NCBI Summary
This gene encodes a member of the immunoglobulin superfamily. The encoded protein is a lectin-like adhesion molecule that binds glycoconjugate ligands on cell surfaces in a sialic acid-dependent manner. It is a type I transmembrane protein expressed only by a subpopulation of macrophages and is involved in mediating cell-cell interactions. Alternative splicing produces a transcript variant encoding an isoform that is soluble rather than membrane-bound; however, the full-length nature of this variant has not been determined. [provided by RefSeq, Jul 2008].
Protein
Protein (NP_075556)
SIGLEC-1
Sialoadhesin (Sialic acid-binding Ig-like lectin 1) (Siglec-1) (CD antigen CD169)
SIGLEC1
sialic acid binding Ig like lectin 1
Curated
I-type lectin
I-Type Lectins - Siglecs common to mammals
b-sandwich / Ig-like
NeuAc / Neu5Ac(a2-3)Gal(b1-4)GlcNAc
0.456
MGFLPKLLLLASFFPAGQASWGVSSPQDVQGVKGSCLLIPCIFSFPADVEVPDGITAIWYYDYSGQRQVVSHSADPKLVEARFRGRTEFMGNPEHRVCNLLLKDLQPEDSGSYNFRFEISEVNRWSDVKGTLVTVTEEPRVPTIASPVELLEGTEVDFNCSTPYVCLQEQVRLQWQGQDPARSVTFNSQKFEPTGVGHLETLHMAMSWQDHGRILRCQLSVANHRAQSEIHLQVKYAPKGVKILLSPSGRNILPGELVTLTCQVNSSYPAVSSIKWLKDGVRLQTKTGVLHLPQAAWSDAGVYTCQAENGVGSLVSPPISLHIFMAEVQVSPAGPILENQTVTLVCNTPNEAPSDLRYSWYKNHVLLEDAHSHTLRLHLATRADTGFYFCEVQNVHGSERSGPVSVVVNHPPLTPVLTAFLETQAGLVGILHCSVVSEPLATLVLSHGGHILASTSGDSDHSPRFSGTSGPNSLRLEIRDLEETDSGEYKCSATNSLGNATSTLDFHANAARLLISPAAEVVEGQAVTLSCRSGLSPTPDARFSWYLNGALLHEGPGSSLLLPAASSTDAGSYHCRARDGHSASGPSSPAVLTVLYPPRQPTFTTRLDLDAAGAGAGRRGLLLCRVDSDPPARLQLLHKDRVVATSLPSGGGCSTCGGCSPRMKVTKAPNLLRVEIHNPLLEEEGLYLCEASNALGNASTSATFNGQATVLAIAPSHTLQEGTEANLTCNVSREAAGSPANFSWFRNGVLWAQGPLETVTLLPVARTDAALYACRILTEAGAQLSTPVLLSVLYPPDRPKLSALLDMGQGHMALFICTVDSRPLALLALFHGEHLLATSLGPQVPSHGRFQAKAEANSLKLEVRELGLGDSGSYRCEATNVLGSSNTSLFFQVRGAWVQVSPSPELQEGQAVVLSCQVHTGVPEGTSYRWYRDGQPLQESTSATLRFAAITLTQAGAYHCQAQAPGSATTSLAAPISLHVSYAPRHVTLTTLMDTGPGRLGLLLCRVDSDPPAQLRLLHGDRLVASTLQGVGGPEGSSPRLHVAVAPNTLRLEIHGAMLEDEGVYICEASNTLGQASASADFDAQAVNVQVWPGATVREGQLVNLTCLVWTTHPAQLTYTWYQDGQQRLDAHSIPLPNVTVRDATSYRCGVGPPGRAPRLSRPITLDVLYAPRNLRLTYLLESHGGQLALVLCTVDSRPPAQLALSHAGRLLASSTAASVPNTLRLELRGPQPRDEGFYSCSARSPLGQANTSLELRLEGVRVILAPEAAVPEGAPITVTCADPAAHAPTLYTWYHNGRWLQEGPAASLSFLVATRAHAGAYSCQAQDAQGTRSSRPAALQVLYAPQDAVLSSFRDSRARSMAVIQCTVDSEPPAELALSHDGKVLATSSGVHSLASGTGHVQVARNALRLQVQDVPAGDDTYVCTAQNLLGSISTIGRLQVEGARVVAEPGLDVPEGAALNLSCRLLGGPGPVGNSTFAWFWNDRRLHAEPVPTLAFTHVARAQAGMYHCLAELPTGAAASAPVMLRVLYPPKTPTMMVFVEPEGGLRGILDCRVDSEPLASLTLHLGSRLVASSQPQGAPAEPHIHVLASPNALRVDIEALRPSDQGEYICSASNVLGSASTSTYFGVRALHRLHQFQQLLWVLGLLVGLLLLLLGLGACYTWRRRRVCKQSMGENSVEMAFQKETTQLIDPDAATCETSTCAPPLG
No structure currently available in the PDB RCSB Databank.
Structural models
SWISS-MODEL structural models
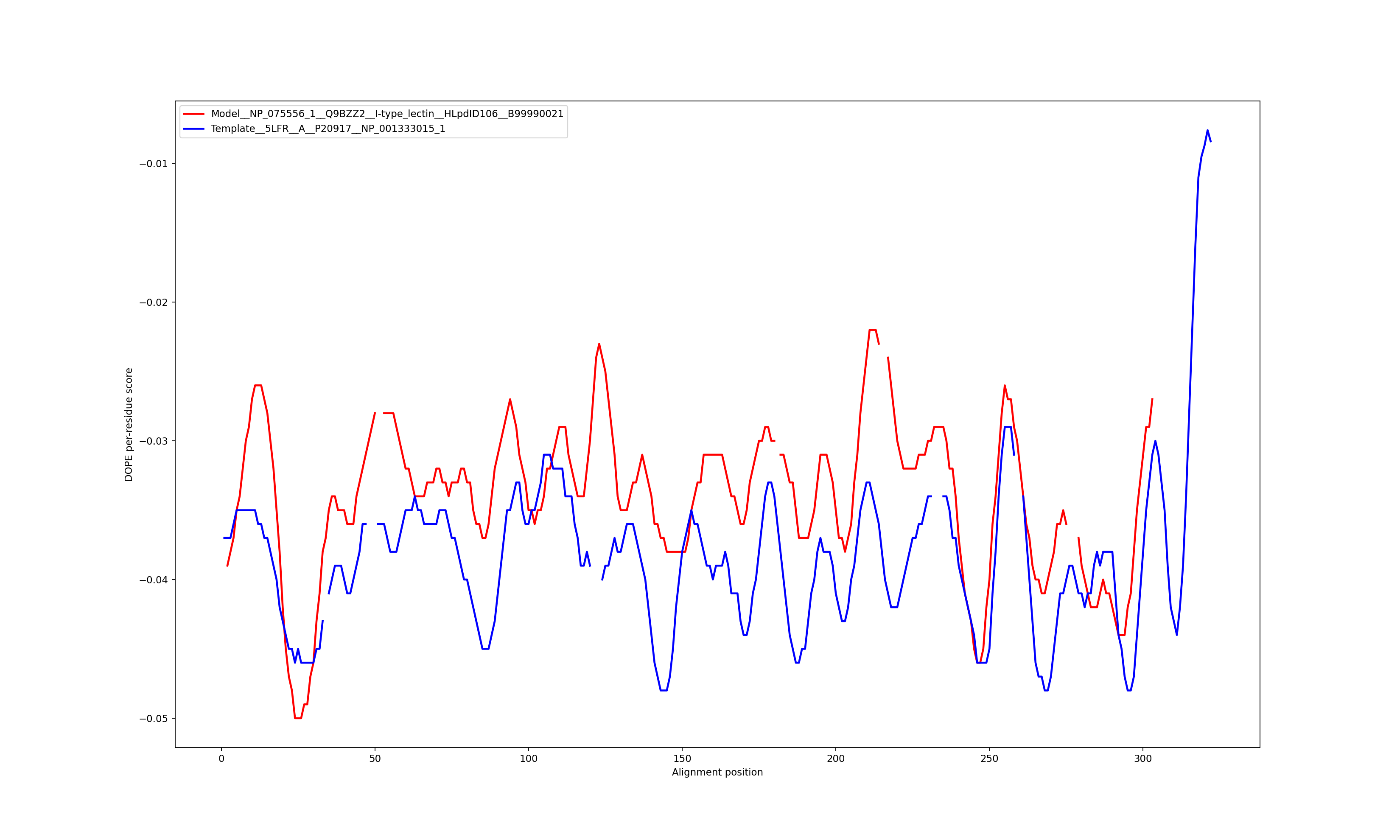
The location of the lectin domain structural model is: 19-312
We infer [1.55, 1.99] Å as the interval of error of this structural model.
Template: 5LFR chain: A, P20917, NP_001333015.1, sequence identity: 28.9%, coverage: 96.9%, location in sequence: 19-331, (19-331 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
We infer [1.55, 1.99] Å as the interval of error of this structural model.
Template: 5LFR chain: A, P20917, NP_001333015.1, sequence identity: 28.9%, coverage: 96.9%, location in sequence: 19-331, (19-331 in PDB).
Show the alignment used for the construction of the structural model, Download.
Show the plot of DOPE energy score, Download.
{kind=link}
Oligomerization and Known Interactions
Interacts with TYROBP. Interacts with CLEC10A (By similarity)
Annotation
Ligand
Glycan ligands from structural data
No crystal structures of complexes with glycan ligand.
References
NCBI References (10 PubMed Identifiers)
- Lectins enhance SARS-CoV-2 infection and influence neutralizing antibodies. [34464958]
- SIGLEC1 (CD169): a marker of active neuroinflammation in the brain but not in the blood of multiple sclerosis patients. [33986412]
- Monocyte CD169 expression in COVID-19 patients upon intensive care unit admission. [33547747]
- CD169 and CD64 could help differentiate bacterial from CoVID-19 or other viral infections in the Emergency Department. [33491921]
- Monocyte CD169 Expression as a Biomarker in the Early Diagnosis of Coronavirus Disease 2019. [33206973]
- Characterization of human sialoadhesin, a sialic acid binding receptor expressed by resident and inflammatory macrophage populations. [11133773]
- Characterization of long cDNA clones from human adult spleen. [11214971]
- Macrophage-tumour cell interactions: identification of MUC1 on breast cancer cells as a potential counter-receptor for the macrophage-restricted receptor, sialoadhesin. [10610356]
- Glycosylation of a CNS-specific extracellular matrix glycoprotein, tenascin-R, is dominated by O-linked sialylated glycans and 'brain-type' neutral N-glycans. [10406848]
- Sialoadhesin (Sn) maps to mouse chromosome 2 and human chromosome 20 and is not linked to the other members of the sialoadhesin family, CD22, MAG, and CD33. [8530048]
UniProt Main References (2 PubMed Identifiers)
- The DNA sequence and comparative analysis of human chromosome 20. [11780052]
- Complete sequencing and characterization of 21,243 full-length human cDNAs. [14702039]
All isoforms of this gene containing a lectin domain
RNA
RNA (Transcript ID: NM_023068.4)
sialic acid binding Ig like lectin 1, transcript variant 1
m7G-5')ppp(5'-GAUACGGGAUCCUUCUCUCUUGAGCCGGCAGAGCCCUGGGGAGCCAGCUGCACCAGGAGCUCUUGGCCGUCCUUCCUGUUCUCCUCUCCGCAGGUCCAGCACCGCCGCAGCCACUUCCUUCUGUGGAGCAGCAGGUGCUGGGGCUAAAGUGCCCAGAGGUGUCCCUGGAGGCCCCUGUGAGCCCAGCCAGCGCAGUGCGCACCACCCUCUUAGGCAACAGGAGCAGCACAAGAACCUGCUAUGGGCUUCUUGCCCAAGCUUCUCCUCCUGGCCUCAUUCUUCCCAGCAGGCCAGGCCUCAUGGGGCGUCUCCAGUCCCCAGGACGUGCAGGGUGUGAAGGGGUCUUGCCUGCUUAUCCCCUGCAUCUUCAGCUUCCCUGCCGACGUGGAGGUGCCCGACGGCAUCACGGCCAUCUGGUACUACGACUACUCGGGCCAGCGGCAGGUGGUGAGCCACUCGGCGGACCCCAAGCUGGUGGAGGCCCGCUUCCGCGGCCGCACCGAGUUCAUGGGGAACCCCGAGCACAGGGUGUGCAACCUGCUGCUGAAGGACCUGCAGCCCGAGGACUCUGGUUCCUACAACUUCCGCUUCGAGAUCAGUGAGGUCAACCGCUGGUCAGAUGUGAAAGGCACCUUGGUCACAGUAACAGAGGAGCCCAGGGUGCCCACCAUUGCCUCCCCGGUGGAGCUUCUCGAGGGCACAGAGGUGGACUUCAACUGCUCCACUCCCUACGUAUGCCUGCAGGAGCAGGUCAGACUGCAGUGGCAAGGCCAGGACCCUGCUCGCUCUGUCACCUUCAACAGCCAGAAGUUUGAGCCCACCGGCGUCGGCCACCUGGAGACCCUCCACAUGGCCAUGUCCUGGCAGGACCACGGCCGGAUCCUGCGCUGCCAGCUCUCCGUGGCCAAUCACAGGGCUCAGAGCGAGAUUCACCUCCAAGUGAAGUAUGCCCCCAAGGGUGUGAAGAUCCUCCUCAGCCCCUCGGGGAGGAACAUCCUUCCAGGUGAGCUGGUCACACUCACCUGCCAGGUGAACAGCAGCUACCCUGCAGUCAGUUCCAUUAAGUGGCUCAAGGAUGGGGUACGCCUCCAAACCAAGACUGGUGUGCUGCACCUGCCCCAGGCAGCCUGGAGCGAUGCUGGCGUCUACACCUGCCAAGCUGAGAACGGCGUGGGCUCUUUGGUCUCACCCCCCAUCAGCCUCCACAUCUUCAUGGCUGAGGUCCAGGUGAGCCCAGCAGGUCCCAUCCUGGAGAACCAGACAGUGACACUAGUCUGCAACACACCCAAUGAGGCACCCAGUGAUCUCCGCUACAGCUGGUACAAGAACCAUGUCCUGCUGGAGGAUGCCCACUCCCAUACCCUCCGGCUGCACUUGGCCACUAGGGCUGAUACUGGCUUCUACUUCUGUGAGGUGCAGAACGUCCAUGGCAGCGAGCGCUCGGGCCCUGUCAGCGUGGUAGUCAACCACCCGCCUCUCACUCCAGUCCUGACAGCCUUCCUGGAGACCCAGGCGGGACUUGUGGGCAUCCUUCACUGCUCUGUGGUCAGUGAGCCCCUGGCCACACUGGUGCUGUCACAUGGGGGUCAUAUCCUGGCCUCCACCUCCGGGGACAGUGAUCACAGCCCACGCUUCAGUGGUACCUCUGGUCCCAACUCCCUGCGCCUGGAGAUCCGAGACCUGGAGGAAACUGACAGUGGGGAGUACAAGUGCUCAGCCACCAACUCCCUUGGAAAUGCAACCUCCACCCUGGACUUCCAUGCCAAUGCCGCCCGUCUCCUCAUCAGCCCGGCAGCCGAGGUGGUGGAAGGACAGGCAGUGACACUGAGCUGCAGAAGCGGCCUAAGCCCCACACCUGAUGCCCGCUUCUCCUGGUACCUGAAUGGAGCCCUGCUUCACGAGGGUCCCGGCAGCAGCCUCCUGCUCCCCGCGGCCUCCAGCACUGACGCCGGCUCAUACCACUGCCGGGCCCGGGACGGCCACAGUGCCAGUGGCCCCUCUUCGCCAGCUGUUCUCACUGUGCUCUACCCCCCUCGACAACCAACAUUCACCACCAGGCUGGACCUUGAUGCCGCUGGGGCCGGGGCUGGACGGCGAGGCCUCCUUUUGUGCCGUGUGGACAGCGACCCCCCCGCCAGGCUGCAGCUGCUCCACAAGGACCGUGUUGUGGCCACUUCCCUGCCAUCAGGGGGUGGCUGCAGCACCUGUGGGGGCUGUUCCCCACGCAUGAAGGUCACCAAAGCCCCCAACUUGCUGCGUGUGGAGAUUCACAACCCUUUGCUGGAAGAGGAGGGCUUGUACCUCUGUGAGGCCAGCAAUGCCCUGGGCAACGCCUCCACCUCAGCCACCUUCAAUGGCCAGGCCACUGUCCUGGCCAUUGCACCAUCACACACACUUCAGGAGGGCACAGAAGCCAACUUGACUUGCAACGUGAGCCGGGAAGCUGCUGGCAGCCCUGCUAACUUCUCCUGGUUCCGAAAUGGGGUGCUGUGGGCCCAGGGUCCCCUGGAGACCGUGACACUGCUGCCCGUGGCCAGAACUGAUGCUGCCCUUUACGCCUGCCGCAUCCUGACUGAGGCUGGUGCCCAGCUCUCCACUCCCGUGCUCCUGAGUGUACUCUAUCCCCCGGACCGUCCAAAGCUGUCAGCCCUCCUAGACAUGGGCCAGGGCCACAUGGCUCUGUUCAUCUGCACUGUGGACAGCCGCCCCCUGGCCUUGCUGGCCUUGUUCCAUGGGGAGCACCUCCUGGCCACCAGCCUGGGUCCCCAGGUCCCAUCCCAUGGUCGGUUCCAGGCUAAAGCUGAGGCCAACUCCCUGAAGUUAGAGGUCCGAGAACUGGGCCUUGGGGACUCUGGCAGCUACCGCUGUGAGGCCACAAAUGUUCUUGGAUCAUCCAACACCUCACUCUUCUUCCAGGUCCGAGGAGCCUGGGUCCAGGUGUCACCAUCACCUGAGCUCCAAGAGGGCCAGGCUGUGGUCCUGAGCUGCCAGGUACACACAGGAGUCCCAGAGGGGACCUCAUAUCGUUGGUAUCGGGAUGGCCAGCCCCUCCAGGAGUCGACCUCGGCCACGCUCCGCUUUGCAGCCAUAACUUUGACACAAGCUGGGGCCUAUCAUUGCCAAGCCCAGGCCCCAGGCUCAGCCACCACGAGCCUAGCUGCACCCAUCAGCCUCCACGUGUCCUAUGCCCCACGCCACGUCACACUCACUACCCUGAUGGACACAGGCCCUGGACGACUGGGCCUCCUCCUGUGCCGUGUGGACAGUGACCCUCCGGCCCAGCUGCGGCUGCUCCACGGGGAUCGCCUUGUGGCCUCCACCCUACAAGGUGUGGGGGGACCCGAAGGCAGCUCUCCCAGGCUGCAUGUGGCUGUGGCCCCCAACACACUGCGUCUGGAGAUCCACGGGGCUAUGCUGGAGGAUGAGGGUGUCUAUAUCUGUGAGGCCUCCAACACCCUGGGCCAGGCCUCGGCCUCAGCUGACUUCGACGCUCAAGCUGUGAAUGUGCAGGUGUGGCCCGGGGCUACCGUGCGGGAGGGGCAGCUGGUGAACCUGACCUGCCUUGUGUGGACCACUCACCCGGCCCAGCUCACCUACACAUGGUACCAGGAUGGGCAGCAGCGCCUGGAUGCCCACUCCAUCCCCCUGCCCAACGUCACAGUCAGGGAUGCCACCUCCUACCGCUGCGGUGUGGGCCCCCCUGGUCGGGCACCCCGCCUCUCCAGACCUAUCACCUUGGACGUCCUCUACGCGCCCCGCAACCUGCGCCUGACCUACCUCCUGGAGAGCCAUGGCGGGCAGCUGGCCCUGGUACUGUGCACUGUGGACAGCCGCCCGCCCGCCCAGCUGGCCCUCAGCCACGCCGGUCGCCUCUUGGCCUCCUCGACAGCAGCCUCUGUCCCCAACACCCUGCGCCUGGAGCUGCGAGGGCCACAGCCCAGGGAUGAGGGUUUCUACAGCUGCUCUGCCCGCAGCCCUCUGGGCCAGGCCAACACGUCCCUGGAGCUGCGGCUGGAGGGUGUGCGGGUGAUCCUGGCUCCGGAGGCUGCCGUGCCUGAAGGUGCCCCCAUCACAGUGACCUGUGCGGACCCUGCUGCCCACGCACCCACACUCUAUACUUGGUACCACAACGGUCGUUGGCUGCAGGAGGGUCCAGCUGCCUCACUCUCAUUCCUGGUGGCCACGCGGGCUCAUGCAGGCGCCUACUCUUGCCAGGCCCAGGAUGCCCAGGGCACCCGCAGCUCCCGUCCUGCUGCCCUGCAAGUCCUCUAUGCCCCUCAGGACGCUGUCCUGUCCUCCUUCCGGGACUCCAGGGCCAGAUCCAUGGCUGUGAUACAGUGCACUGUGGACAGUGAGCCACCUGCUGAGCUGGCCCUAUCUCAUGAUGGCAAGGUGCUGGCCACGAGCAGCGGGGUCCACAGCUUGGCAUCAGGGACAGGCCAUGUCCAGGUGGCCCGAAACGCCCUACGGCUGCAGGUGCAAGAUGUGCCUGCAGGUGAUGACACCUAUGUUUGCACAGCCCAAAACUUGCUGGGCUCAAUCAGCACCAUCGGGCGGUUGCAGGUAGAAGGUGCACGCGUGGUGGCAGAGCCUGGCCUGGACGUGCCUGAGGGCGCUGCCCUGAACCUCAGCUGCCGCCUCCUGGGUGGCCCUGGGCCUGUGGGCAACUCCACCUUUGCAUGGUUCUGGAAUGACCGGCGGCUGCACGCGGAGCCUGUGCCCACUCUCGCCUUCACCCACGUGGCUCGUGCUCAAGCUGGGAUGUACCACUGCCUGGCUGAGCUCCCCACUGGGGCUGCUGCCUCUGCUCCAGUCAUGCUCCGUGUGCUCUACCCUCCCAAGACGCCCACCAUGAUGGUCUUCGUGGAGCCUGAGGGUGGCCUCCGGGGCAUCCUGGAUUGCCGAGUGGACAGCGAGCCGCUCGCCAGCCUGACUCUCCACCUUGGCAGUCGACUGGUGGCCUCCAGUCAGCCCCAGGGUGCUCCUGCAGAGCCACACAUCCAUGUCCUGGCUUCCCCCAAUGCCCUGAGGGUGGACAUCGAGGCGCUGAGGCCCAGCGACCAAGGGGAAUACAUCUGUUCUGCCUCAAAUGUCCUGGGCUCUGCCUCUACCUCCACCUACUUUGGGGUCAGAGCCCUGCACCGCCUGCAUCAGUUCCAGCAGCUGCUCUGGGUCCUGGGACUGCUGGUGGGCCUCCUGCUCCUGCUGUUGGGCCUGGGGGCCUGCUACACCUGGAGAAGGAGGCGUGUUUGUAAGCAGAGCAUGGGCGAGAAUUCGGUGGAGAUGGCUUUUCAGAAAGAGACCACGCAGCUCAUUGAUCCUGAUGCAGCCACAUGUGAGACCUCAACCUGUGCCCCACCCCUGGGCUGACCAGUGGUGUUGCCUGCCCUCCGGAGGAGAAAGUGGCCAGAAUCUGUGAUGACUCCAGCCUAUGAAUGUGAAUGAGGCAGUGUUGAGUCCUGCCCGCCUCUACGAAAACAGCUCUGUGACAUCUGACUUUUUAUGACCUGGCCCCAAGCCUCUUGCCCCCCCAAAAAUGGGUGGUGAGAGGUCUGCCCAGGAGGGUGUUGACCCUGGAGGACACUGAAGAGCACUGAGCUGAUCUCGCUCUCUCUUCUCUGGAUCUCCUCCCUUCUCUCCAUUUCUCCCUCAAAGGAAGCCCUGCCCUUUCACAUCCUUCUCCUCGAAAGUCACCCUGGACUUUGGUUGGAUUGCAGCAUCCUGCAUCCUCAGAGGCUCACCAAGGCAUUCUGUAUUCAACAGAGUAUCAGUCAGCCUGCUCUAACAAGAGACCAAAUACAGUGACUUCAACAUGAUAGAAUUUUAUUUUUCUCUCCCACGCUAGUCUGGCUGUUACGAUGGUUUAUGAUGUUGGGGCUCAGGAUCCUUCUAUCUUCCUUUUCUCUAUCCCUAAAAUGAUGCCUUUGAUUGUGAGGCUCACCAUGGCCCCGCUUUGUCCACAUGCCCUCCAGCCAGAAGAAGGAAGAGUGGAGGUAGAAGCACACCCAUGCCCAUGGUGGACGCAACUCAGAAGCUGCACAGGACUUUUCCACUCACUUCCCAUUGGCUGGAGUAUUGUCACAUGGCUACUGCAAGCUACAAGGGAGACUGGGAAAUGUAGUUUUUAUUUUGAGUCCAGAGGACAUUUGGAAUUGGACUUCCAAAGGACUCCCAACUGUGAGCUCAUCCCUGAGACUUUUGACAUUGUUGGGAAUGCCACCAGCAGGCCAUGUUUUGUCUCAGUGCCCAUCUACUGAGGGCCAGGGUGUGCCCCUGGCCAUUCUGGUUGUGGGCUUCCUGGAAGAGGUGAUCACUCUCACACUAAGACUGAGGAAAUAAAAAAGGUUUGGUGUUUUCCUAGGGAGAGAGCAUGCCAGGCAGUGGAGUUGCCUAAGCAGACAUCCUUGUGCCAGAUUUGGCCCCUGAAAGAAGAGAUGCCCUCAUUCCCACCACCACCCCCCCUACCCCCAGGGACUGGGUACUACCUUACUGGCCCUUACAAGAGUGGAGGGCAGACACAGAUGUUGUCAGCAUCCUUAUUCCUGCUCCAGAUGCAUCUCUGUUCAUGACUGUGUGAGCUCCUGUCCUUUUCCUGGAGACCCUGUGUCGGGCUGUUAAAGAGAAUGAGUUACCAAGAAGGAAUGACGUGCCCCUGCGAAUCAGGGACCAACAGGAGAGAGCUCUUGAGUGGGCUAGUGACUCCCCCUGCAGCCUGGUGGAGAUGGUGUGAGGAGCGAAGAGCCCUCUGCUCUAGGAUUUGGGUUGAAAAACAGAGAGAGAAGUGGGGAGUUGCCACAGGAGCUAACACGCUGGGAGGCAGUUGGGGGCGGGUGAACUUUGUGUAGCCGAGGCCGCACCCUCCCUCAUUCCAGGCUCAUUCAUUUUCAUGCUCCAUUGCCAGACUCUUGCUGGGAGCCCGUCCAGAAUGUCCUCCCAAUAAAACUCCAUCCUAUGACGCAA-3'- Poly-A tail - Coding region
DNA
DNA (Gene ID: 6614)
sialic acid binding Ig like lectin 1
strand -
SIGLEC-1, CD169, FLJ00051, FLJ00055, FLJ00073, FLJ32150, dJ1009E24.1, sialoadhesin
NCBI CDS gene sequence (5130 bp)
5'-ATGGGCTTCTTGCCCAAGCTTCTCCTCCTGGCCTCATTCTTCCCAGCAGGCCAGGCCTCATGGGGCGTCTCCAGTCCCCAGGACGTGCAGGGTGTGAAGGGGTCTTGCCTGCTTATCCCCTGCATCTTCAGCTTCCCTGCCGACGTGGAGGTGCCCGACGGCATCACGGCCATCTGGTACTACGACTACTCGGGCCAGCGGCAGGTGGTGAGCCACTCGGCGGACCCCAAGCTGGTGGAGGCCCGCTTCCGCGGCCGCACCGAGTTCATGGGGAACCCCGAGCACAGGGTGTGCAACCTGCTGCTGAAGGACCTGCAGCCCGAGGACTCTGGTTCCTACAACTTCCGCTTCGAGATCAGTGAGGTCAACCGCTGGTCAGATGTGAAAGGCACCTTGGTCACAGTAACAGAGGAGCCCAGGGTGCCCACCATTGCCTCCCCGGTGGAGCTTCTCGAGGGCACAGAGGTGGACTTCAACTGCTCCACTCCCTACGTATGCCTGCAGGAGCAGGTCAGACTGCAGTGGCAAGGCCAGGACCCTGCTCGCTCTGTCACCTTCAACAGCCAGAAGTTTGAGCCCACCGGCGTCGGCCACCTGGAGACCCTCCACATGGCCATGTCCTGGCAGGACCACGGCCGGATCCTGCGCTGCCAGCTCTCCGTGGCCAATCACAGGGCTCAGAGCGAGATTCACCTCCAAGTGAAGTATGCCCCCAAGGGTGTGAAGATCCTCCTCAGCCCCTCGGGGAGGAACATCCTTCCAGGTGAGCTGGTCACACTCACCTGCCAGGTGAACAGCAGCTACCCTGCAGTCAGTTCCATTAAGTGGCTCAAGGATGGGGTACGCCTCCAAACCAAGACTGGTGTGCTGCACCTGCCCCAGGCAGCCTGGAGCGATGCTGGCGTCTACACCTGCCAAGCTGAGAACGGCGTGGGCTCTTTGGTCTCACCCCCCATCAGCCTCCACATCTTCATGGCTGAGGTCCAGGTGAGCCCAGCAGGTCCCATCCTGGAGAACCAGACAGTGACACTAGTCTGCAACACACCCAATGAGGCACCCAGTGATCTCCGCTACAGCTGGTACAAGAACCATGTCCTGCTGGAGGATGCCCACTCCCATACCCTCCGGCTGCACTTGGCCACTAGGGCTGATACTGGCTTCTACTTCTGTGAGGTGCAGAACGTCCATGGCAGCGAGCGCTCGGGCCCTGTCAGCGTGGTAGTCAACCACCCGCCTCTCACTCCAGTCCTGACAGCCTTCCTGGAGACCCAGGCGGGACTTGTGGGCATCCTTCACTGCTCTGTGGTCAGTGAGCCCCTGGCCACACTGGTGCTGTCACATGGGGGTCATATCCTGGCCTCCACCTCCGGGGACAGTGATCACAGCCCACGCTTCAGTGGTACCTCTGGTCCCAACTCCCTGCGCCTGGAGATCCGAGACCTGGAGGAAACTGACAGTGGGGAGTACAAGTGCTCAGCCACCAACTCCCTTGGAAATGCAACCTCCACCCTGGACTTCCATGCCAATGCCGCCCGTCTCCTCATCAGCCCGGCAGCCGAGGTGGTGGAAGGACAGGCAGTGACACTGAGCTGCAGAAGCGGCCTAAGCCCCACACCTGATGCCCGCTTCTCCTGGTACCTGAATGGAGCCCTGCTTCACGAGGGTCCCGGCAGCAGCCTCCTGCTCCCCGCGGCCTCCAGCACTGACGCCGGCTCATACCACTGCCGGGCCCGGGACGGCCACAGTGCCAGTGGCCCCTCTTCGCCAGCTGTTCTCACTGTGCTCTACCCCCCTCGACAACCAACATTCACCACCAGGCTGGACCTTGATGCCGCTGGGGCCGGGGCTGGACGGCGAGGCCTCCTTTTGTGCCGTGTGGACAGCGACCCCCCCGCCAGGCTGCAGCTGCTCCACAAGGACCGTGTTGTGGCCACTTCCCTGCCATCAGGGGGTGGCTGCAGCACCTGTGGGGGCTGTTCCCCACGCATGAAGGTCACCAAAGCCCCCAACTTGCTGCGTGTGGAGATTCACAACCCTTTGCTGGAAGAGGAGGGCTTGTACCTCTGTGAGGCCAGCAATGCCCTGGGCAACGCCTCCACCTCAGCCACCTTCAATGGCCAGGCCACTGTCCTGGCCATTGCACCATCACACACACTTCAGGAGGGCACAGAAGCCAACTTGACTTGCAACGTGAGCCGGGAAGCTGCTGGCAGCCCTGCTAACTTCTCCTGGTTCCGAAATGGGGTGCTGTGGGCCCAGGGTCCCCTGGAGACCGTGACACTGCTGCCCGTGGCCAGAACTGATGCTGCCCTTTACGCCTGCCGCATCCTGACTGAGGCTGGTGCCCAGCTCTCCACTCCCGTGCTCCTGAGTGTACTCTATCCCCCGGACCGTCCAAAGCTGTCAGCCCTCCTAGACATGGGCCAGGGCCACATGGCTCTGTTCATCTGCACTGTGGACAGCCGCCCCCTGGCCTTGCTGGCCTTGTTCCATGGGGAGCACCTCCTGGCCACCAGCCTGGGTCCCCAGGTCCCATCCCATGGTCGGTTCCAGGCTAAAGCTGAGGCCAACTCCCTGAAGTTAGAGGTCCGAGAACTGGGCCTTGGGGACTCTGGCAGCTACCGCTGTGAGGCCACAAATGTTCTTGGATCATCCAACACCTCACTCTTCTTCCAGGTCCGAGGAGCCTGGGTCCAGGTGTCACCATCACCTGAGCTCCAAGAGGGCCAGGCTGTGGTCCTGAGCTGCCAGGTACACACAGGAGTCCCAGAGGGGACCTCATATCGTTGGTATCGGGATGGCCAGCCCCTCCAGGAGTCGACCTCGGCCACGCTCCGCTTTGCAGCCATAACTTTGACACAAGCTGGGGCCTATCATTGCCAAGCCCAGGCCCCAGGCTCAGCCACCACGAGCCTAGCTGCACCCATCAGCCTCCACGTGTCCTATGCCCCACGCCACGTCACACTCACTACCCTGATGGACACAGGCCCTGGACGACTGGGCCTCCTCCTGTGCCGTGTGGACAGTGACCCTCCGGCCCAGCTGCGGCTGCTCCACGGGGATCGCCTTGTGGCCTCCACCCTACAAGGTGTGGGGGGACCCGAAGGCAGCTCTCCCAGGCTGCATGTGGCTGTGGCCCCCAACACACTGCGTCTGGAGATCCACGGGGCTATGCTGGAGGATGAGGGTGTCTATATCTGTGAGGCCTCCAACACCCTGGGCCAGGCCTCGGCCTCAGCTGACTTCGACGCTCAAGCTGTGAATGTGCAGGTGTGGCCCGGGGCTACCGTGCGGGAGGGGCAGCTGGTGAACCTGACCTGCCTTGTGTGGACCACTCACCCGGCCCAGCTCACCTACACATGGTACCAGGATGGGCAGCAGCGCCTGGATGCCCACTCCATCCCCCTGCCCAACGTCACAGTCAGGGATGCCACCTCCTACCGCTGCGGTGTGGGCCCCCCTGGTCGGGCACCCCGCCTCTCCAGACCTATCACCTTGGACGTCCTCTACGCGCCCCGCAACCTGCGCCTGACCTACCTCCTGGAGAGCCATGGCGGGCAGCTGGCCCTGGTACTGTGCACTGTGGACAGCCGCCCGCCCGCCCAGCTGGCCCTCAGCCACGCCGGTCGCCTCTTGGCCTCCTCGACAGCAGCCTCTGTCCCCAACACCCTGCGCCTGGAGCTGCGAGGGCCACAGCCCAGGGATGAGGGTTTCTACAGCTGCTCTGCCCGCAGCCCTCTGGGCCAGGCCAACACGTCCCTGGAGCTGCGGCTGGAGGGTGTGCGGGTGATCCTGGCTCCGGAGGCTGCCGTGCCTGAAGGTGCCCCCATCACAGTGACCTGTGCGGACCCTGCTGCCCACGCACCCACACTCTATACTTGGTACCACAACGGTCGTTGGCTGCAGGAGGGTCCAGCTGCCTCACTCTCATTCCTGGTGGCCACGCGGGCTCATGCAGGCGCCTACTCTTGCCAGGCCCAGGATGCCCAGGGCACCCGCAGCTCCCGTCCTGCTGCCCTGCAAGTCCTCTATGCCCCTCAGGACGCTGTCCTGTCCTCCTTCCGGGACTCCAGGGCCAGATCCATGGCTGTGATACAGTGCACTGTGGACAGTGAGCCACCTGCTGAGCTGGCCCTATCTCATGATGGCAAGGTGCTGGCCACGAGCAGCGGGGTCCACAGCTTGGCATCAGGGACAGGCCATGTCCAGGTGGCCCGAAACGCCCTACGGCTGCAGGTGCAAGATGTGCCTGCAGGTGATGACACCTATGTTTGCACAGCCCAAAACTTGCTGGGCTCAATCAGCACCATCGGGCGGTTGCAGGTAGAAGGTGCACGCGTGGTGGCAGAGCCTGGCCTGGACGTGCCTGAGGGCGCTGCCCTGAACCTCAGCTGCCGCCTCCTGGGTGGCCCTGGGCCTGTGGGCAACTCCACCTTTGCATGGTTCTGGAATGACCGGCGGCTGCACGCGGAGCCTGTGCCCACTCTCGCCTTCACCCACGTGGCTCGTGCTCAAGCTGGGATGTACCACTGCCTGGCTGAGCTCCCCACTGGGGCTGCTGCCTCTGCTCCAGTCATGCTCCGTGTGCTCTACCCTCCCAAGACGCCCACCATGATGGTCTTCGTGGAGCCTGAGGGTGGCCTCCGGGGCATCCTGGATTGCCGAGTGGACAGCGAGCCGCTCGCCAGCCTGACTCTCCACCTTGGCAGTCGACTGGTGGCCTCCAGTCAGCCCCAGGGTGCTCCTGCAGAGCCACACATCCATGTCCTGGCTTCCCCCAATGCCCTGAGGGTGGACATCGAGGCGCTGAGGCCCAGCGACCAAGGGGAATACATCTGTTCTGCCTCAAATGTCCTGGGCTCTGCCTCTACCTCCACCTACTTTGGGGTCAGAGCCCTGCACCGCCTGCATCAGTTCCAGCAGCTGCTCTGGGTCCTGGGACTGCTGGTGGGCCTCCTGCTCCTGCTGTTGGGCCTGGGGGCCTGCTACACCTGGAGAAGGAGGCGTGTTTGTAAGCAGAGCATGGGCGAGAATTCGGTGGAGATGGCTTTTCAGAAAGAGACCACGCAGCTCATTGATCCTGATGCAGCCACATGTGAGACCTCAACCTGTGCCCCACCCCTGGGCTGA-3'
By using this site you agree to our privacy policy.
Please confirm you agree with the privacy policy before using the site.