAAAUCAGUUAUGGGAAUAUGAUGCUGAGAGACUCACGUUGCGACAUGUUAACAGUAACCAAUGUCUCGAUGAACCUUCUGAAGAAGACAAAAUGGUGCCUACAAUGCAGGACUGUAGUGGAAGCAGAUCCCAACAGUGGCUGCUAAGGAACAUGACCUUGGGCACAUGAAGAUCAUGUCCUCCAAGCCAUGAAAGUGUCUACGCUUUUGUUUUUCCAUUAUUUCAAUUGGGGGAAAAUAUUAACUUUGCUGAAUUGAAAGUUUUAAAAAUCCUUUUAGUAUUCUAAAACACAAUUGUUUCUAAUUCGUUUCUAGAAAUGUUUGCUUAUUUCCCUACUAAAAUUUGUAUCUGAUCAAAGCACAUAAGAAUAUAAAUAAUAGCAAACUACUAUUAAACAACAGAACAACUUGUAAAACAAAUUGUGUUUGCUUUAAGAAAAAUGUUUAUUGCACUCAUGUCAUAGGGUUAAUUGGAGGUUAUUUUAUUUUUGGUUGUCAUGGUGAUUGAAAGAGAUAAUGUAAAUGCCUUAUAAAAUCUUCAUUAUGAAAUAUUAUCAGUUGCUUUAUAAACUCACUCUUUUUAUGGAUCCUUCAUGGAAACAUGUUUGAUUUCUGUGUCUACAACAGGGCCACAUAUUAAAUUACUUCUGAAUGGUGAAUUCAUCUUACAAAAUGUUCCAAGUUUUGGACAAGGAAAAACAUUACAUUGGAUAUUGAAUUCAUGGAGCCUUUACAGAAGCAUCACAUUUAAACCAAUGUGAAUUCAAAAAAGAGAAGGAAACUUUUUAAAUUCAAUUUAGAGUACAUAAAAAAAGAAAUCCGCGAAGCAUUGAGGGGAACAAGAUGAGUCUAAUCCGCAGCACUUCGAUCACUGUGAGAGAACUCAAAGUGGGUUGCAAUCAUUCCUAACACAGGCUGAAACUAAACAAUCUUGCUCCUAGAGUUUAUGUUGGAUACUCAAUUCUUAACCAAAAUCUUGGUCUCCACAAACUCUACCAUCCCUUUUCUCUUCACUCUAUAGACAGUGGCAUGCCAUUGAUGCUGUACAGAAUUGCAGGUGAAAGGGAGAAUUUUAGACUUAAUUUUUAACUCUAUUGCACUUAAAGAUUUUAGUUAGGUUACCACUGUCAUUUUCAUUUUCUAUGUUAAAGAAUACCUUUCAGUGCUGUGCUCCAGUAUCUAAAAAUUUUAUCACCAGGGGAAUAAACUCAAUACACAUUCAUUAAACUUUUGUUGUAAUUAAACUGCUAUAUAUUGUUUGCCAUAUAUUAUGGCCCAAGGAAUAUAGUUAUAAUCAGGCUACAUUCACAUUUUCUUUUCUCAUCUUAAAACCCUUUAUGUUCAAAAUACAUUAGCAGAGGCCAUGAAAGUGAAAAAAAAUCAGAUUUUUGCUAGUAAGUUUUUAUAUUUGACAUCAUUUUAAAUGCUCAAAGAGUUGCCCUAUAUAUGCAUGUUAUCCAUUAUAAAUGCACUCAGCAGCUAAGAGAAAUUUGAGAGGAAAAGUGGAAGAAGUGUUUUCUGGAGCAGAAGAUUCCACUUCUUUGGUCCUCAUCUUUACUUAAAAAGCUCUUAUAGAAAGGAUUAAUCAUUUUGACUGCAUACAAACUAUGUCUCUGACAUGCACAUACACUGCUUUAUAAUGAAAAUGAGGACACUUUCUGAUGGUCAGUAAAAUCUUAAAUGAUUUUUGCCACUGGUAUUCCUUCCUCUUUUGACUUUUUAUUGGUACAACUGUAGGGAAGAAUCUACAACCUGGAGCAUUUCAGGUUUGCUCUUUAAAUAUAGACACCCCUCACCAUGAGCUCUCUGUGAAUCCGUGAAUUUCCUAAAAUUGUAAGCAAAAUGUUGAAUAUCAGGGCAUUUUUUUUUCUGAGGUGGGAGUAUGUCACUCACAGCAAACUUGGAAAGAAGGCUAUGACUCCCAAGAGGCAGUGAACCAUUGCCUUAAAUUAAUAGCAGCCUCUCAAGUCCAUUGAGGCCUCAUGUAAAAUUCCCAUUUUUCAUCUUUACACUCCUUUUCUCCCCUCAUUUCCUCUUCUCCUUACUAAGGUAAAAAGACCCUGCACAGCAUUAUUACUUAAGUUGAAAAAGCUUCAACUCUCAAGGACUCAUGUAUACCAUAUGUUCCACUUAUUGCUUUGUUAGUCAAAAUGCAUGUUAUGUAGAAAAUGGUCAAUGGCAAAUUUUUAUAAAUACAGCUACCCCAUCAAAGCUGAACUUGAAACGUUUUAGCAGAAUUUUAAAUAUGUGAAAGUUCAUUGUGGUCAUGGUGAGAAAACUAAAACUACAUGAGUUUCAUGUUAGAAAAGAAUUUUUAAACAAUCUUCAGAUGGCUUGAACACGUGCCAUUAUAGUAUCUAACAAAAAGUGGCAUAAAAUAUUACAAAACAUCCAACACUAGAAAGCAAUGACUAACAUUUAAUUUGUUUACAAAAAUGUUUAUUGUCUUCAGUACAAAAAGUUAAAACCAUGAUUGGAUUCAUAAUGCACUUGUCUUAUCCCUUAUUUAUGGAGCUAGACUGACAUAUUUCAAACCAAUCUCUUCUGUGGUCUUCUCCAUCUCAGUUAAUGCAACUUCAACCUUCCAGAUGCUCAGGUCAAAAACUGAAAGUUGCUUUUGACUCCUCUAUUUCUGUUUCAACUCUCGUCUAAUCCAACAGCAAAUCCCCUUGAUGCUACCUUUGAAAUAUAACUAGAAAAGAAUGACUUGCCACCAUAUCCACUAGGUGUCACUACCUCUAACCUUUUUAAUCGCAAUAUGCUUAUUAUUUAGUUCCCUAAUUUCCCAGUCCUUGUCUUGAACAAUCUUUUCUCAGUACAACAGCCAUAGUGAUUCUGUUAACCAUGAAUUUGAUUGUGUCACUUCCCUGCUCACAAUCUUCCAAUGACUUCUCCCUCCGGUGGCCUUCAAGGUCCUUUAUGAGUGUUACCCCUCUACACGUCCACACCACUCACCACACAUACAUACACAUGCACACACACACACAUGCAAUUCUACCUUUUUCUAACACCAUCUCUUAUCUCUCAUUAUUCUGCCUCUUACUUACCCUAUUAUGGCUCCCAAGAAAGUUCCUGCUUUAGUGUUUUGUUCCCUCUGCCCCAGAGAGCUCCCCUUAGUGAUCUCAGUUCAAAUAUUAUCUUAUCAGUAAGACAAACCCUUCUCCCAUCUGCCUUCCCUAUCCCCUGUACCUGACAAUCUAUGAGUUUGCUUCUUUAUUUCUGUCUAUACUUCCCCCUCCCCAGCCCCAAACAUGCCCAUCACAUGCCCUAGAAGGUAAGUCCCAUGAAGGCAGGGGCUUUGUCAGUUUUGUUCAUUUGGUAUUUCUGGCAUAUAUAUUCUCUAAAUAUUUCUUGAAUUAAUGAACUGAAAAAUGUGUGUUAAAGUUGCUAAGUGUAACUGUAUCAUACUUUUUUUGUAUUUUAAAUUUUAAAAUAAAGGCUAAUAUAUUUAGACAGGAUUUCCAAAAACUUUGUCUUCAAAUUUUAAUUUUCUUCCUAAUAUUCUUCACAUUAAACUAUGGACUCUAAUUUUCUGGAUAAAAUAUCCUGCCUUAUGGAAAUGAAAUAUGAAAUUUUAUUAAAAUGCUGCUAUAUUACA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 114805)
polypeptide N-acetylgalactosaminyltransferase 13
strand +
KIAA1918, GalNAc-T13
NCBI CDS gene sequence (1671 bp)
5'-ATGAGGAGATTTGTCTACTGCAAGGTGGTTCTAGCCACTTCGCTGATGTGGGTTCTTGTTGATGTCTTCTTACTGCTGTACTTCAGTGAATGTAACAAATGTGATGACAAGAAGGAGAGATCTCTGCTGCCTGCATTGAGGGCTGTTATTTCAAGAAACCAAGAAGGGCCAGGAGAAATGGGAAAAGCTGTGTTGATTCCTAAAGATGACCAGGAGAAAATGAAAGAGCTGTTTAAAATCAATCAGTTTAACCTTATGGCCAGTGATTTGATTGCCCTTAATAGAAGTCTGCCAGATGTAAGATTAGAAGGATGTAAGACAAAAGTCTACCCTGATGAACTTCCAAACACAAGTGTAGTCATTGTGTTTCATAATGAAGCTTGGAGCACTCTCCTTAGAACTGTTTACAGTGTGATAAATCGTTCCCCACACTATCTACTCTCAGAGGTCATCTTGGTAGATGATGCCAGTGAAAGAGATTTTCTCAAGTTGACATTAGAGAATTACGTGAAAAATTTAGAAGTGCCAGTAAAAATTATTAGGATGGAAGAACGCTCTGGGTTAATACGTGCCCGTCTTCGAGGAGCAGCTGCTTCAAAAGGGCAGGTCATAACTTTTCTTGATGCACACTGTGAATGCACGTTAGGATGGCTGGAGCCTTTGCTGGCAAGAATAAAGGAAGACAGGAAAACGGTTGTCTGCCCTATCATTGATGTGATTAGTGATGATACTTTTGAATATATGGCTGGGTCAGACATGACTTATGGGGGTTTTAACTGGAAACTGAATTTCCGCTGGTATCCTGTTCCCCAAAGAGAAATGGACAGGAGGAAAGGAGACAGAACATTACCTGTCAGGACCCCTACTATGGCTGGTGGCCTATTTTCTATTGACAGAAACTACTTTGAAGAGATAGGAACTTACGATGCAGGAATGGATATCTGGGGTGGAGAGAATCTTGAAATGTCTTTTAGGATTTGGCAATGTGGAGGCTCCTTGGAGATTGTTACTTGCTCCCATGTTGGTCATGTTTTTCGGAAGGCAACTCCATACACTTTTCCTGGTGGCACTGGTCATGTCATCAACAAGAACAACAGGAGACTGGCAGAAGTTTGGATGGATGAATTTAAAGATTTCTTCTACATCATATCCCCAGGTGTTGTCAAAGTGGATTATGGAGATGTGTCAGTCAGAAAAACACTAAGAGAAAATCTGAAGTGTAAGCCCTTTTCTTGGTACCTAGAAAACATCTATCCGGACTCCCAGATCCCAAGACGTTATTACTCACTTGGTGAGATAAGAAATGTTGAAACCAATCAGTGTTTAGACAACATGGGCCGCAAGGAAAATGAAAAAGTGGGTATATTCAACTGTCATGGTATGGGAGGAAATCAGGTATTTTCTTACACTGCTGACAAAGAAATCCGAACCGATGACTTGTGCTTGGATGTTTCTAGACTCAATGGACCTGTAATCATGTTAAAATGCCACCATATGAGAGGAAATCAGTTATGGGAATATGATGCTGAGAGACTCACGTTGCGACATGTTAACAGTAACCAATGTCTCGATGAACCTTCTGAAGAAGACAAAATGGTGCCTACAATGCAGGACTGTAGTGGAAGCAGATCCCAACAGTGGCTGCTAAGGAACATGACCTTGGGCACATGA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.